Downloaded 83 times














![Join engine15SELECT a.* FROM [nt:unstructured] AS a JOIN [nt:unstructured] AS b <PersistenceManager class=“…"> <paramname="bundleCacheSize" value="8"/> </PersistenceManager></Workspace>](https://image.slidesharecdn.com/repositoryperformancetuning-110916072621-phpapp02/85/Repository-performance-tuning-15-320.jpg)

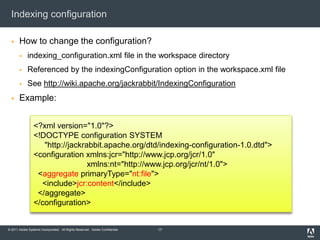


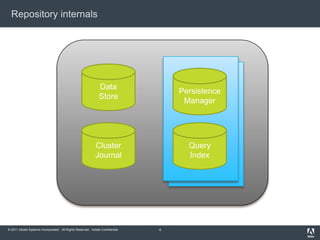
This document provides an overview of performance tuning for a content repository. It discusses identifying performance issues, investigating potential causes related to hardware, the repository, applications or clients. Possible solutions include changing content, configuration, code or upgrading hardware. The document also summarizes key aspects of the repository internals like the data store, persistence manager, query index and clustering. Specific tips are provided for basic content access, batch processing and query performance.