Downloaded 317 times






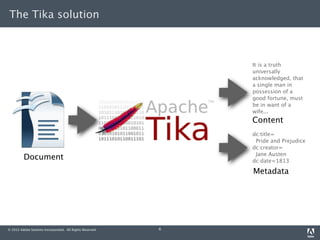















The document discusses content extraction with Apache Tika. It introduces Tika and describes how it can be used to extract full text and metadata from various file formats. It also discusses using Tika with Solr and Lucene, including feeding parsed content directly into a Lucene index and using the ExtractingRequestHandler with Solr. Special considerations for large documents and link extraction are also covered.
































































