Downloaded 187 times

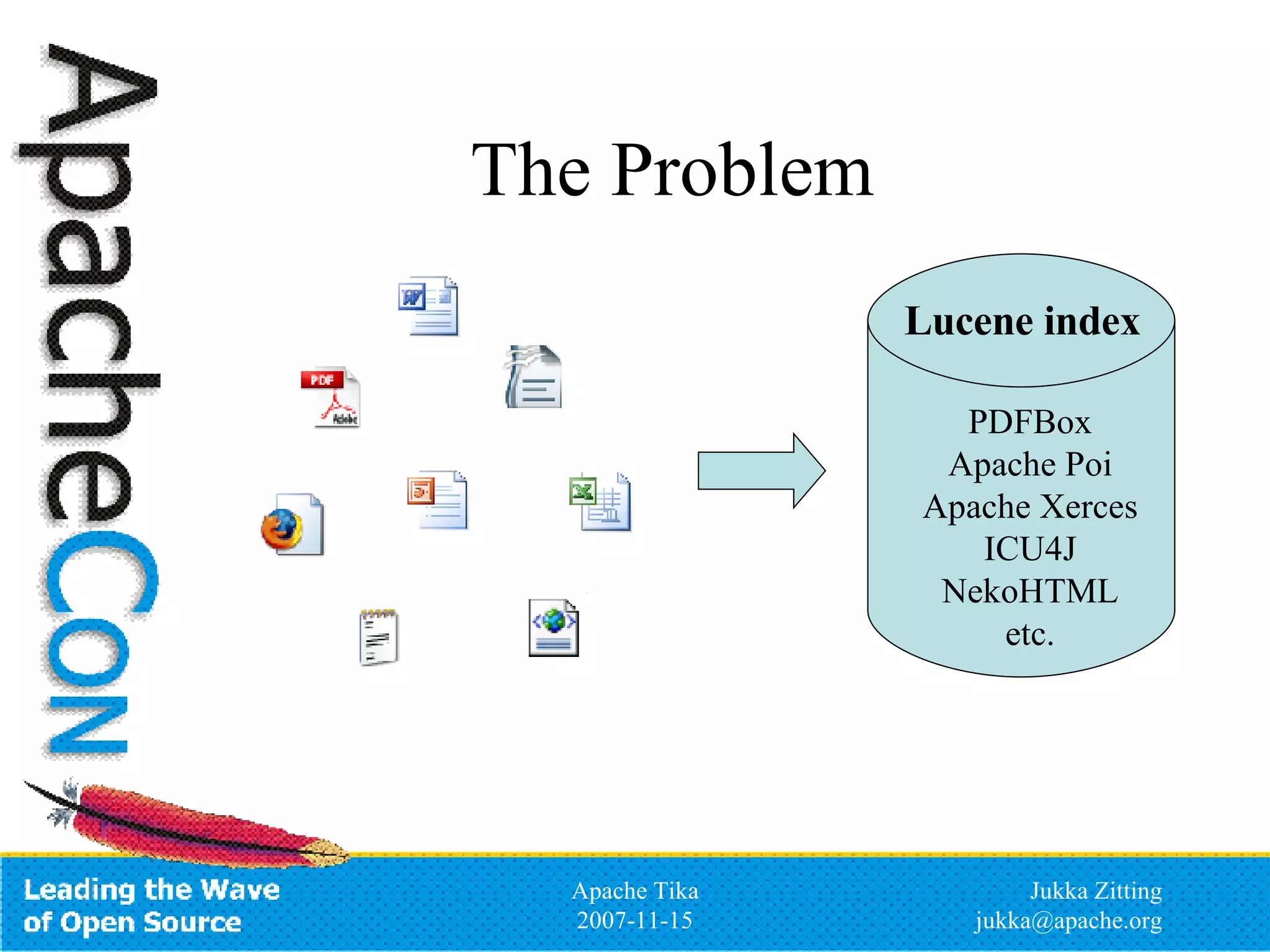
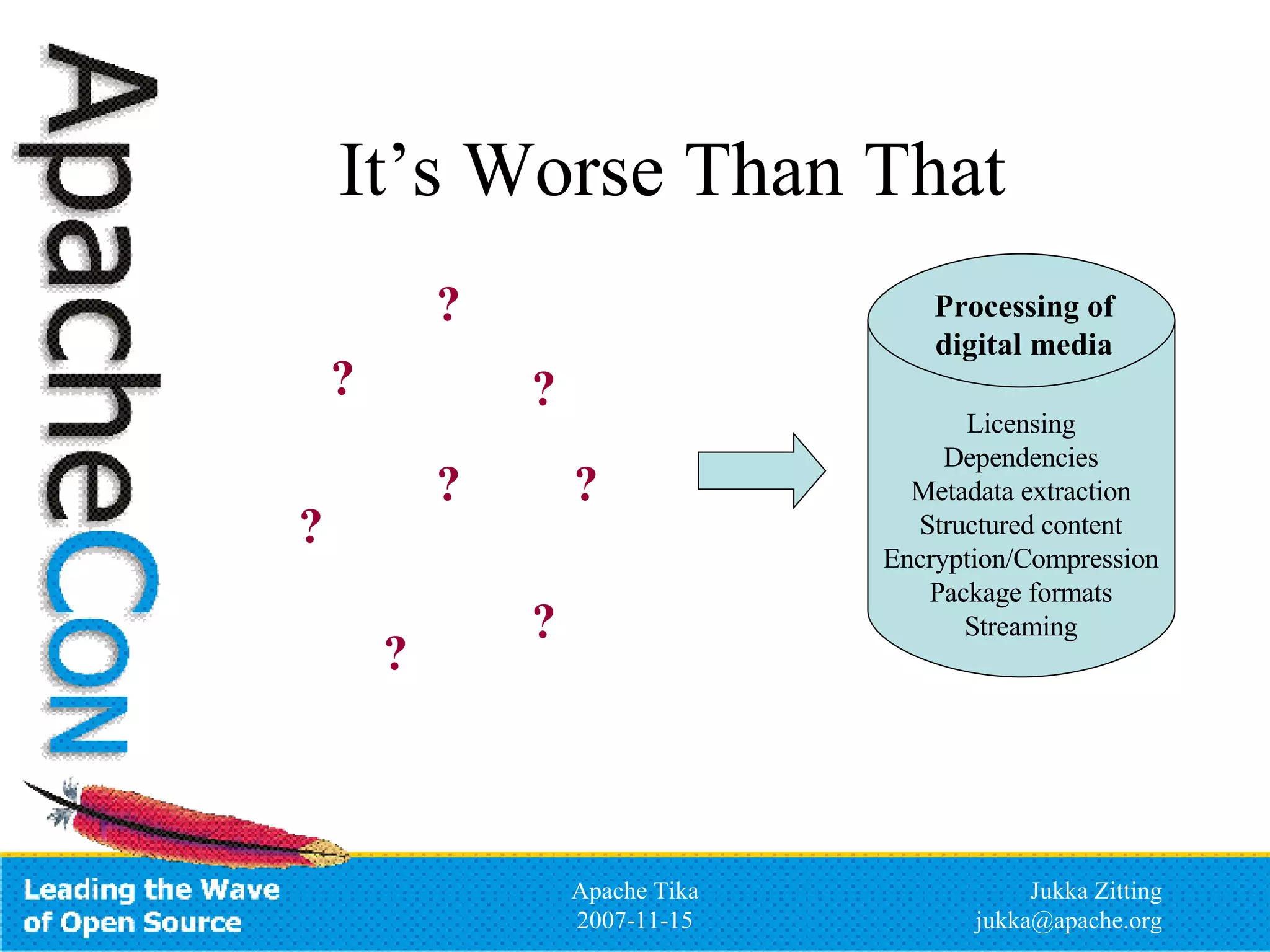




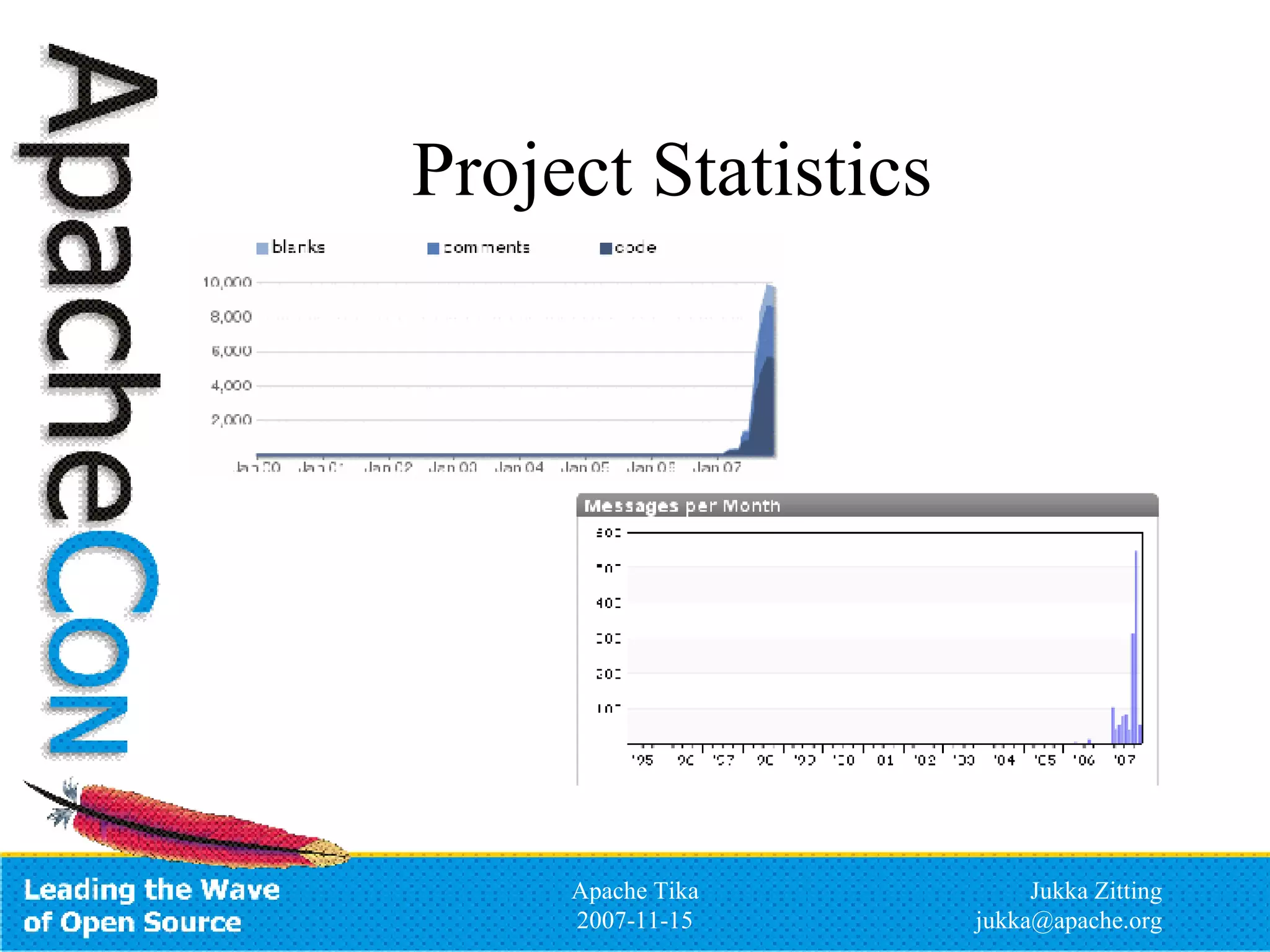
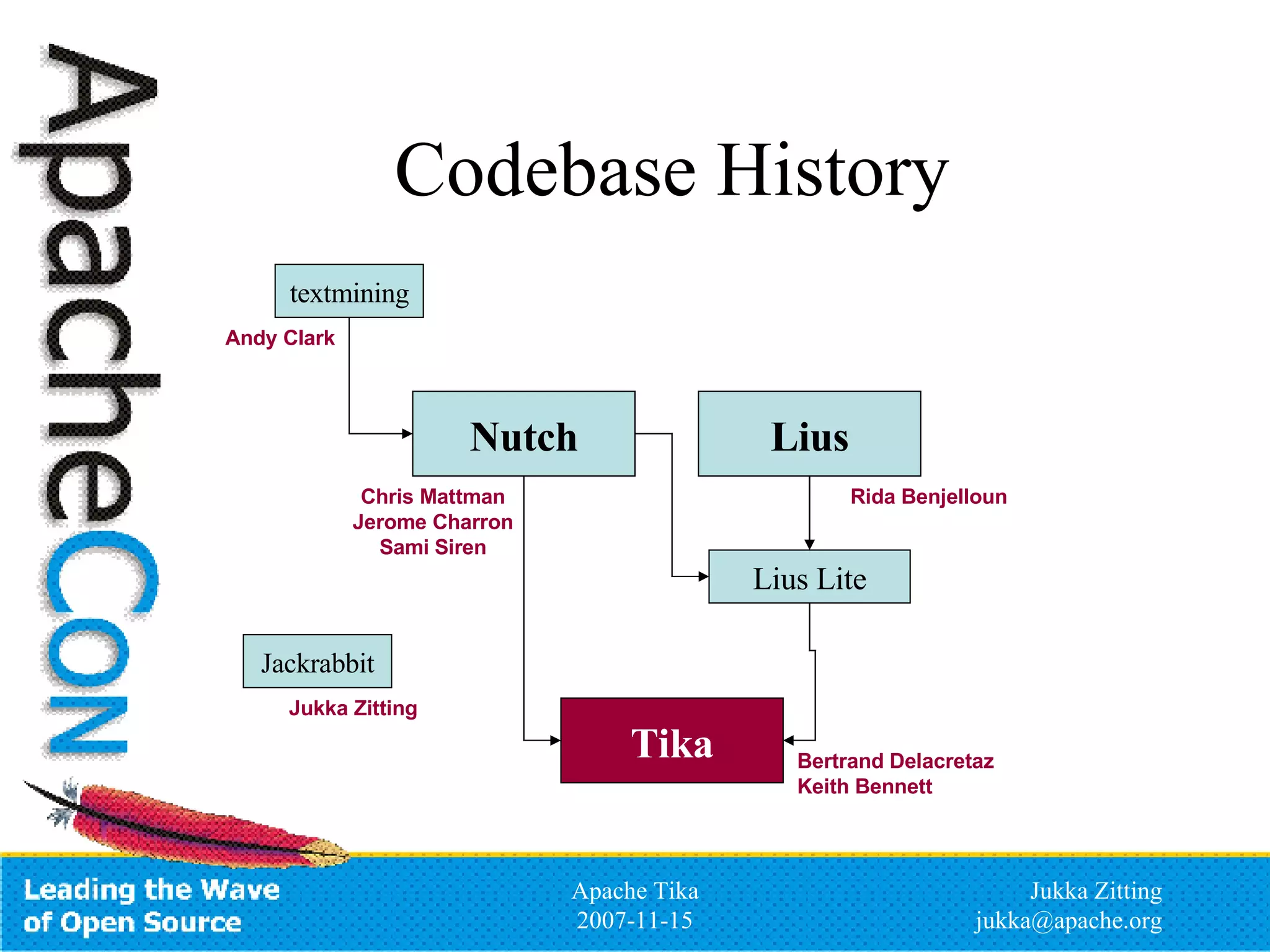

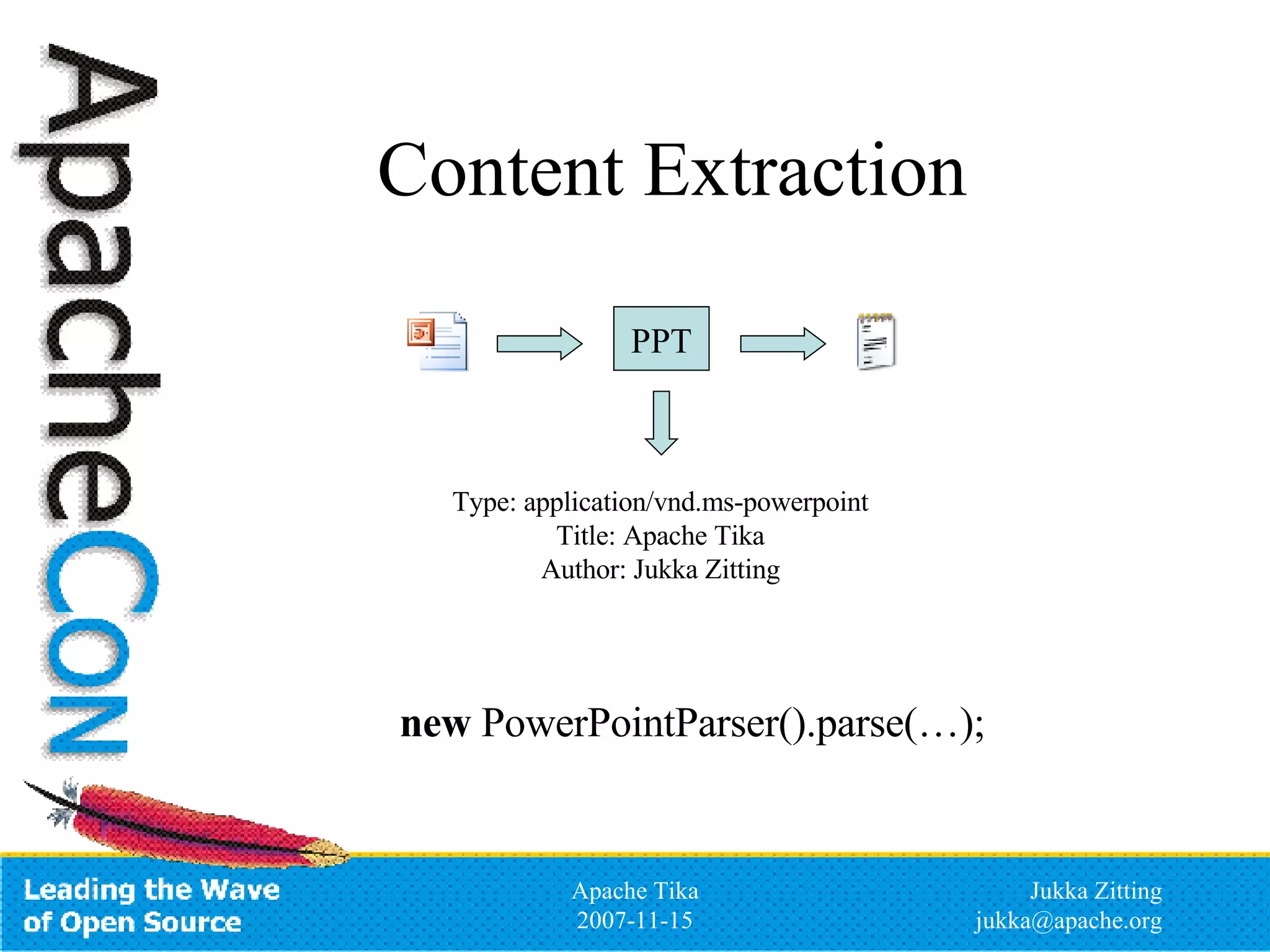



Apache Tika is an open source toolkit for detecting and extracting metadata and structured text content from various file types. It provides a common API for integrating multiple parsing libraries and can automatically detect file types. The project is incubating under the Apache Lucene PMC and aims to support parsing of formats like PDF, Microsoft Office files, HTML, XML and more to extract metadata and content that can be indexed by search engines like Lucene.























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















