Download to read offline


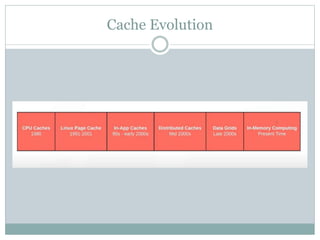
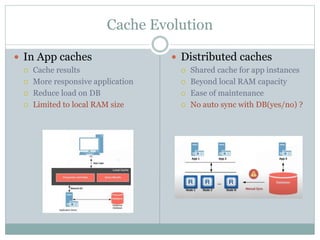
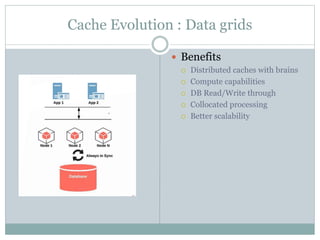
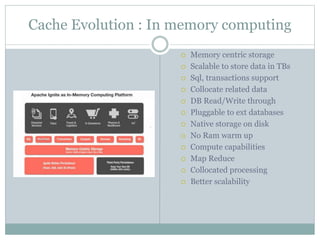







![Eviction Policies
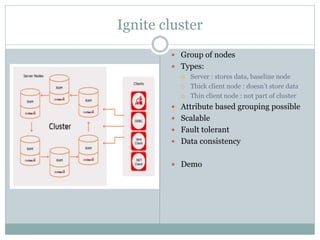
On Heap [cache level]
LRU : Recommended when in doubt
FIFO : It ignores the element access order
Sorted : Sorted according to key for order
Off Heap [data region level]
Random LRU:
Random-2 LRU
Persistence On [Page replacement]
Random-LRU
Segmented-LRU
Clock](https://image.slidesharecdn.com/apacheignite-220311152205/85/Apache-ignite-as-in-memory-computing-platform-20-320.jpg)



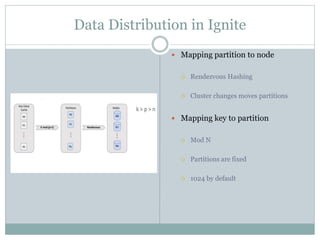

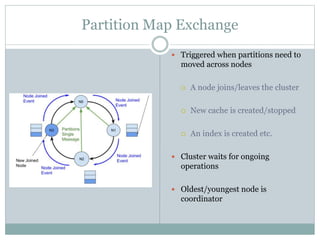
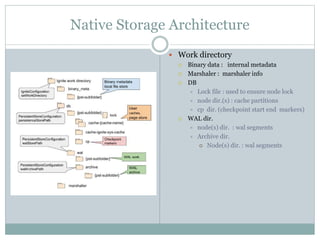
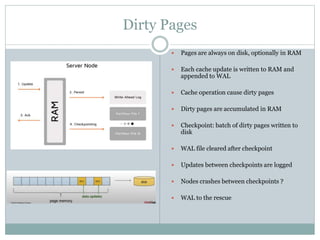
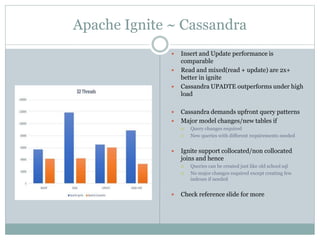




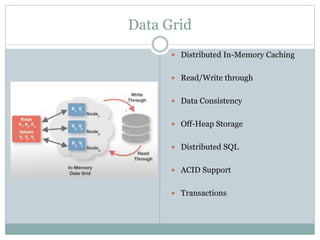
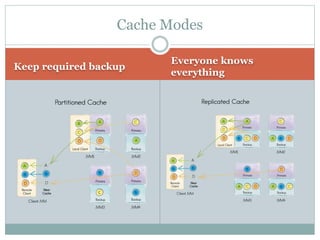
The document provides an overview of Apache Ignite, focusing on its capabilities as a distributed in-memory data grid and cache, highlighting its advantages in performance and scalability. Key features discussed include data partitioning, eviction policies, compute tasks, and different query types, alongside a comparison with other technologies like Cassandra. Several best practices and future steps for further exploration of Apache Ignite are also outlined.



































































