Downloaded 201 times











![©2011 Oracle Corporation Coherence Cache Types / Strategies Replicated Cache Optimistic Cache Partitioned Cache Near Cache backed by partitioned cache LocalCache not clustered Topology Replicated Replicated Partitioned Cache Local Caches + Partitioned Cache Local Cache Read Performance Instant Instant Locally cached: instant --Remote: network speed Locally cached: instant -- Remote: network speed Instant Fault Tolerance Extremely High Extremely High Configurable Zero to Extremely High Configurable 4 Zero to Extremely High Zero Write Performance Fast Fast Extremely fast Extremely fast Instant Memory Usage (Per JVM) DataSize DataSize DataSize/JVMs x Redundancy LocalCache + [DataSize / JVMs] DataSize Coherency fully coherent fully coherent fully coherent fully coherent n/a Memory Usage (Total) JVMs x DataSize JVMs x DataSize Redundancy x DataSize [Redundancy x DataSize] + [JVMs x LocalCache] n/a Locking fully transactional none fully transactional fully transactional fully transactional Typical Uses Metadata n/a (see Near Cache) Read-write caches Read-heavy caches w/ access affinity Local data](https://image.slidesharecdn.com/introtocoherence-111011122858-phpapp01/85/An-Engineer-s-Intro-to-Oracle-Coherence-16-320.jpg)

















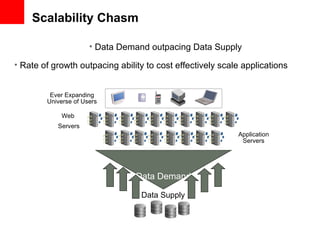
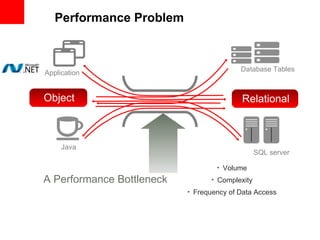
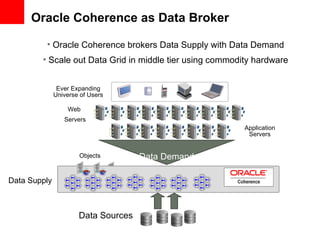
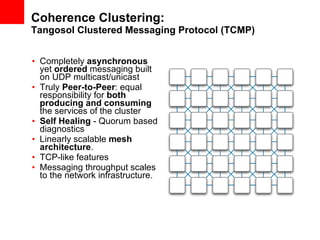
This document provides an overview of Oracle Coherence, an in-memory data grid. It discusses what a data grid is and how Coherence works, including clustering, caching, querying, and aggregating data. It also provides examples of how Coherence can be used and customer use cases, such as for user session management across brands.










































![JavaOne2016 - Microservices: Terabytes in Microseconds [CON4516]](https://cdn.slidesharecdn.com/ss_thumbnails/javaone2016microservicesfinal-160922165618-thumbnail.jpg?width=640&height=640&fit=bounds)
![JavaOne2016 - Microservices: Terabytes in Microseconds [CON4516]](https://cdn.slidesharecdn.com/ss_thumbnails/javaone2016microservicesfinal-160922163749-thumbnail.jpg?width=640&height=640&fit=bounds)























