Downloaded 70 times











![Example: Text extraction public static void main(String[] args) throws Exception { InputStream stream = System.in; ContentHandler handler = new WriteOutContentHandler( System.out ); Metadata metadata = new Metadata(); new AutoDetectParser().parse( stream , handler , metadata ); }](https://image.slidesharecdn.com/mime-magic-with-apache-tika-1208196771876741-8/85/Mime-Magic-With-Apache-Tika-14-320.jpg)


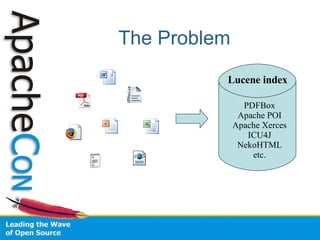
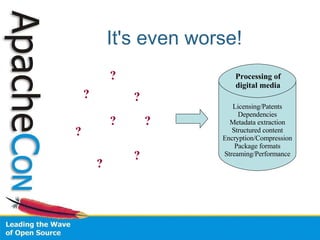
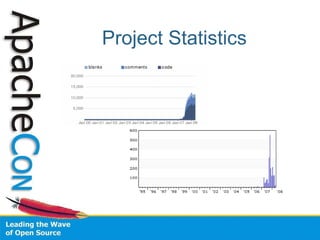
Tika is an open source project that provides a generic API for extracting metadata and structured text content from various document formats. It uses automatic content type detection to parse documents without needing to know the file type in advance. The project aims to pool efforts across various Apache projects like Apache POI and Apache PDFBox to provide a common solution for parsing different file types.































































































