Download as PDF, PPTX



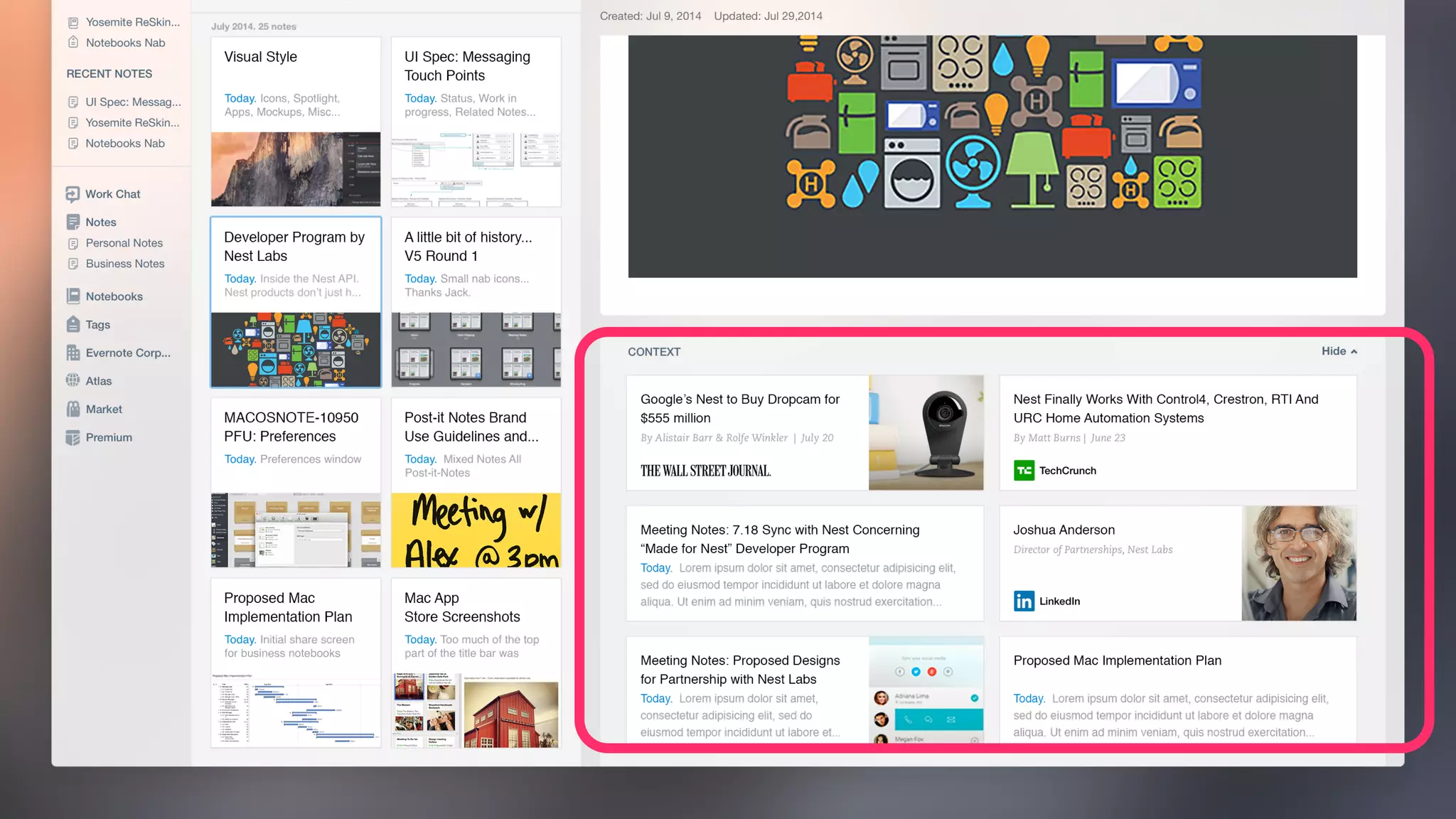







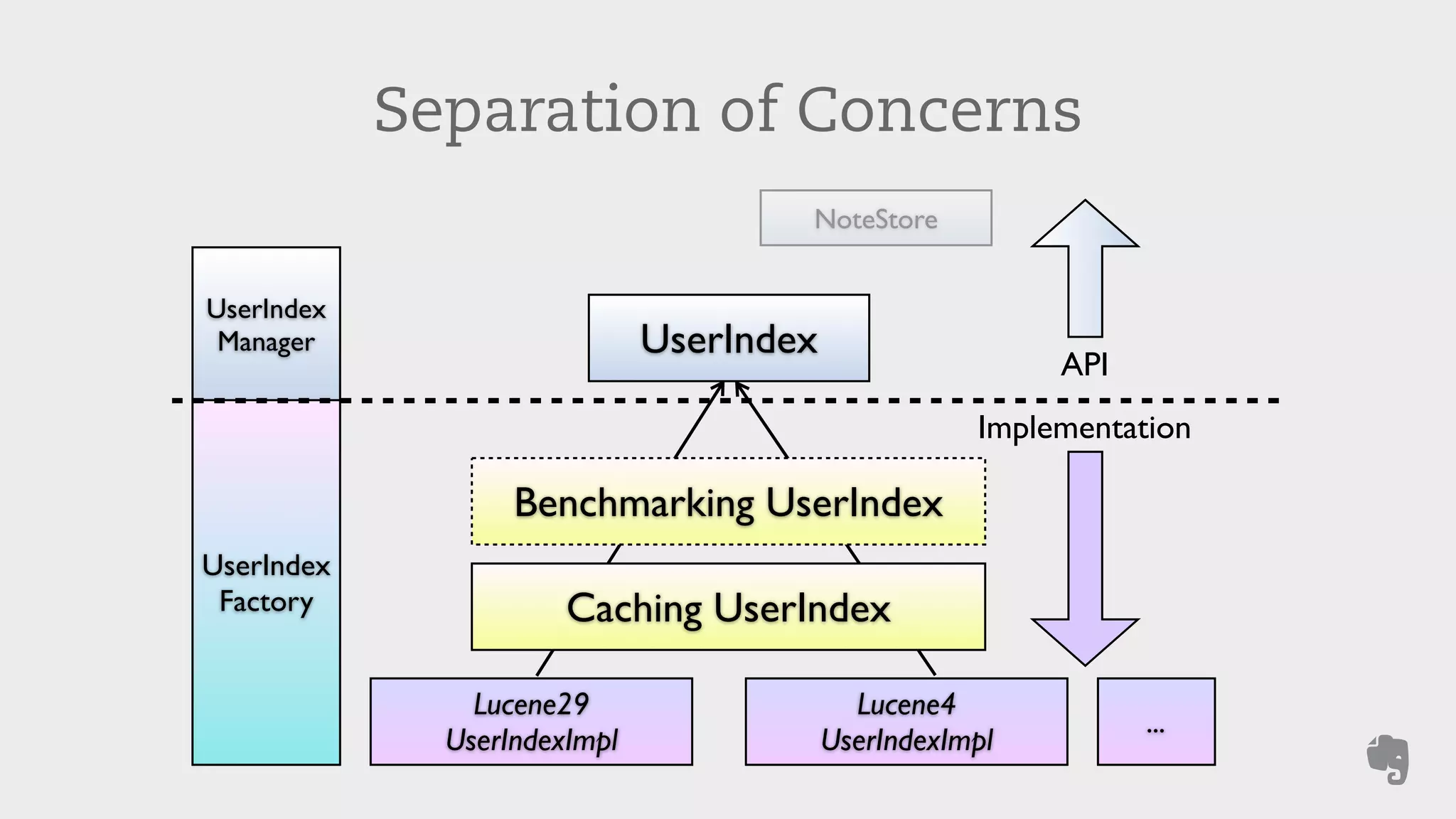


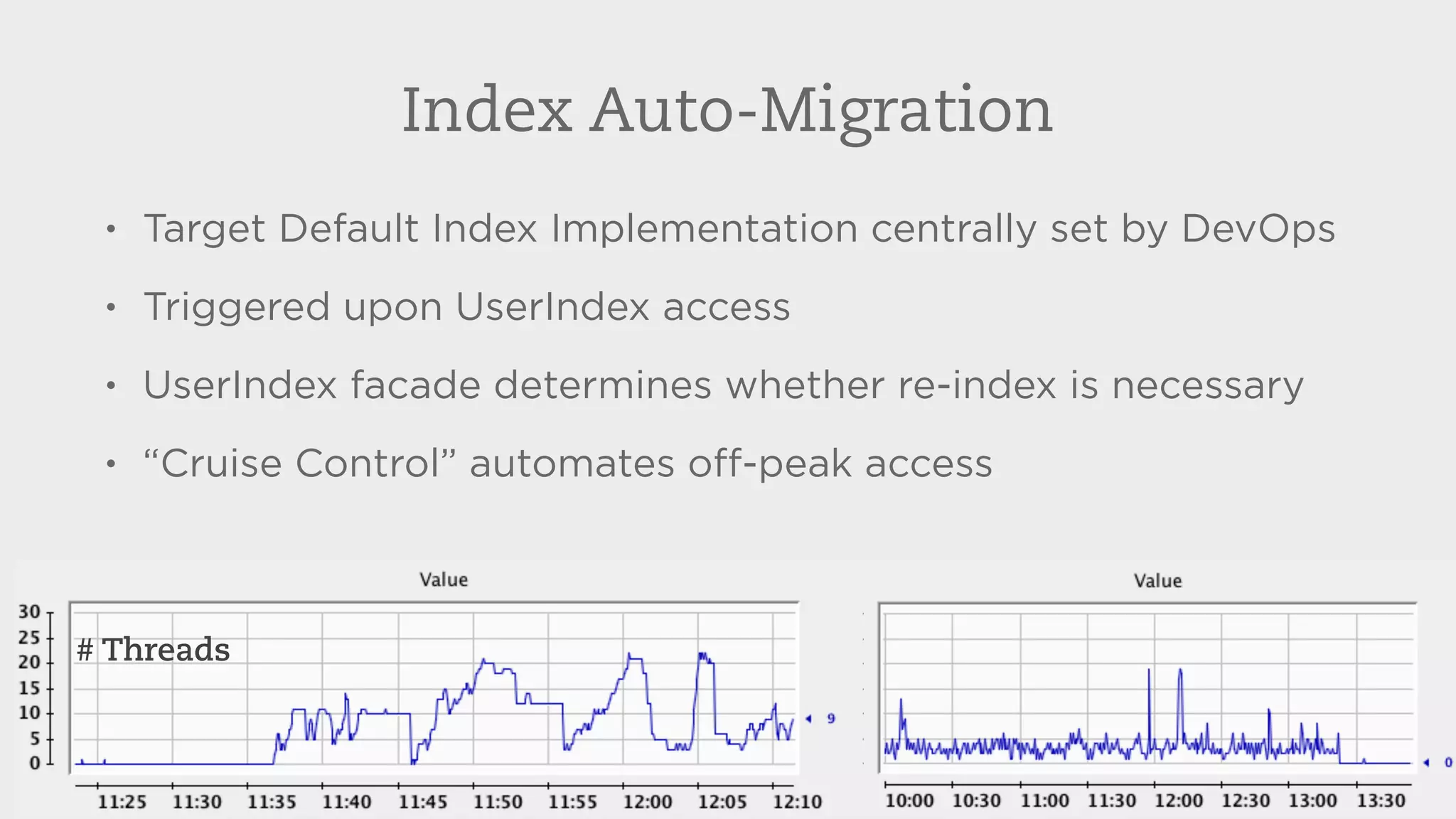
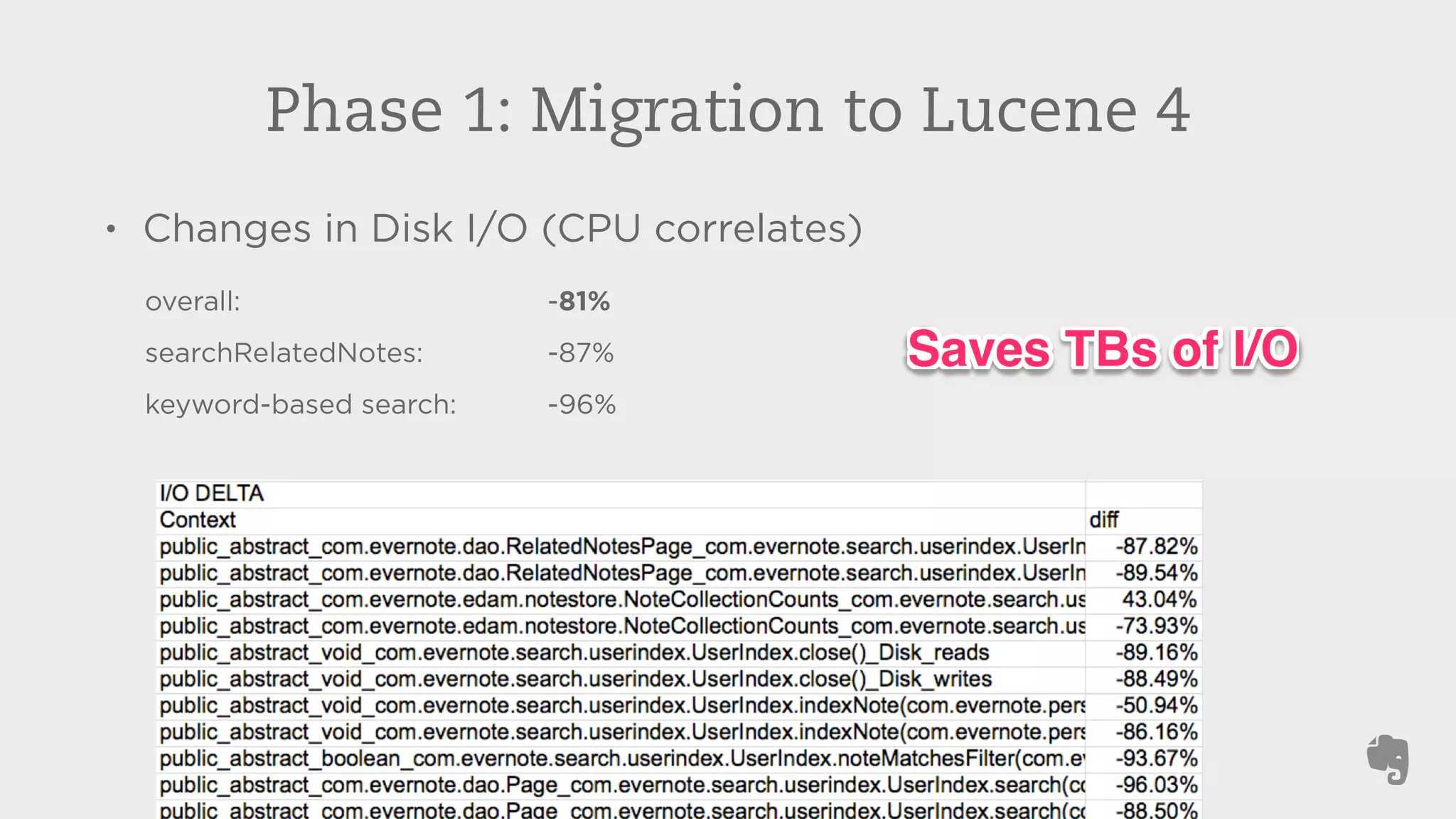



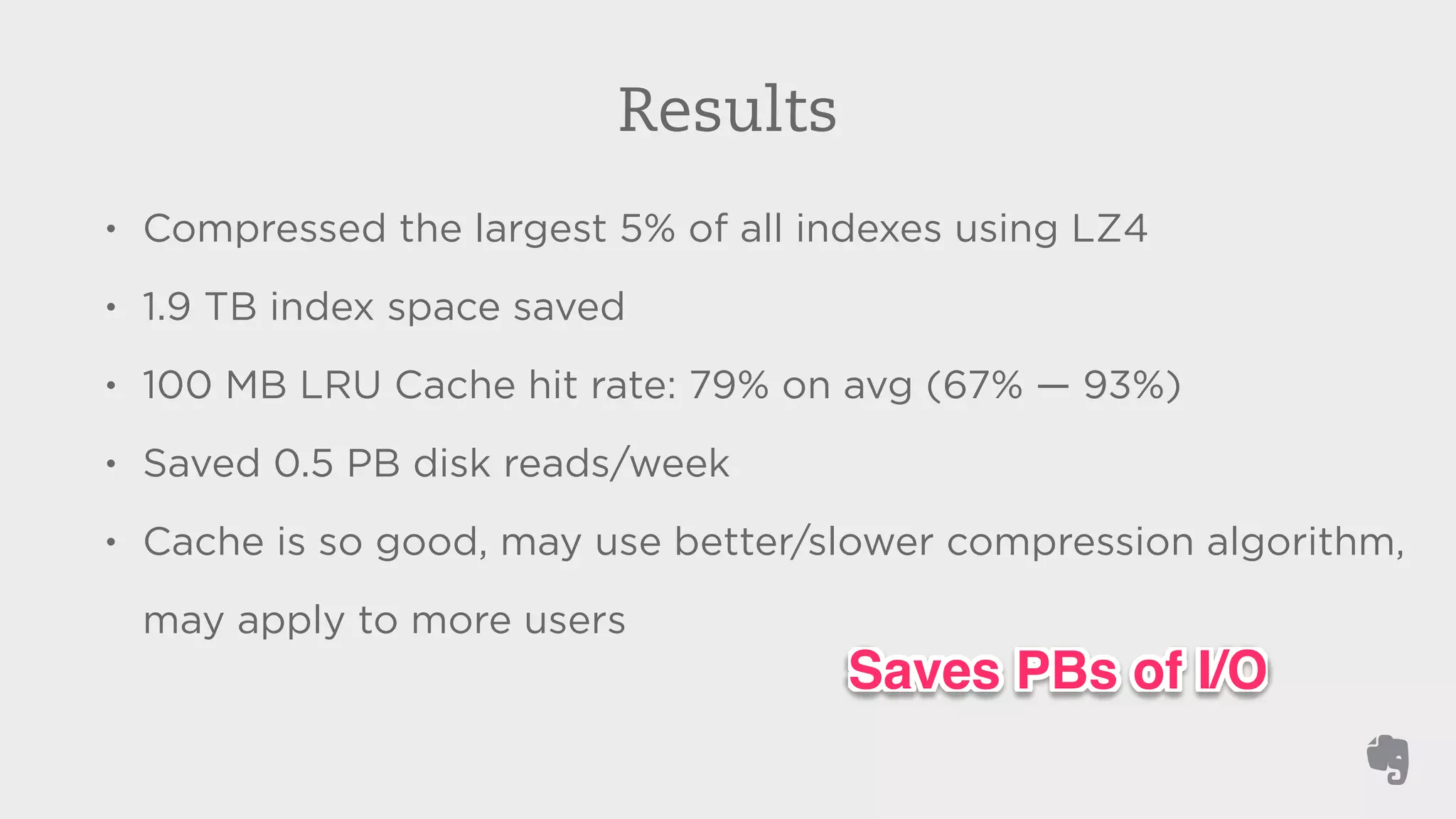





Evernote stores over 3 billion notes from over 100 million users worldwide. To improve search performance and allow upgrades to newer Lucene versions, Evernote rearchitected their search system. They separated search code from the data storage, allowed multiple Lucene versions to run concurrently on each machine, and automatically migrated each user's index to the default version without downtime. This reduced disk I/O by 81% and allowed compression techniques to further reduce storage needs by terabytes and input/output by petabytes each week.










































































![[Webinar] Intelligent Policing. Leveraging Data to more effectively Serve Com...](https://cdn.slidesharecdn.com/ss_thumbnails/insightdrivenpolicingv2-201027222903-thumbnail.jpg?width=640&height=640&fit=bounds)































