Downloaded 70 times



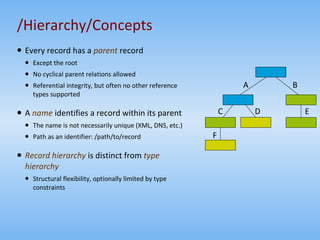















The document summarizes the return of hierarchical data models and provides examples. It discusses the benefits of hierarchies, including their natural representation of data and efficient querying. It also notes limitations, such as limited reference support and challenges organizing information. The document then examines several hierarchical systems like filesystems, DNS, LDAP, XML and databases. It presents a case study on JCR and Jackrabbit, which implement a content repository standard. Lessons learned emphasize content-driven development and distributing systems for redundancy and scalability.



























































































