Downloaded 278 times













![Mislevy, R. (2004). Can there be reliability without reliability? Journal of Educational
and Behavioral Statistics, 29, 241-244.
Moss, P. A. (1994). Can there be validity without reliability? Educational Researcher,
23, 5-12.
Osterlind, S. J. (1983). Test item bias. Newbury Park: Sage Publications.
Parkes, J. (2000). The relationship between the reliability and cost of performance
assessments. Education Policy Analysis Archives, 8. [On-line] Available
URL: http://epaa.asu.edu/epaa/v8n16/
Pedhazur, E. J.; & Schmelkin, L. P. (1991). Measurement, design, and analysis: An
integrated approach.Hillsdale, NJ: Lawrence Erlbaum Associates, Publishers.
Polkinghorne, D. E. (1988). Narrative knowing and the human sciences. Albany: State
University of New York Press.
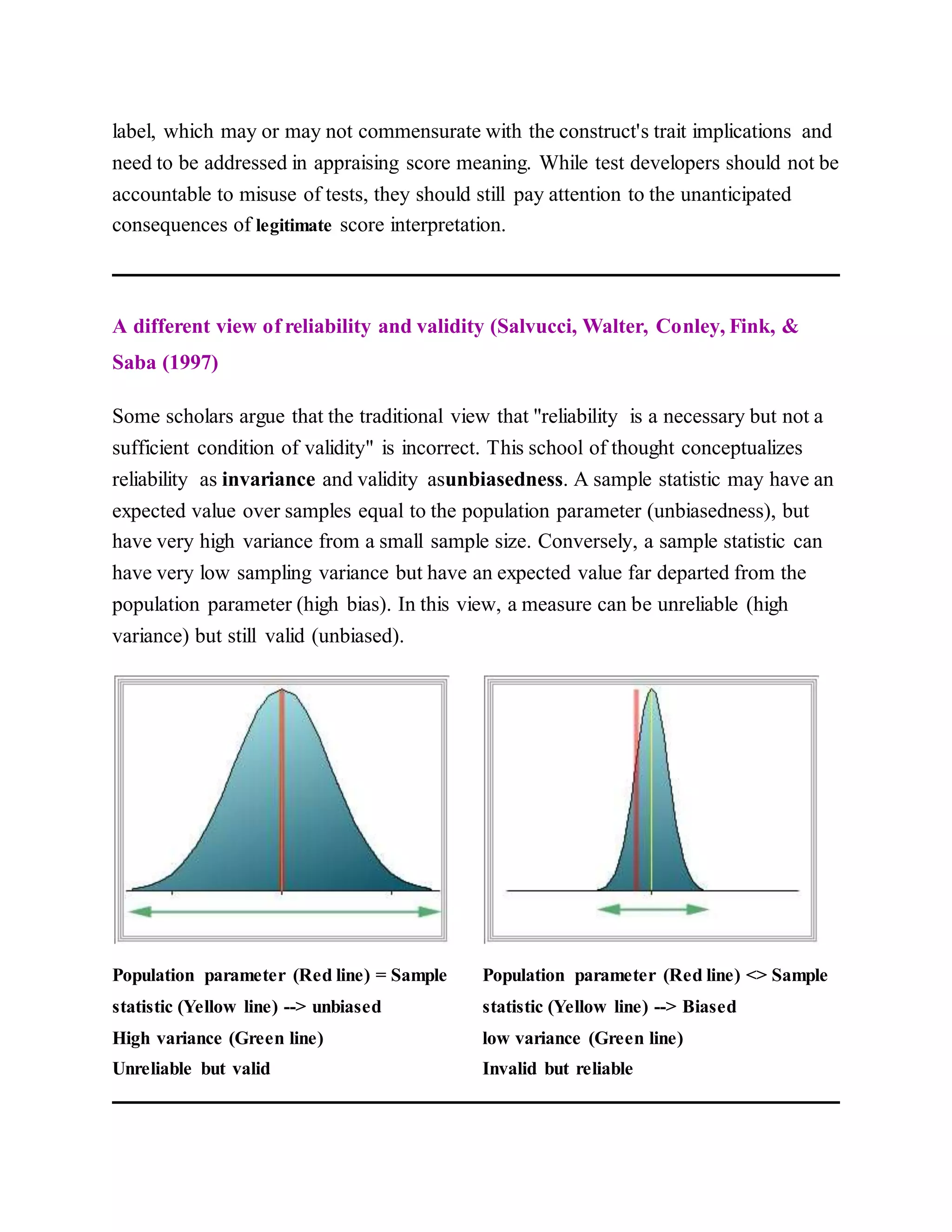
Salvucci, S.; Walter, E., Conley, V; Fink, S; & Saba, M. (1997). Measurement error
studies at the National Center for Education Statistics. Washington D. C.: U. S.
Department of Education
Thompson, B. (Ed.) (2003). Score reliability: Contemporary thinking on reliability
issues. Thousand Oaks: Sage.
Yu, C. H. (2005). Test-retest reliability. In K. Kempf-Leonard (Ed.). Encyclopedia of
Social Measurement, Vol. 3 (pp. 777-784). San Diego, CA: Academic Press.
Questions for discussion
Pick one of the following cases and determine whether the test or the assessment is
valid. Apply the concepts of reliability and validity to the situation. These cases may
be remote to this cultural context. You may use your own example.](https://image.slidesharecdn.com/reliabilityandvalidity-120130222100-phpapp01/75/Reliability-and-validity-15-2048.jpg)


- Reliability refers to the consistency of test scores, and there are several types including test-retest reliability, alternate forms reliability, and internal consistency reliability. - Validity refers to how well a test measures what it intends to measure. There are several types of validity including content validity, criterion validity, and construct validity. - Reliability is a necessary but not sufficient condition for validity - a test can consistently measure something incorrectly. Validity ensures a test accurately measures the intended construct.













































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











