This document discusses database concepts including:
1) Atomic and non-atomic domains, and how non-atomic values complicate data storage and encourage data redundancy.
2) Functional dependencies, which constrain the set of legal relations by requiring that values for one set of attributes determine values for another set.
3) Third normal form, which places constraints on attribute dependencies to reduce data redundancy.
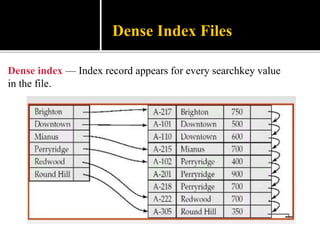
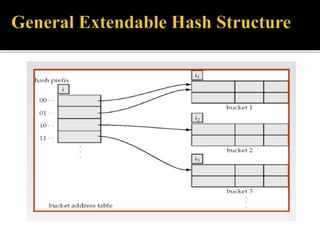
4) Indexing mechanisms used to speed up data access by mapping search keys to file attributes.