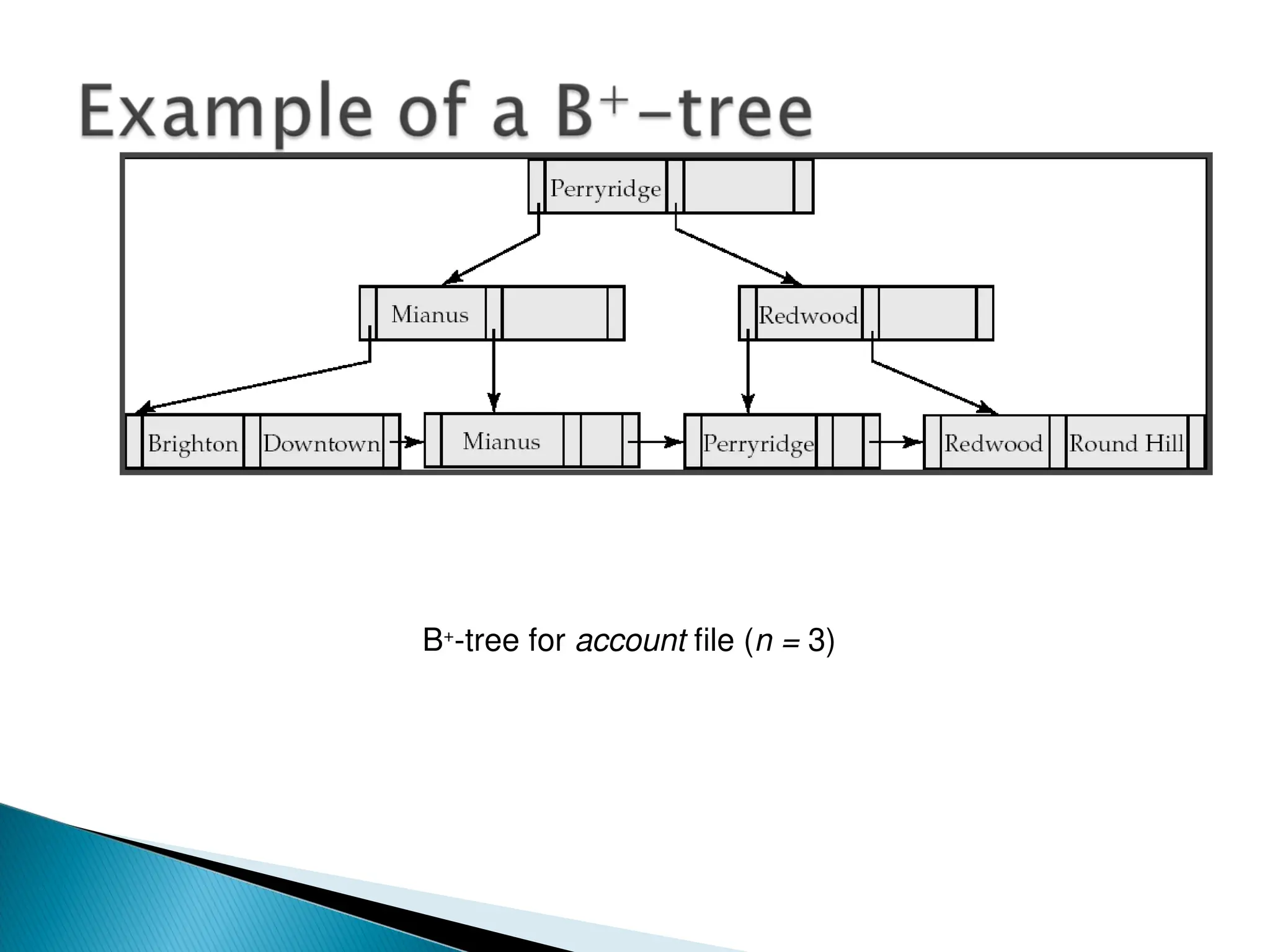
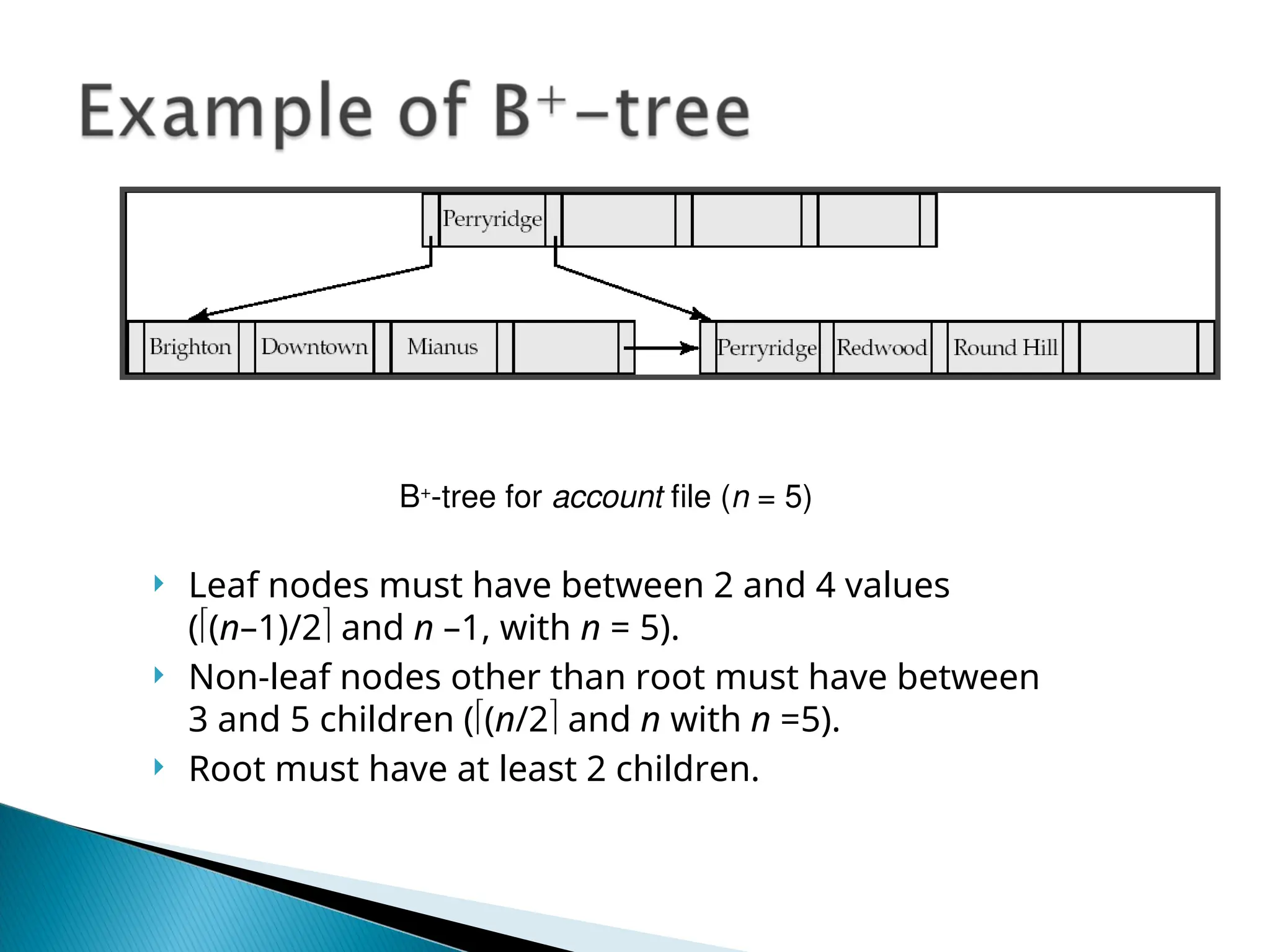
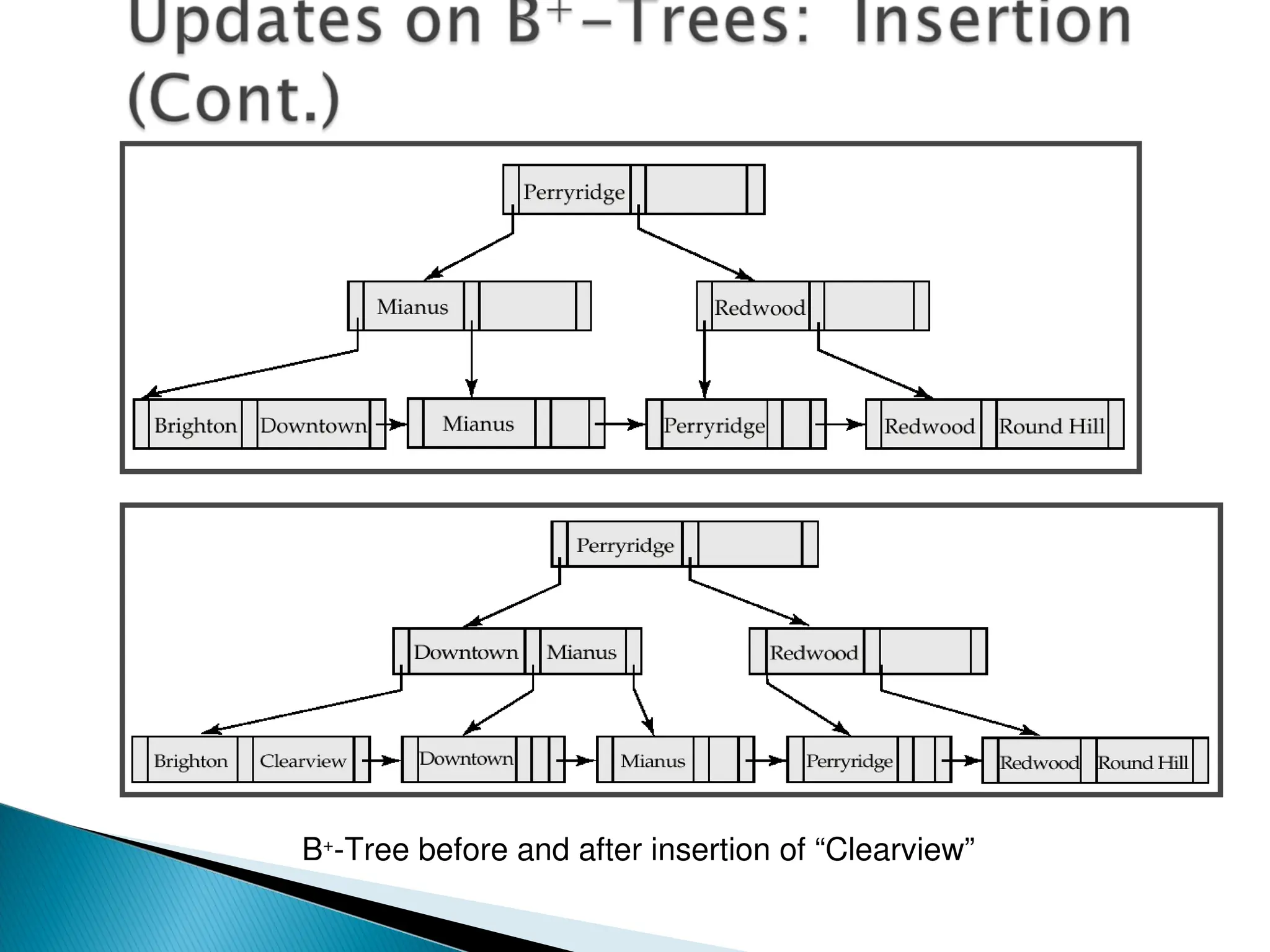
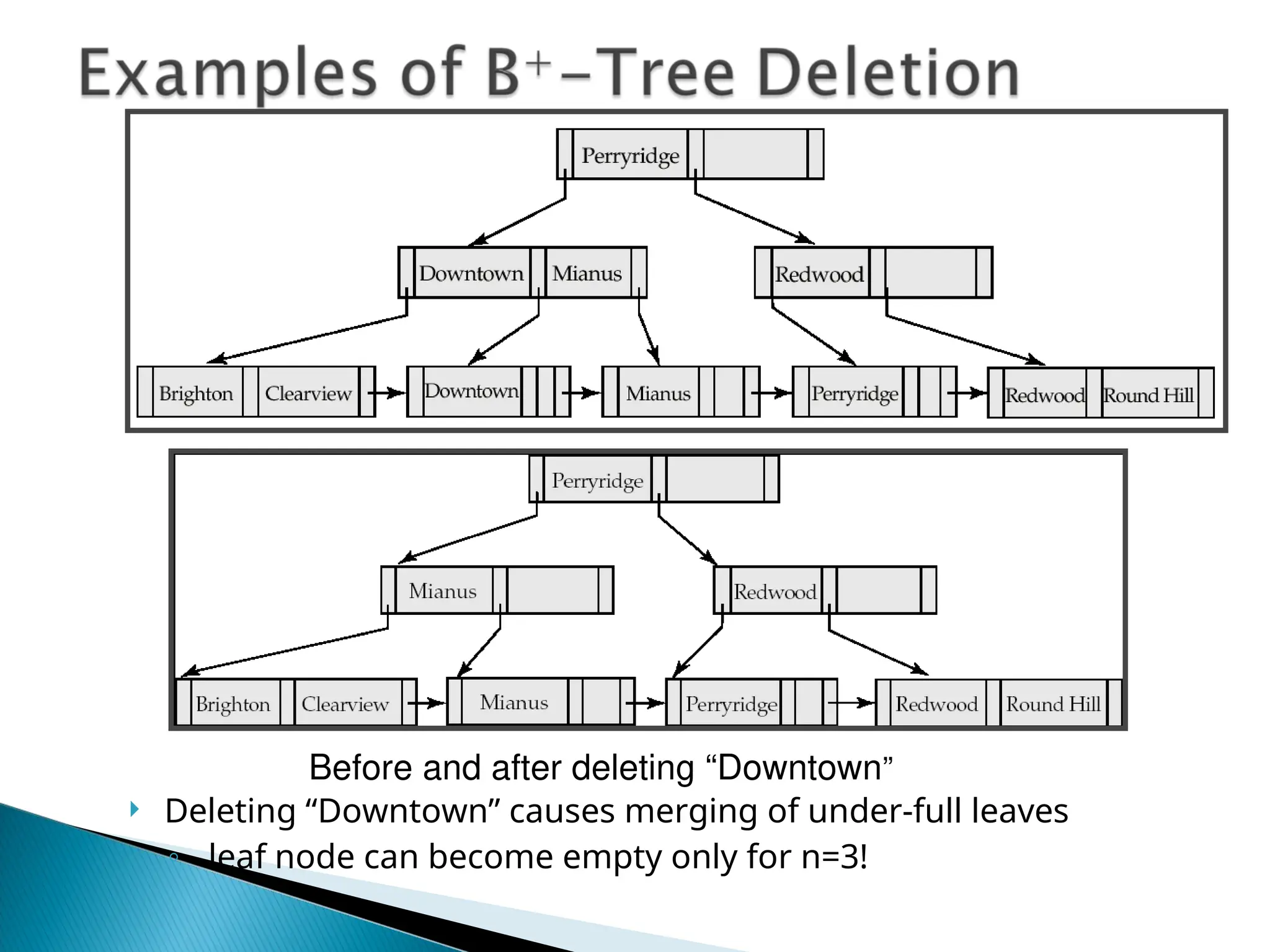
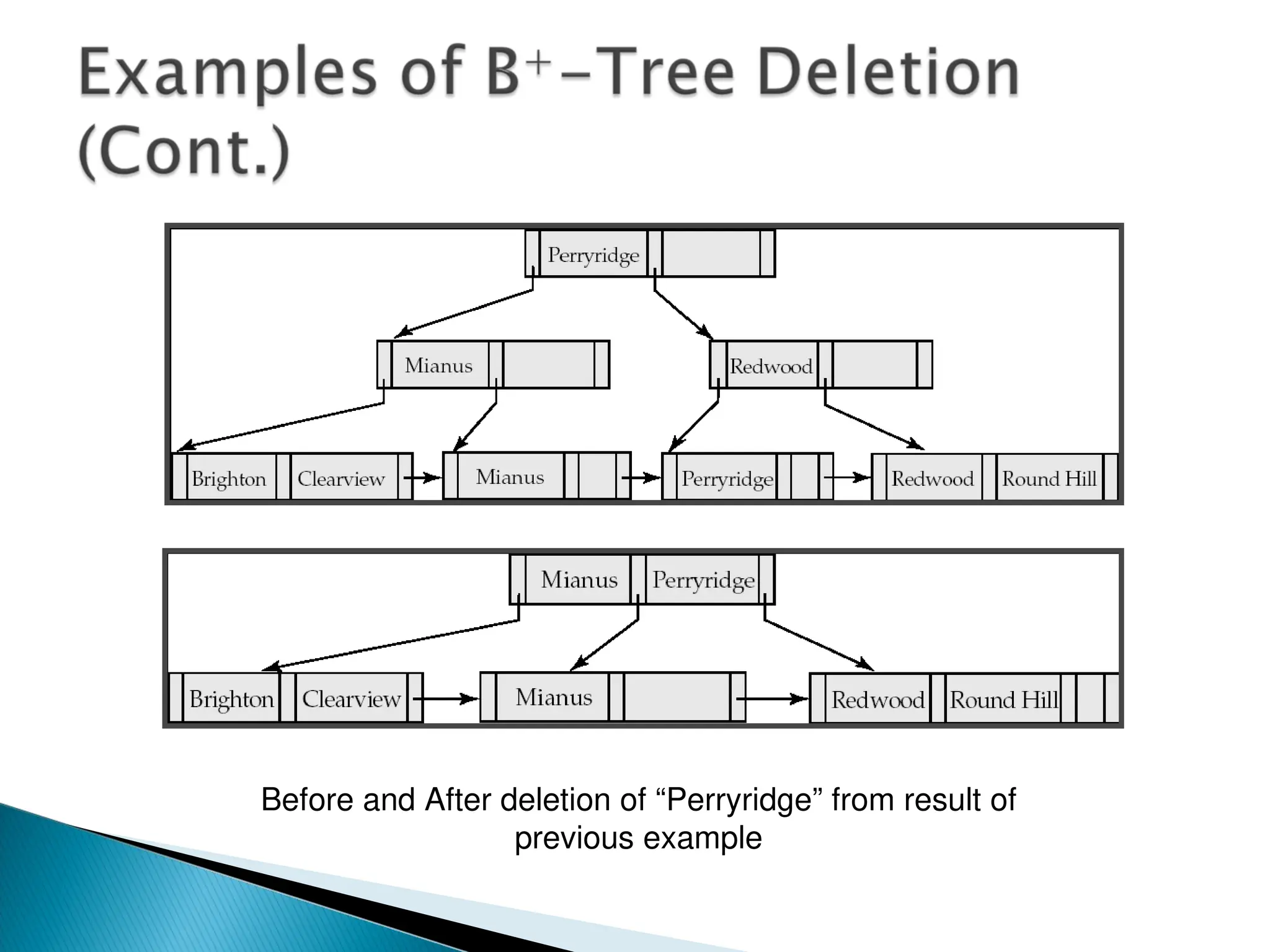
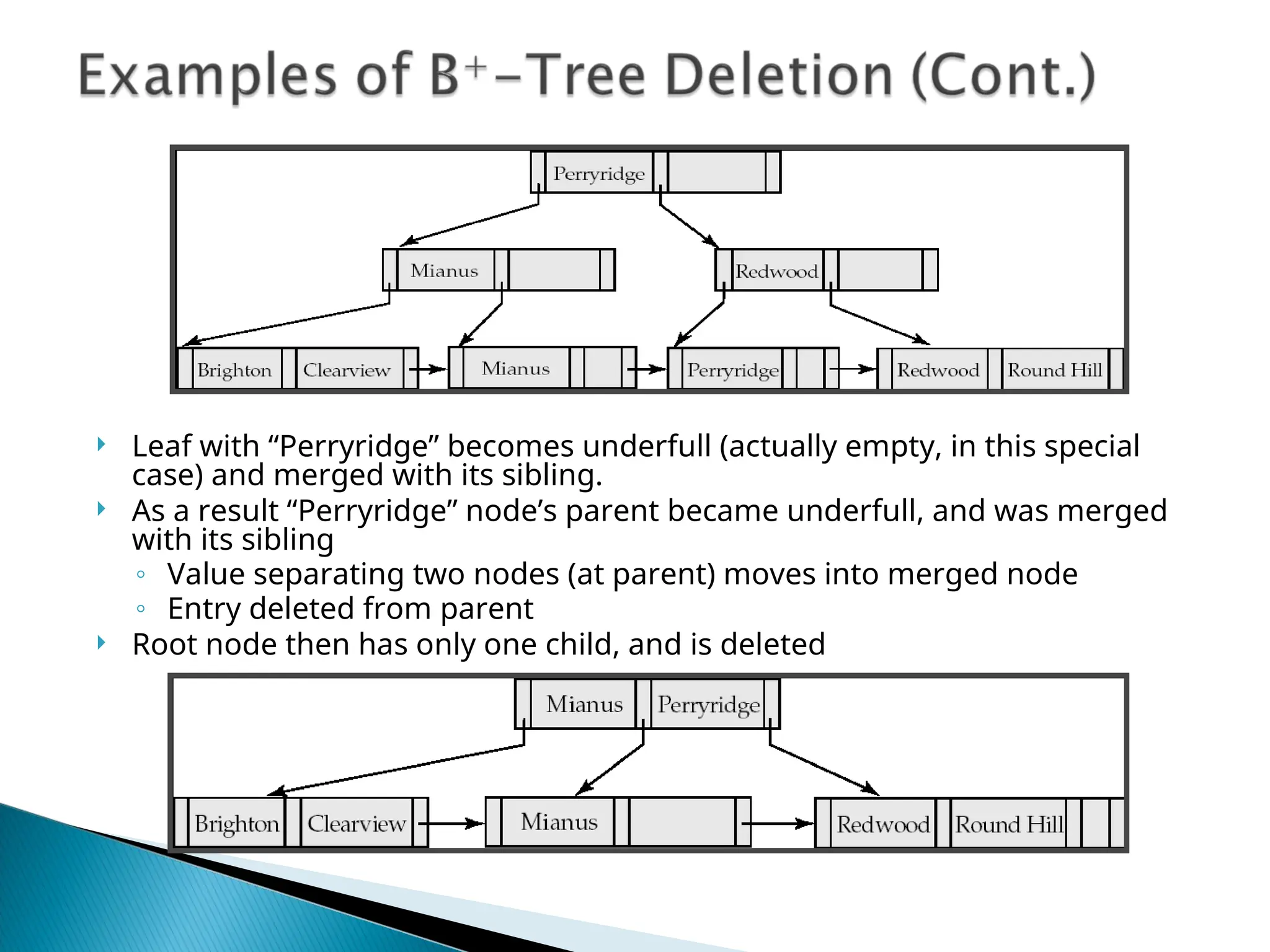
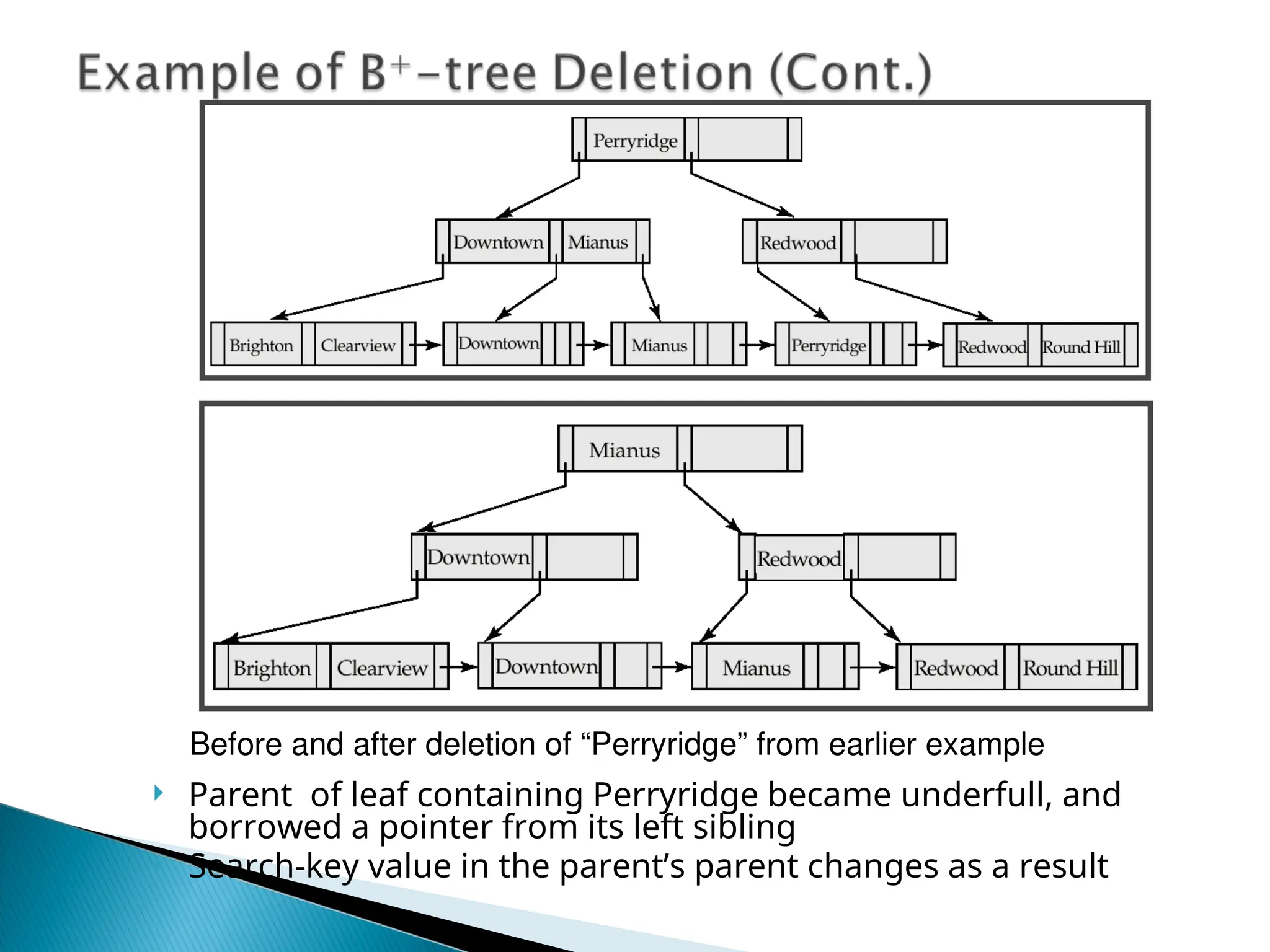
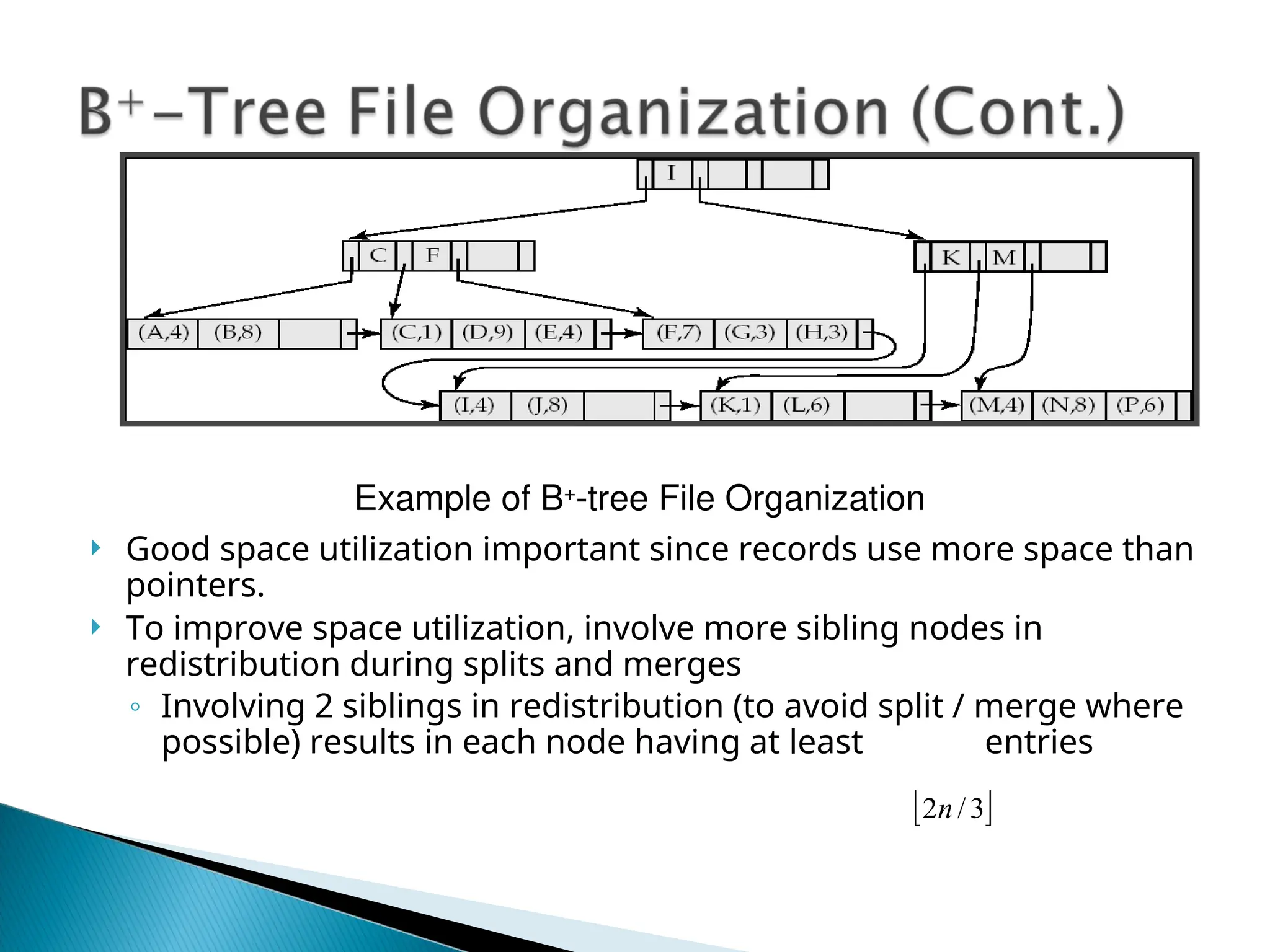
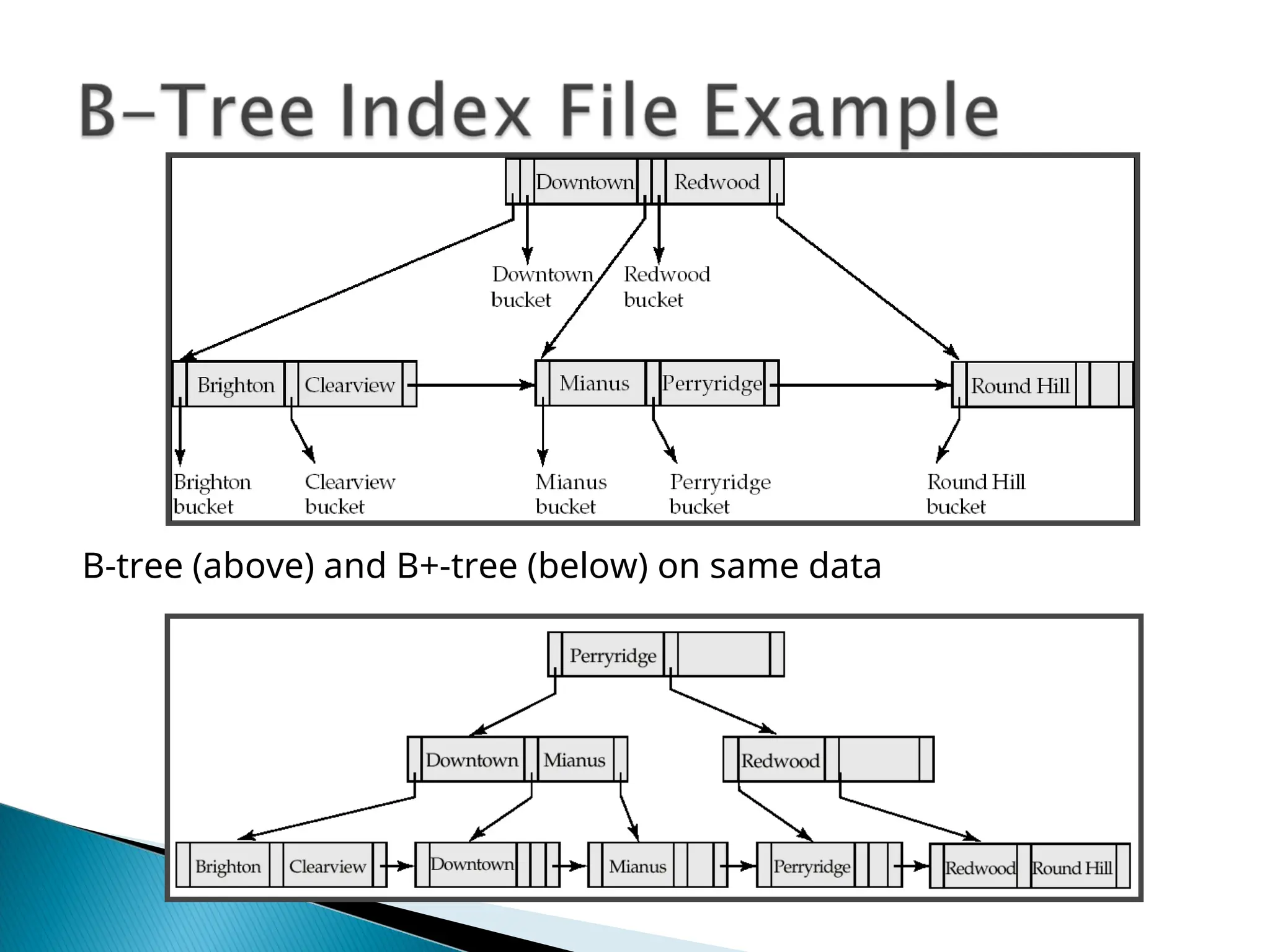
The document outlines the various indexing techniques in databases, including ordered indices, B+ trees, and hashing, focusing on their structures, benefits, and performance considerations. It emphasizes the role of indices in improving data access speed and the trade-offs involved in updating indices during database modifications. B+ trees are highlighted for their efficient handling of insertions and deletions, and for maintaining balanced structures that ensure fast lookup times.






































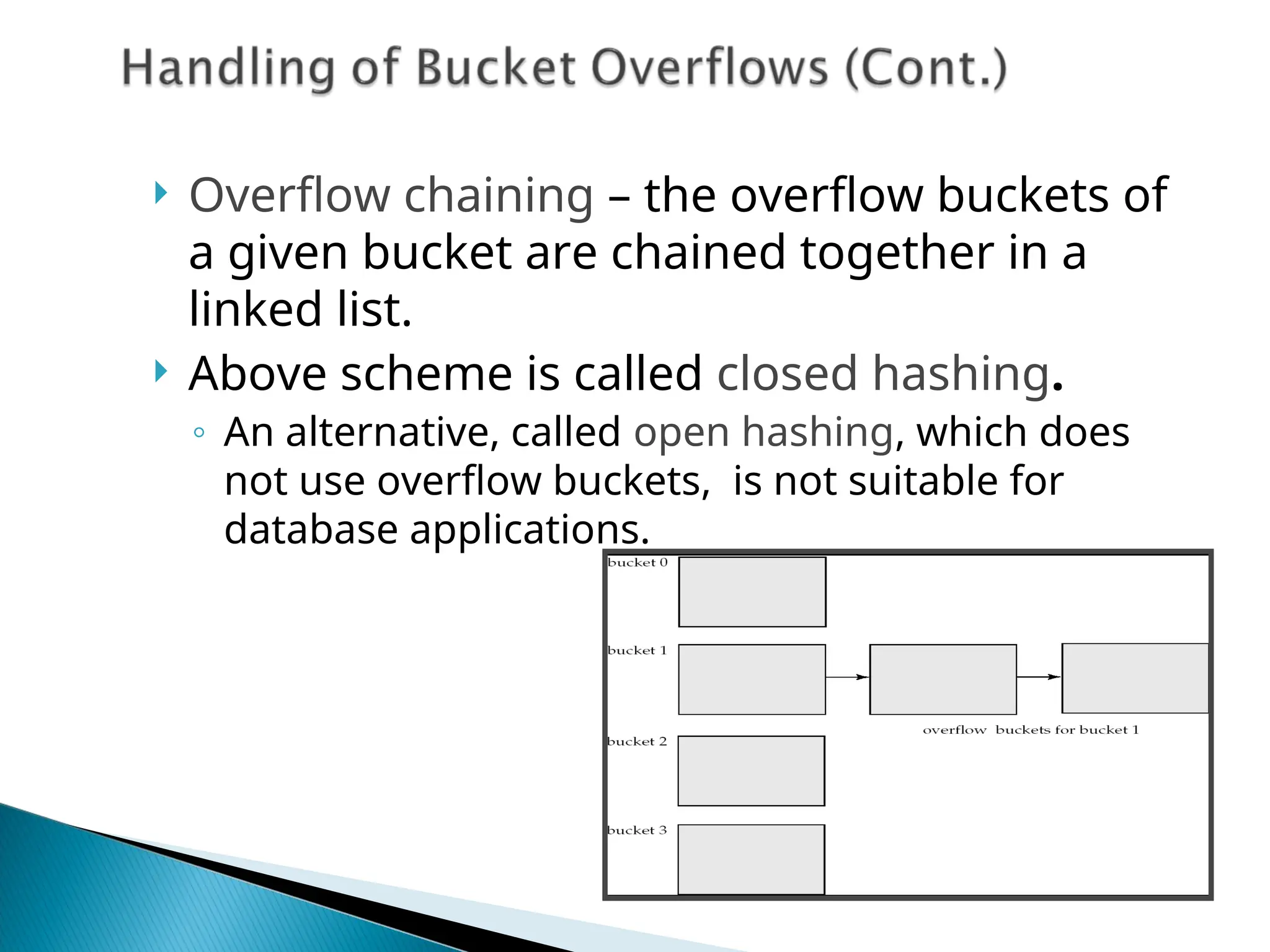

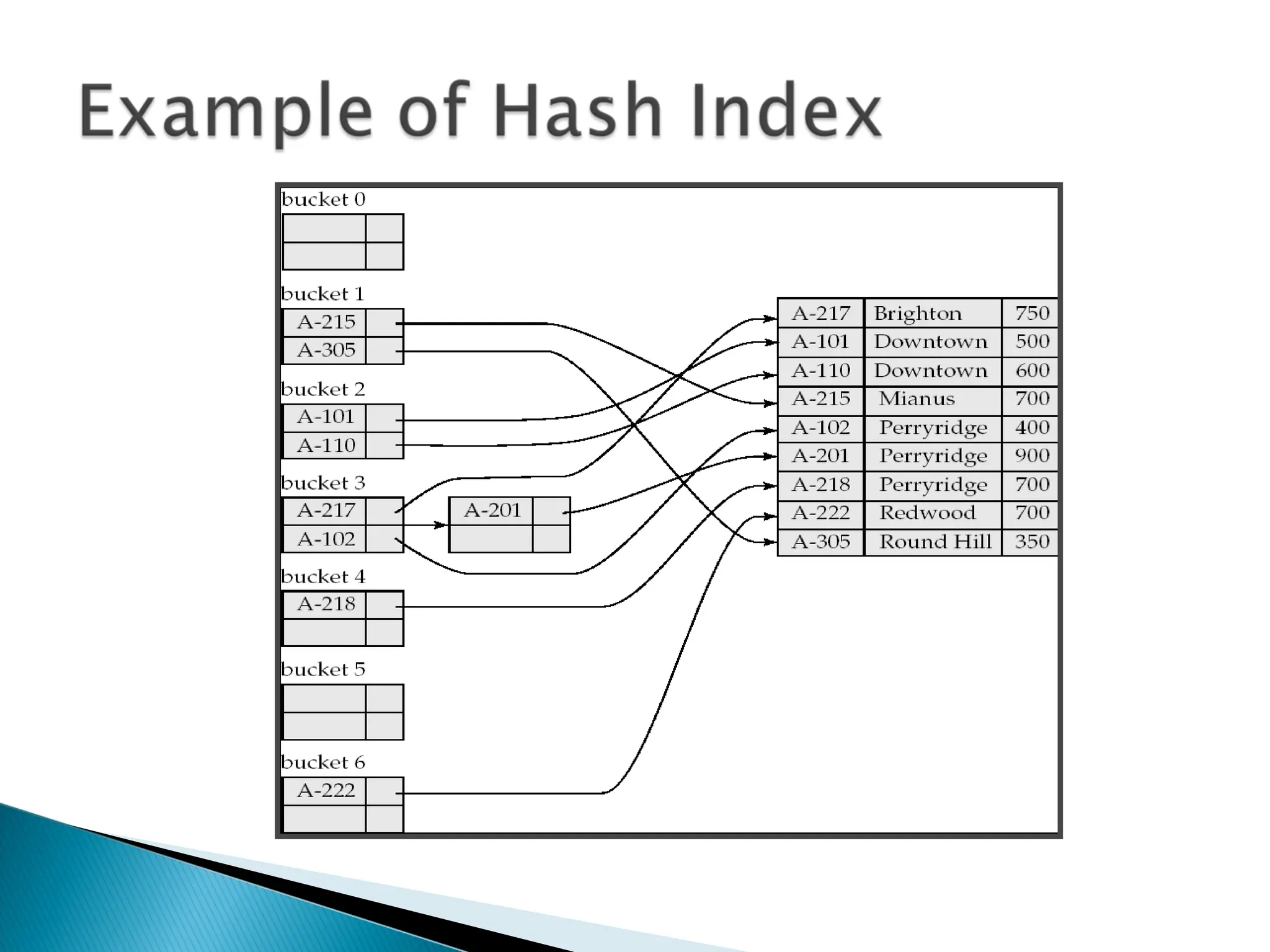


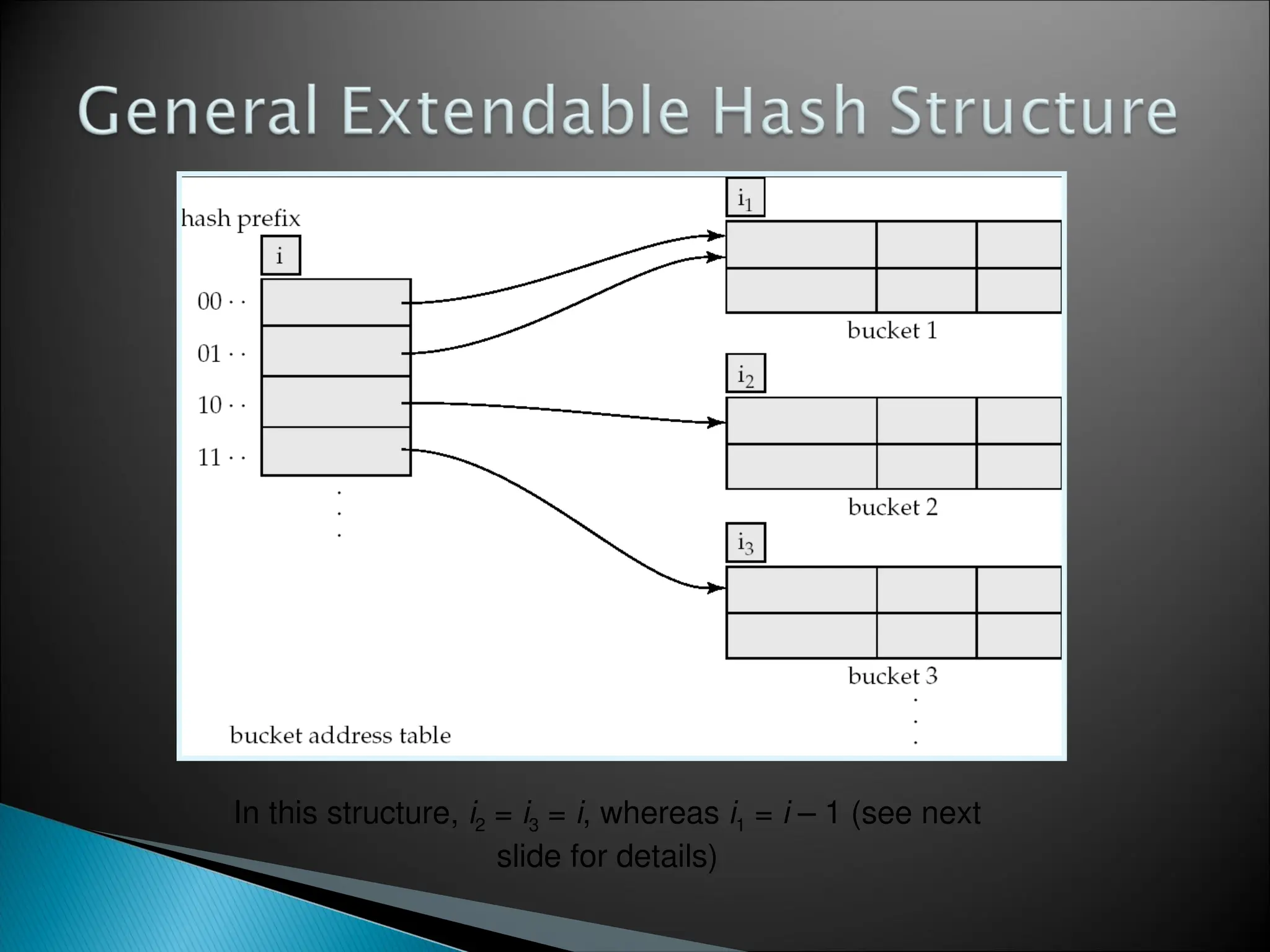


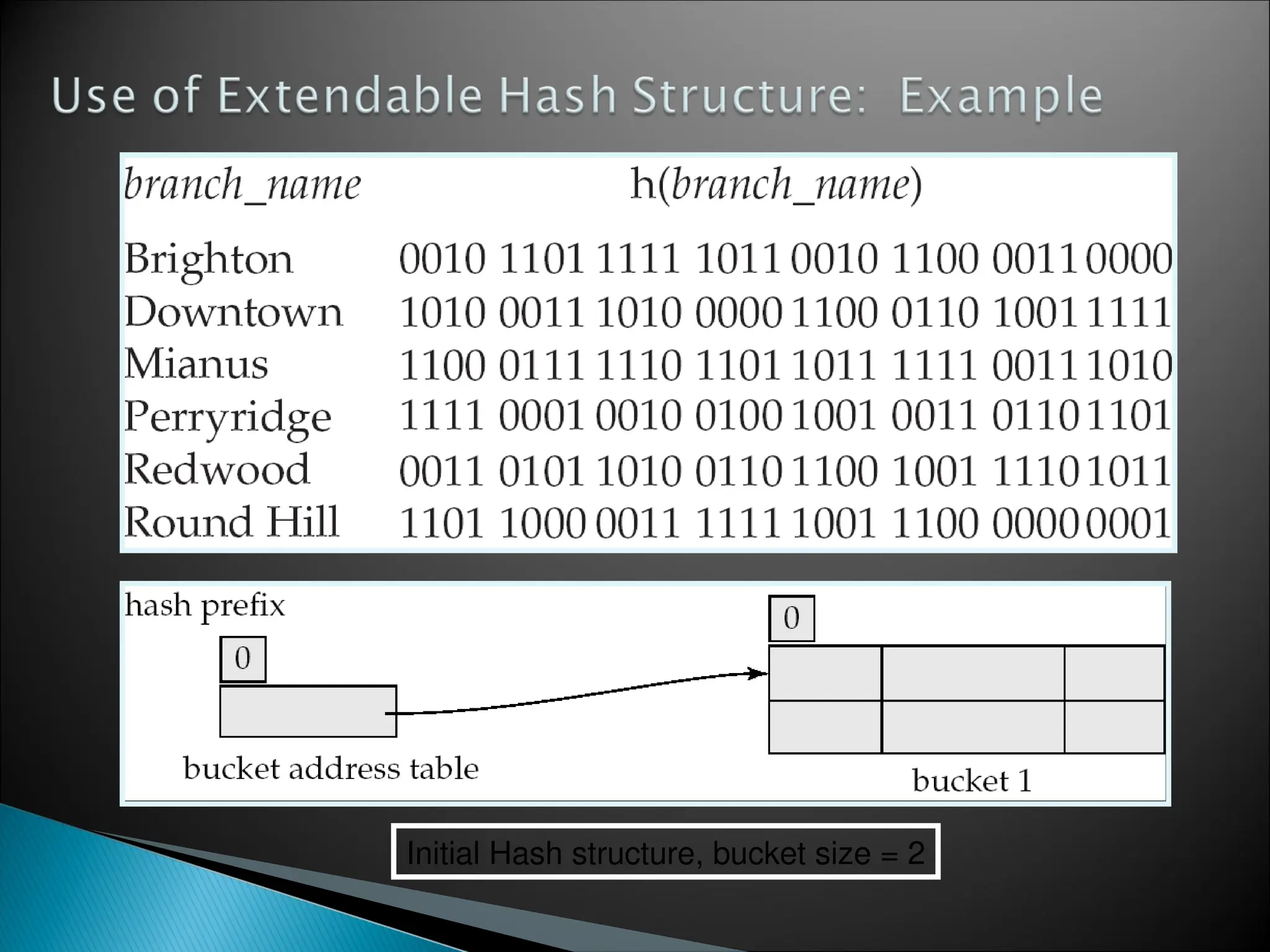
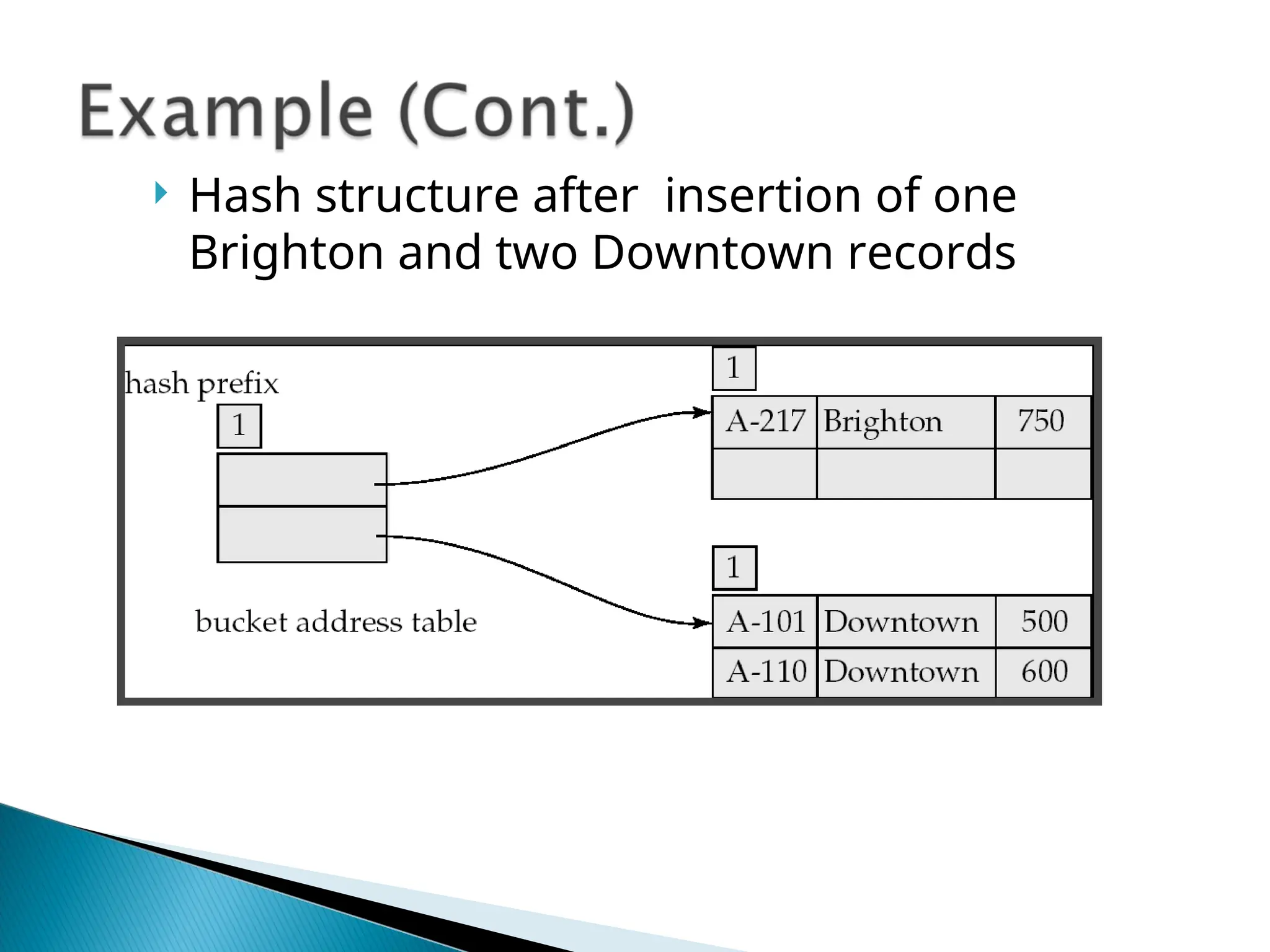
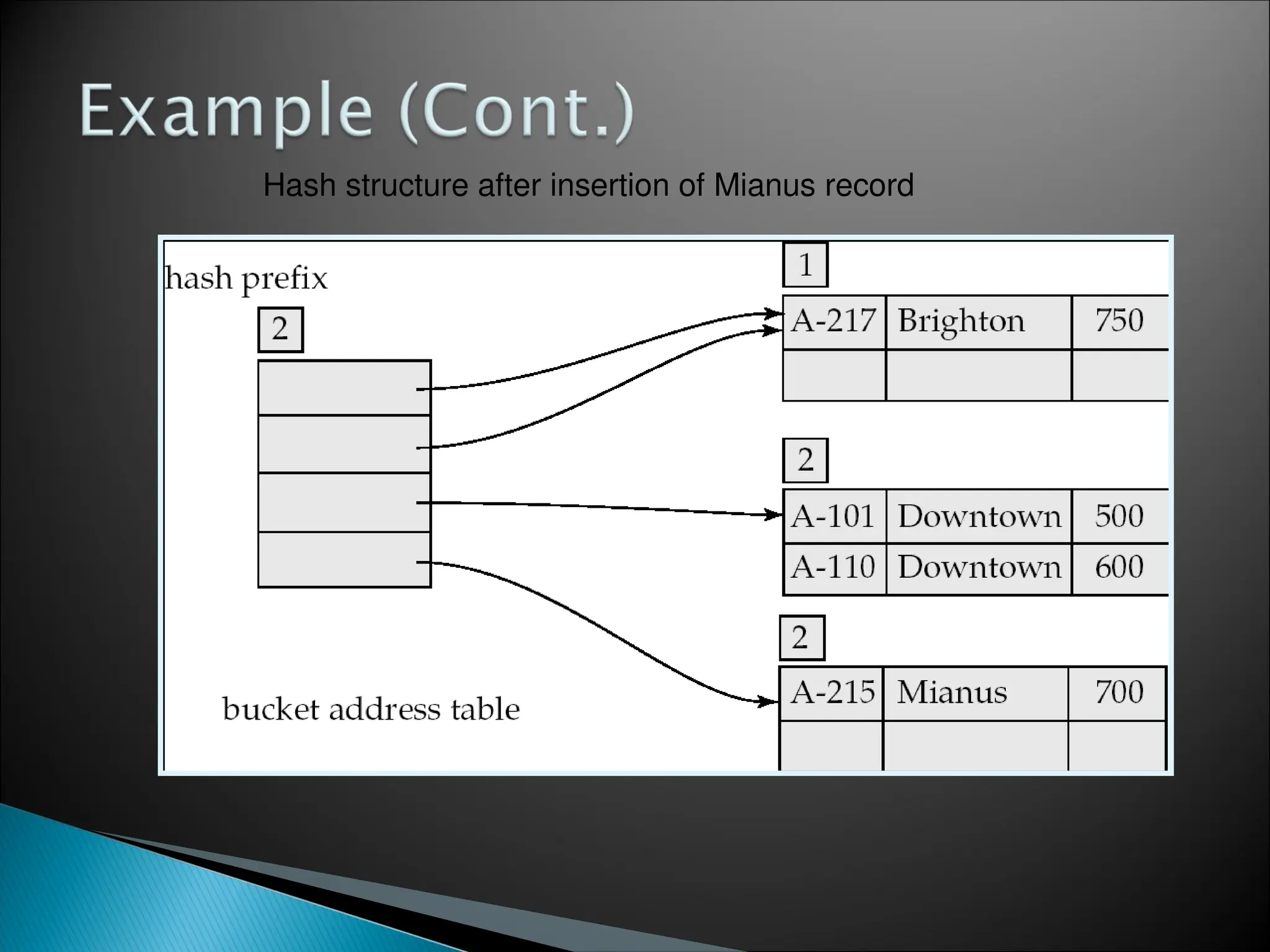
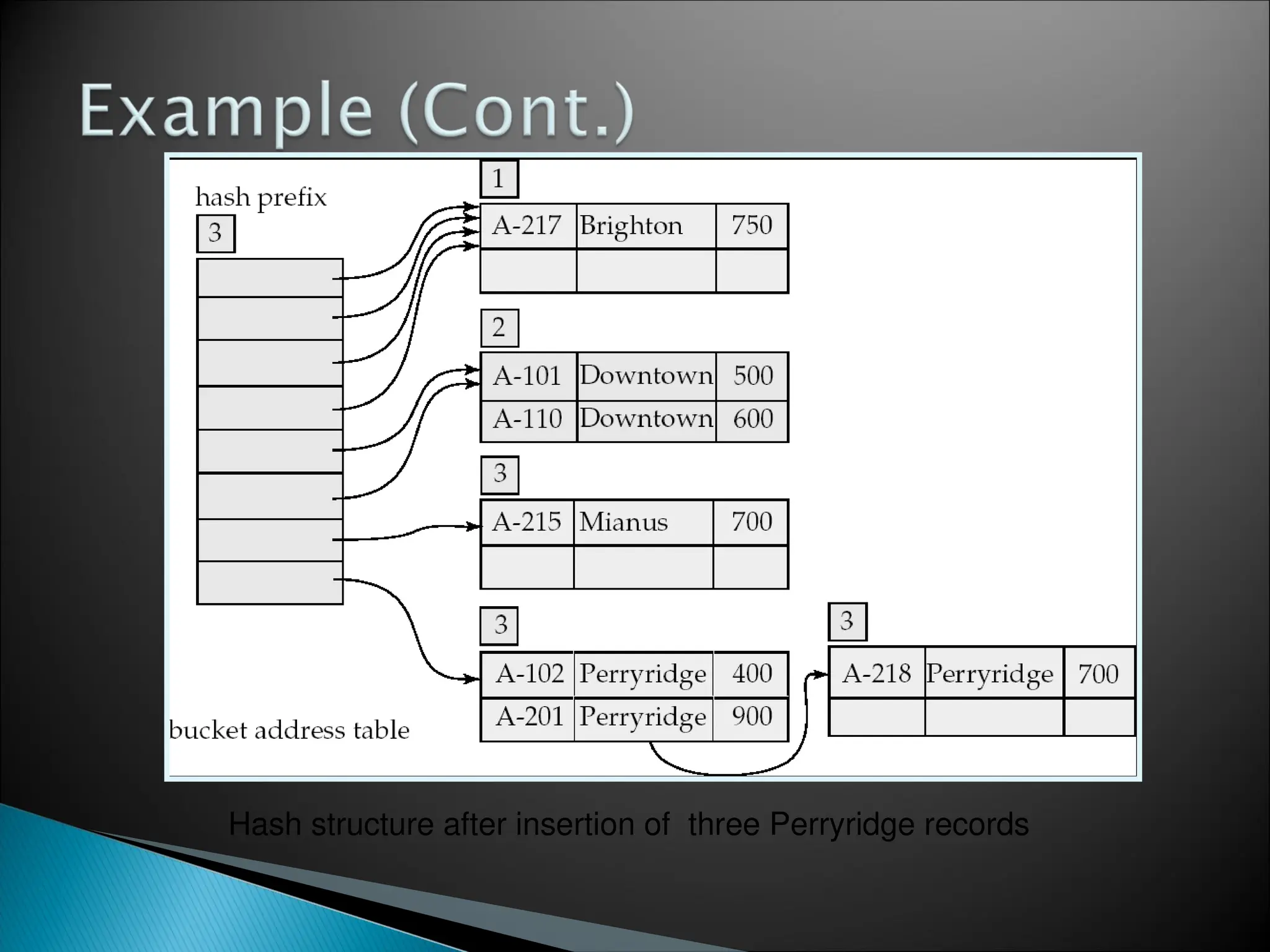
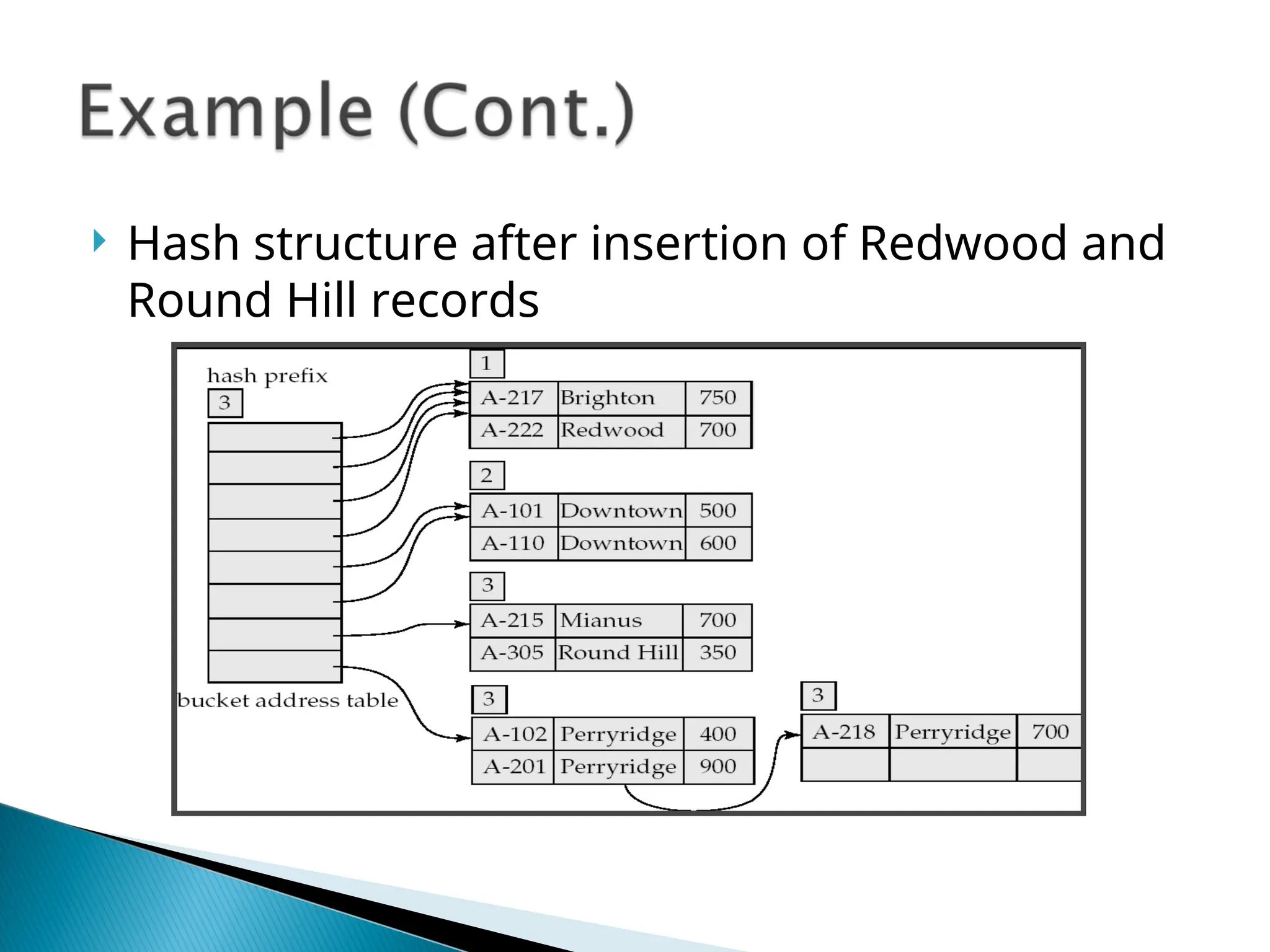

































![[Www.pkbulk.blogspot.com]file and indexing](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comfileandindexing-130615034648-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















