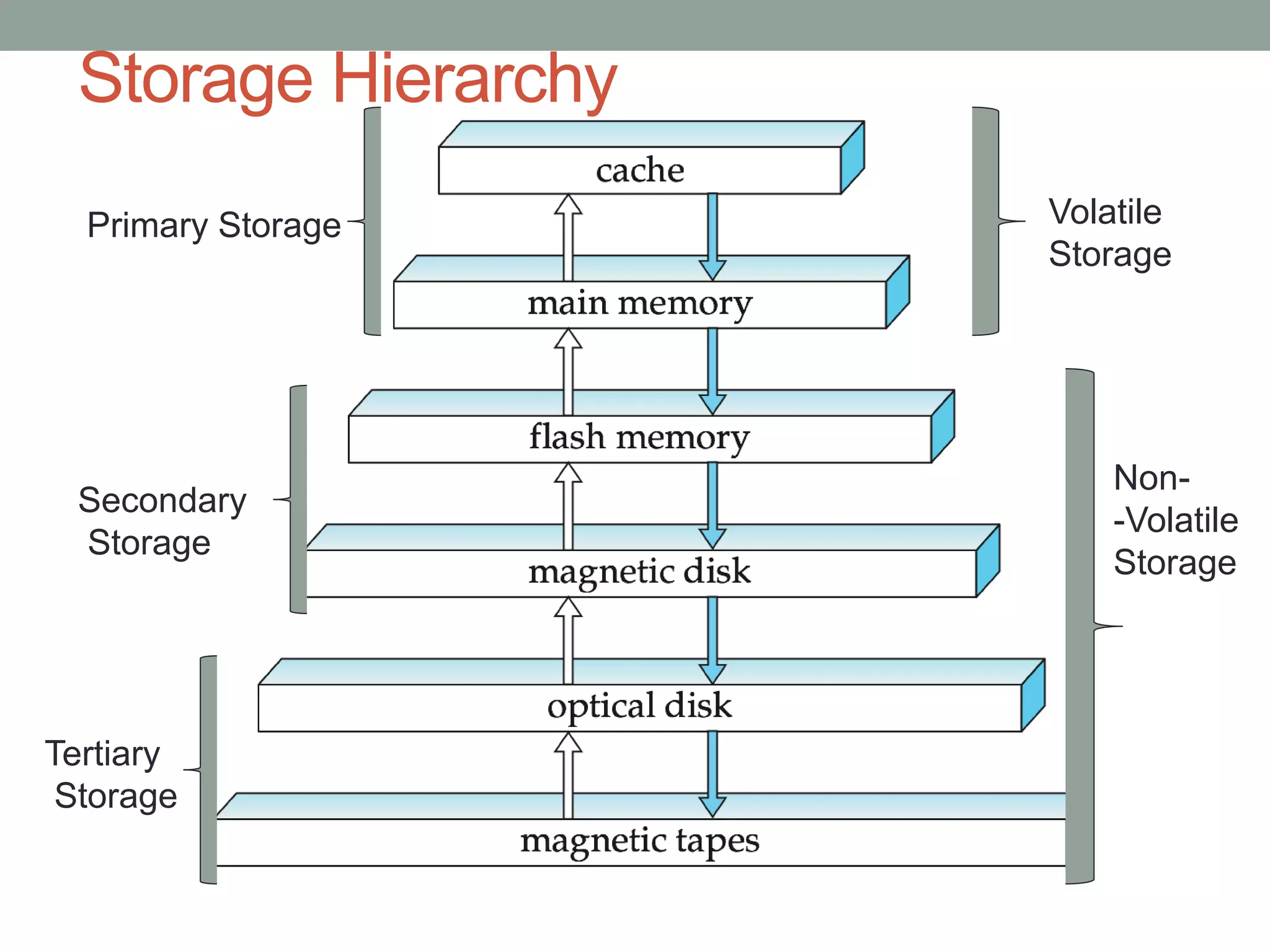
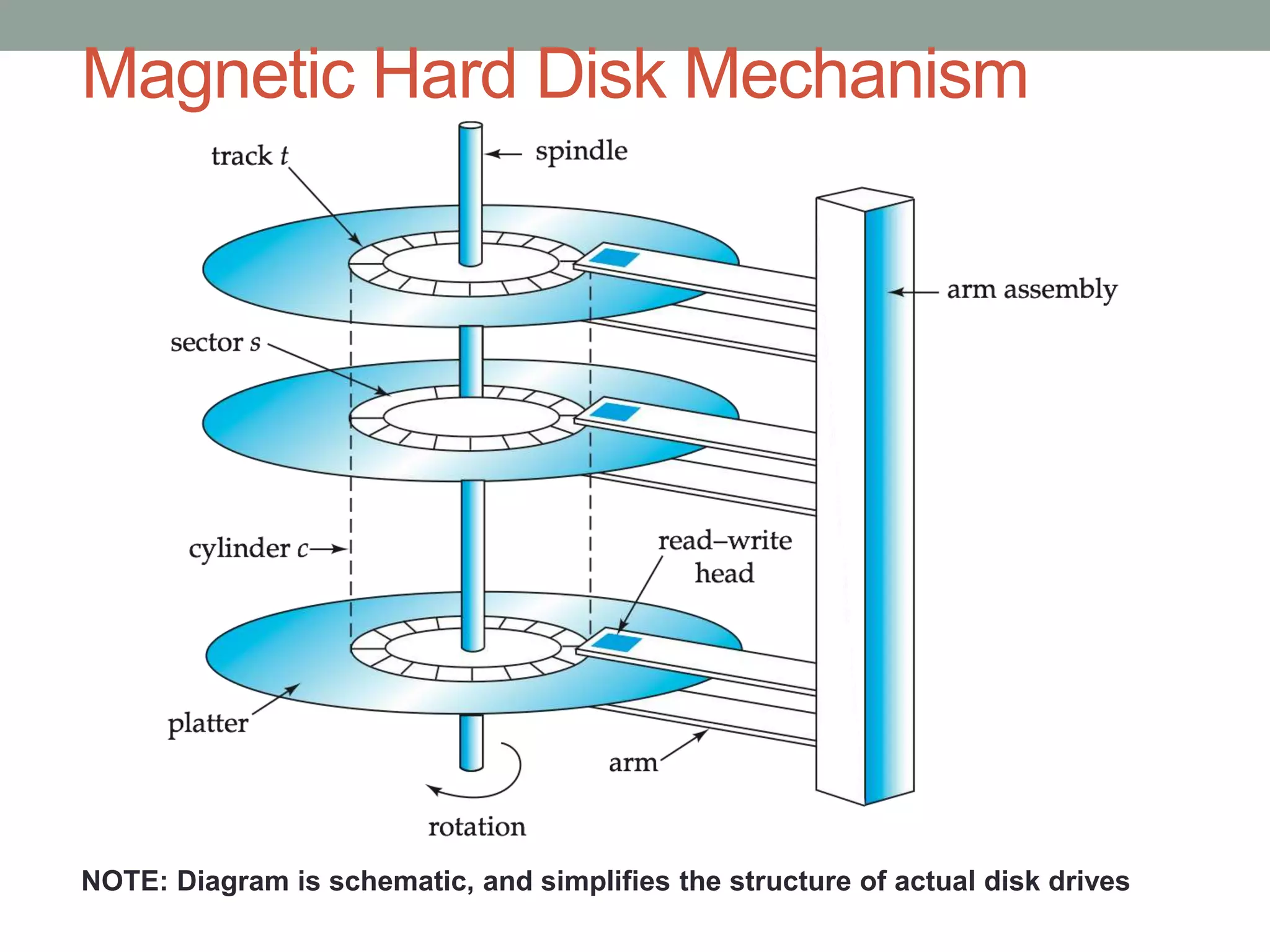
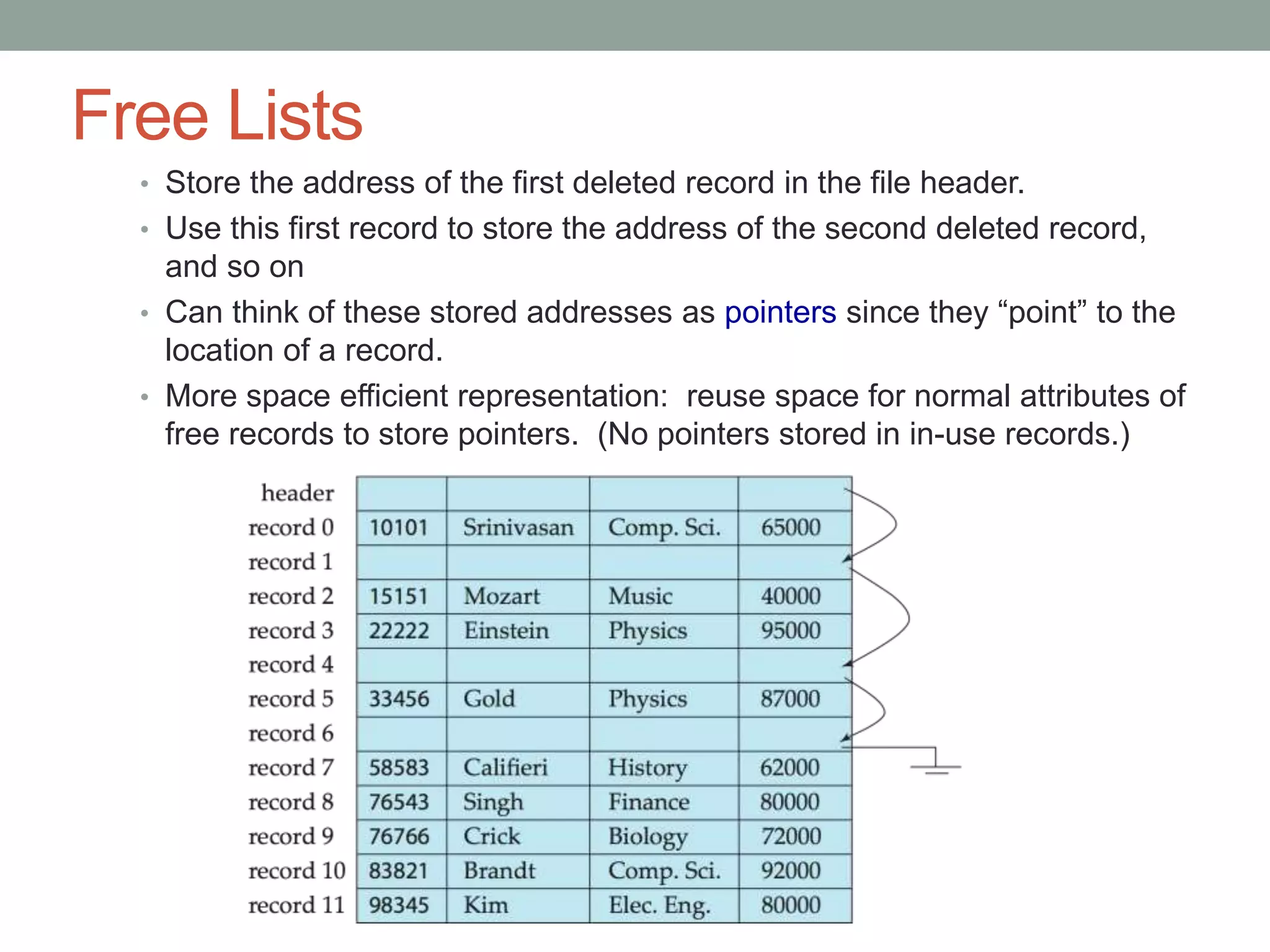
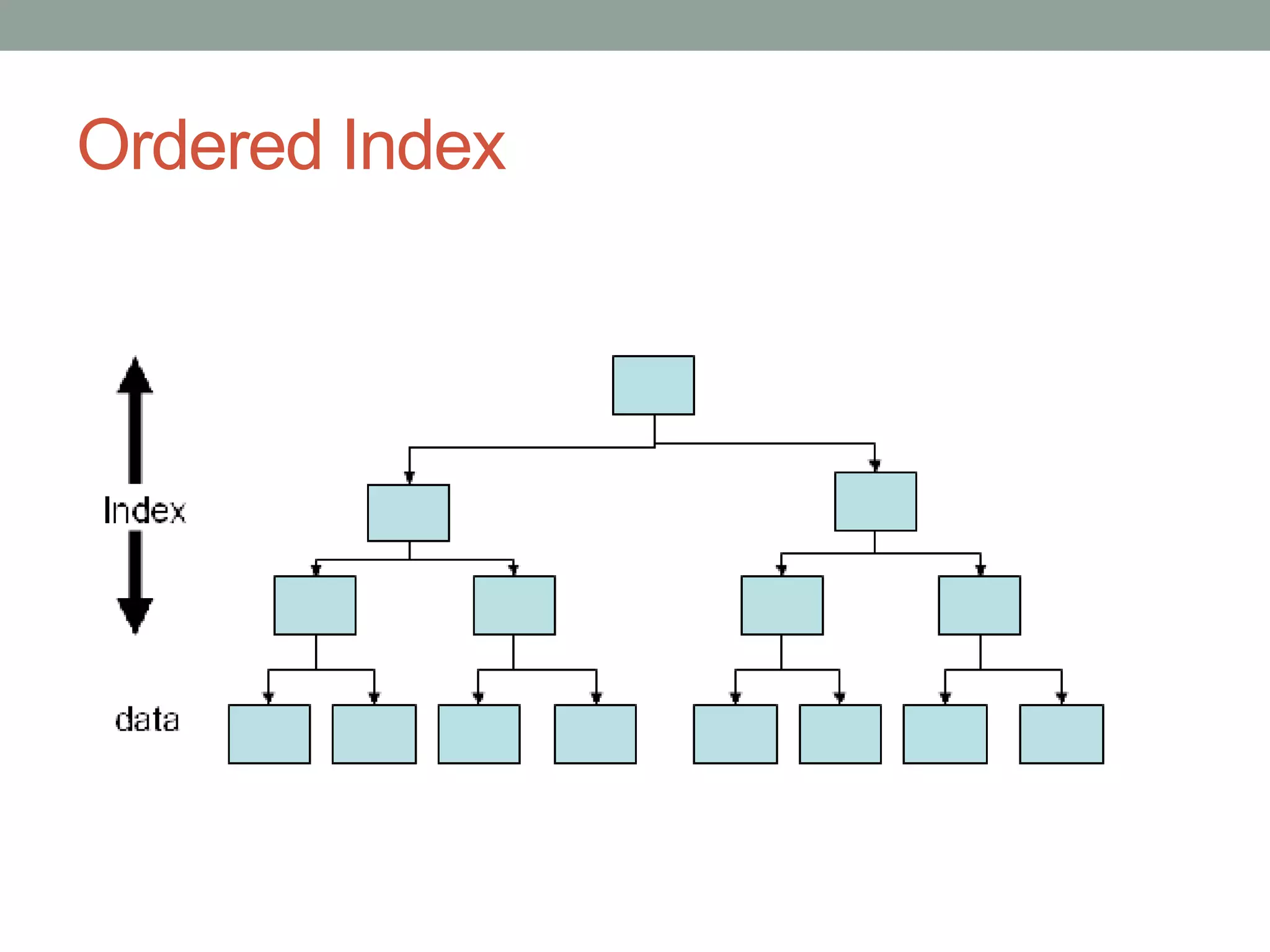
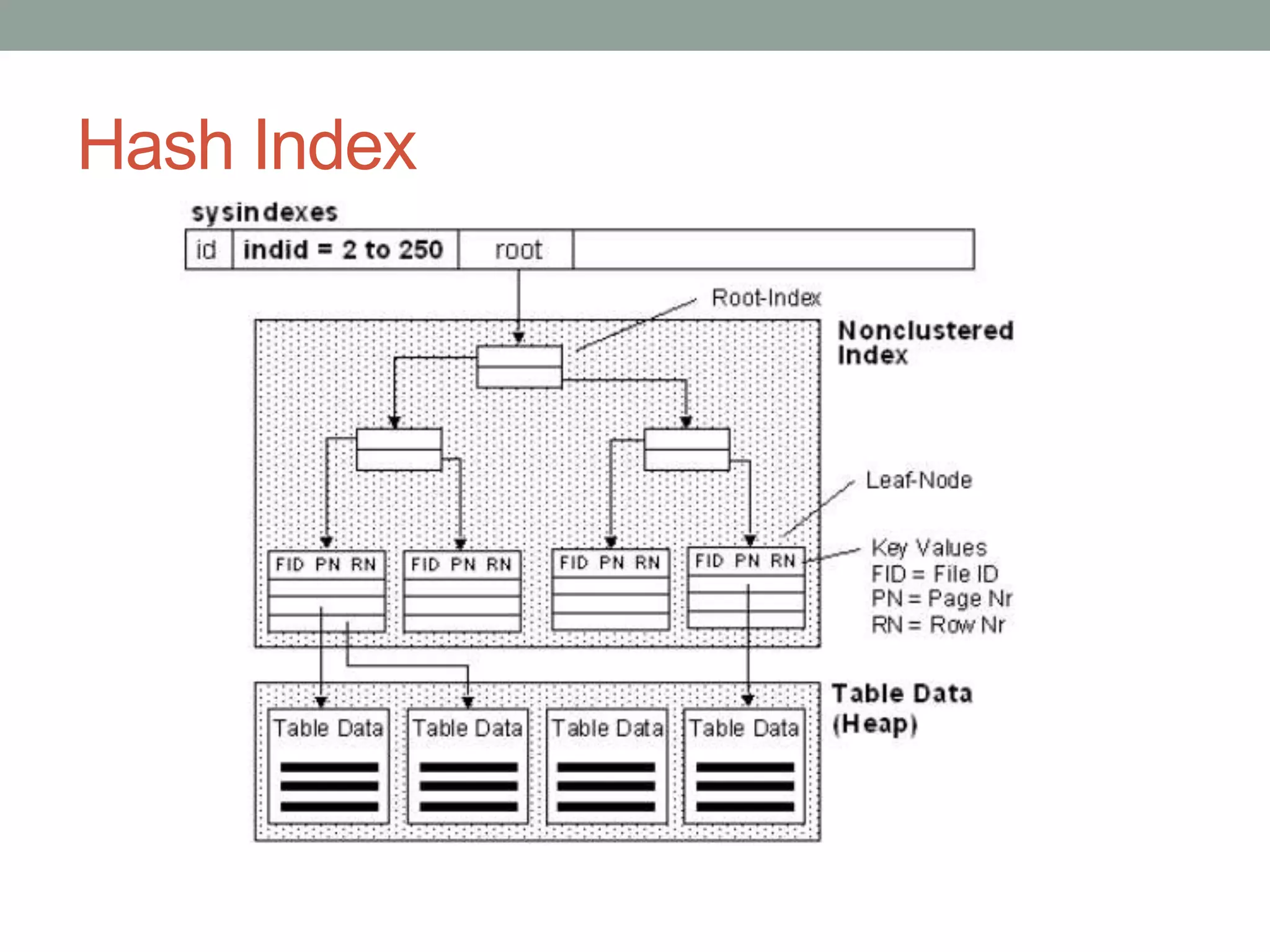
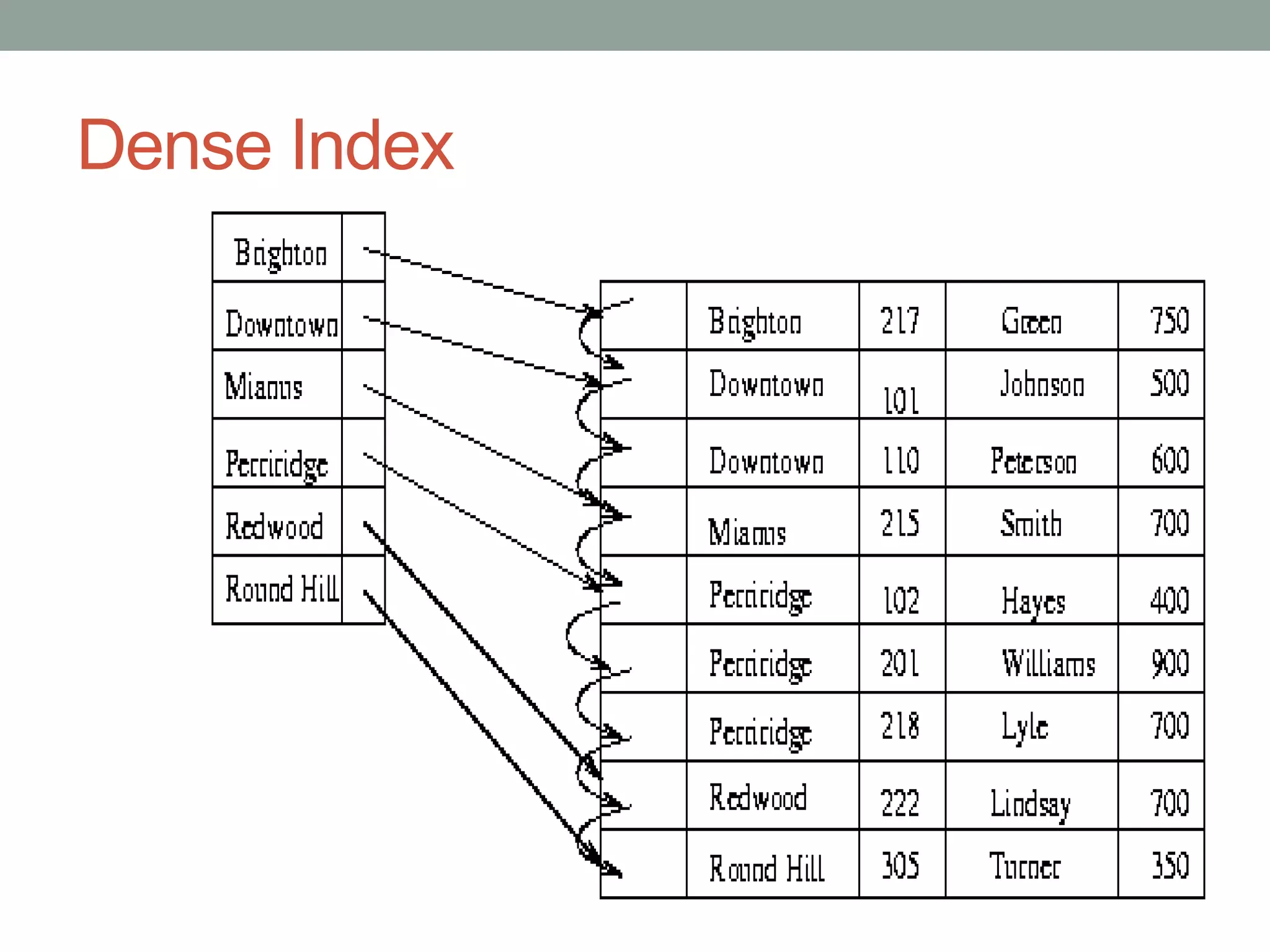
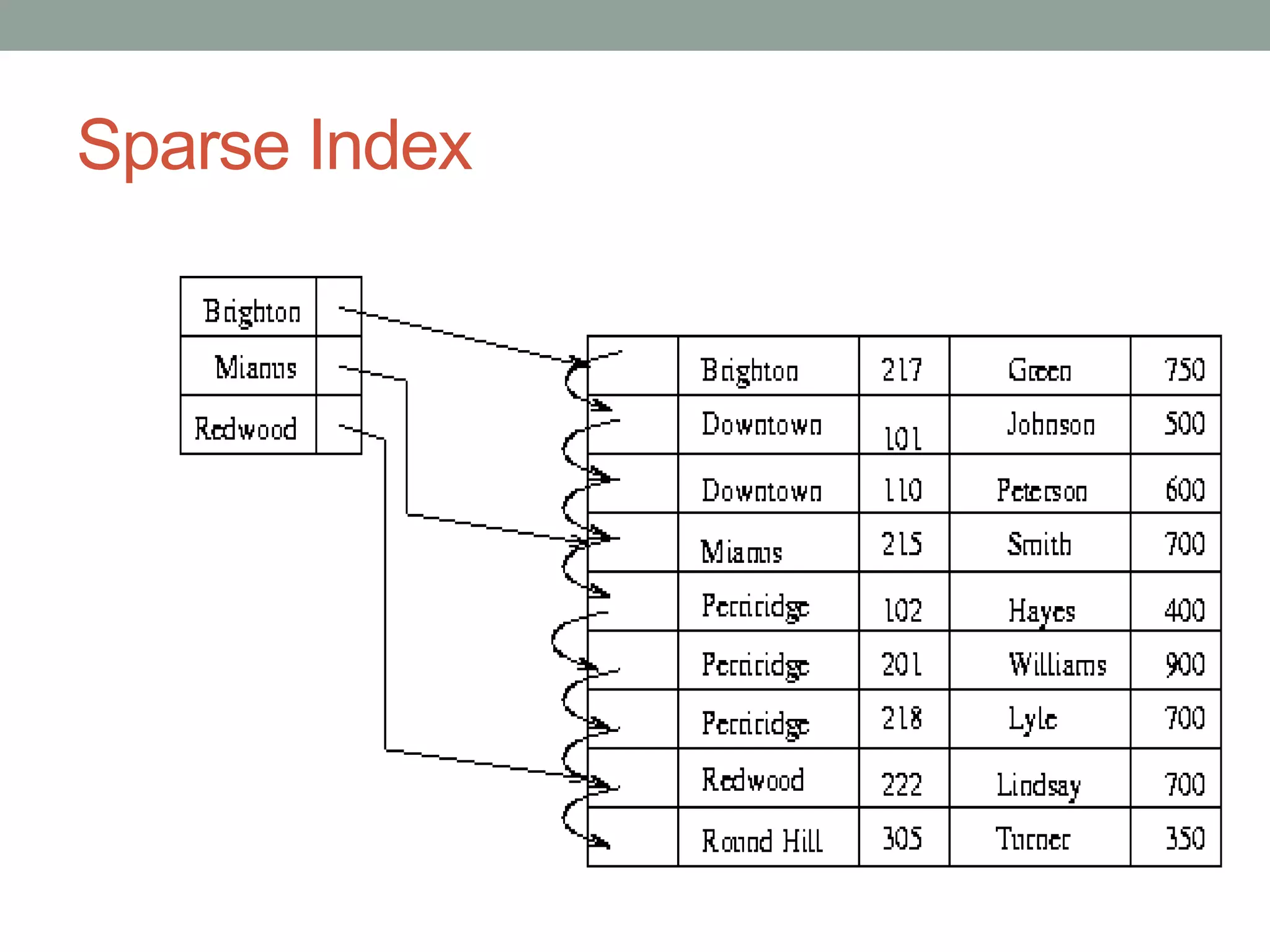
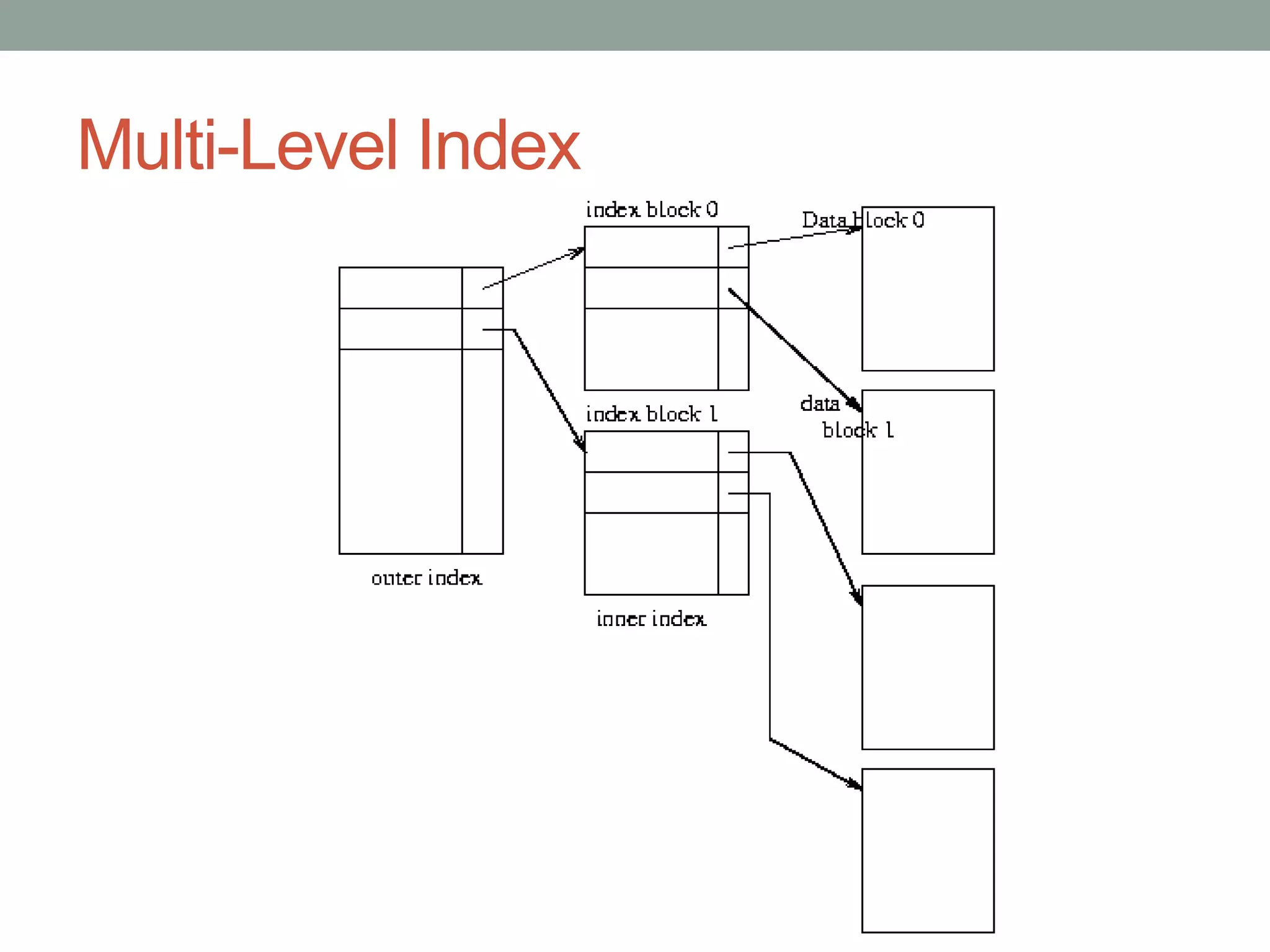
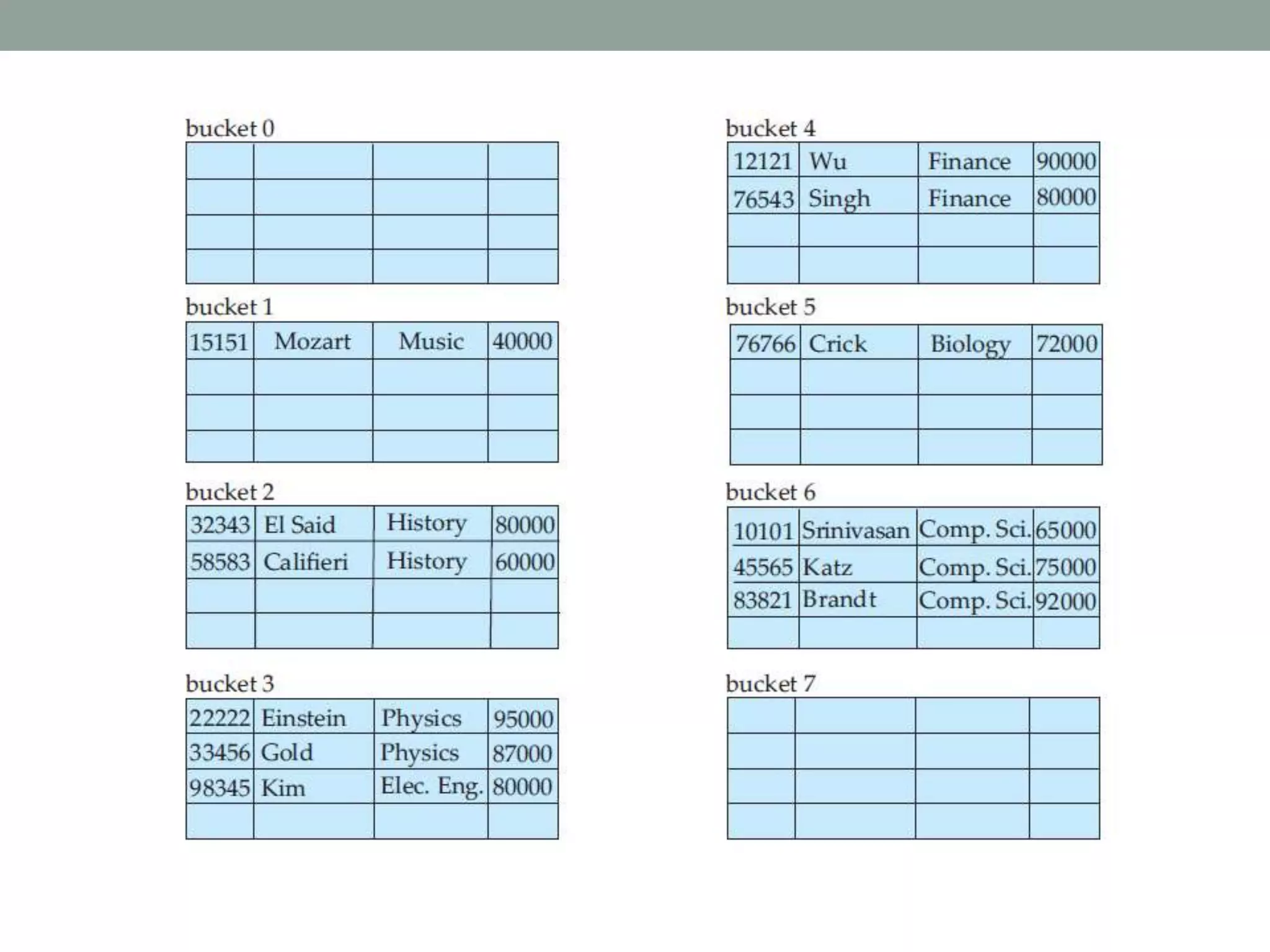
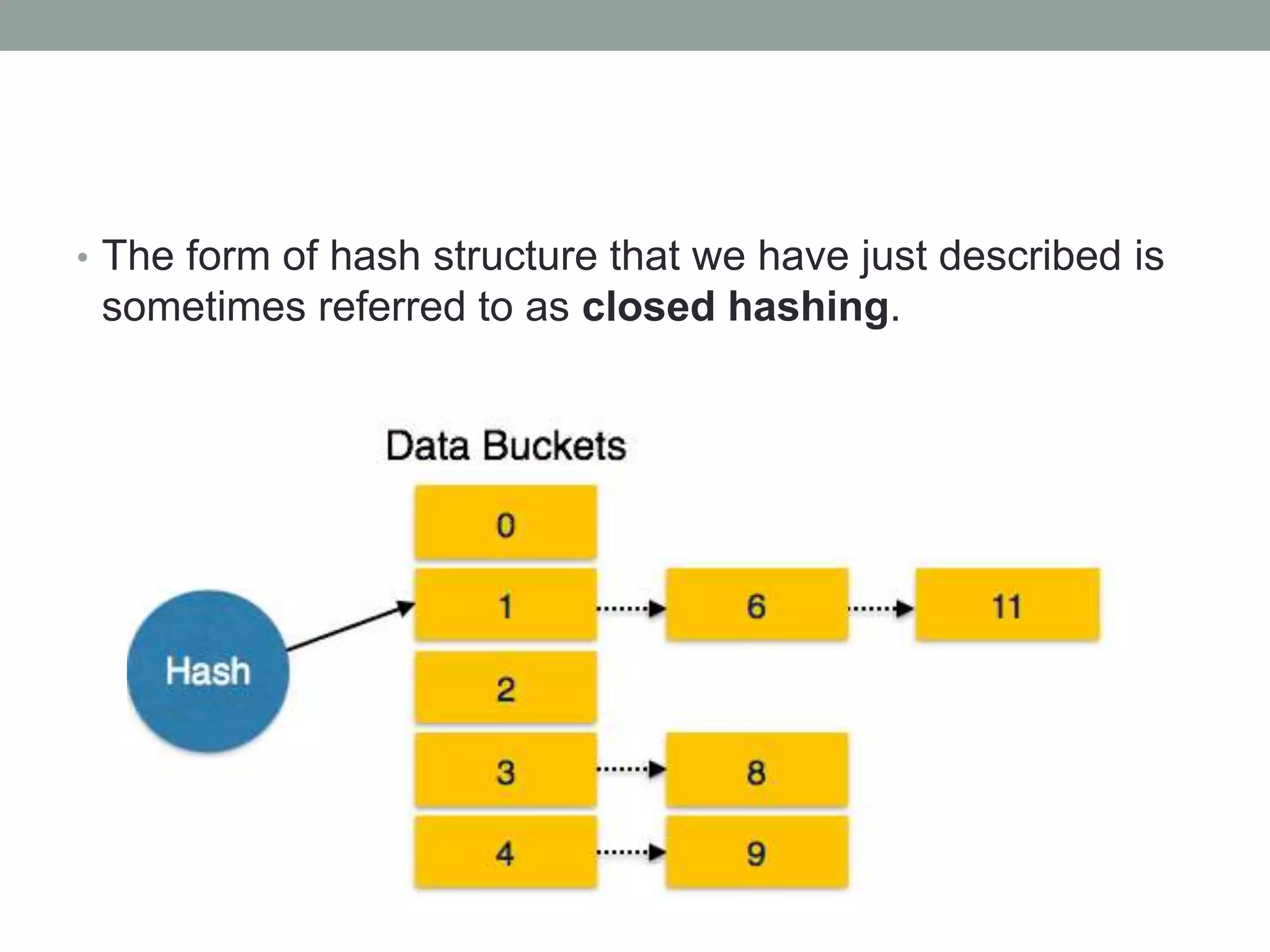
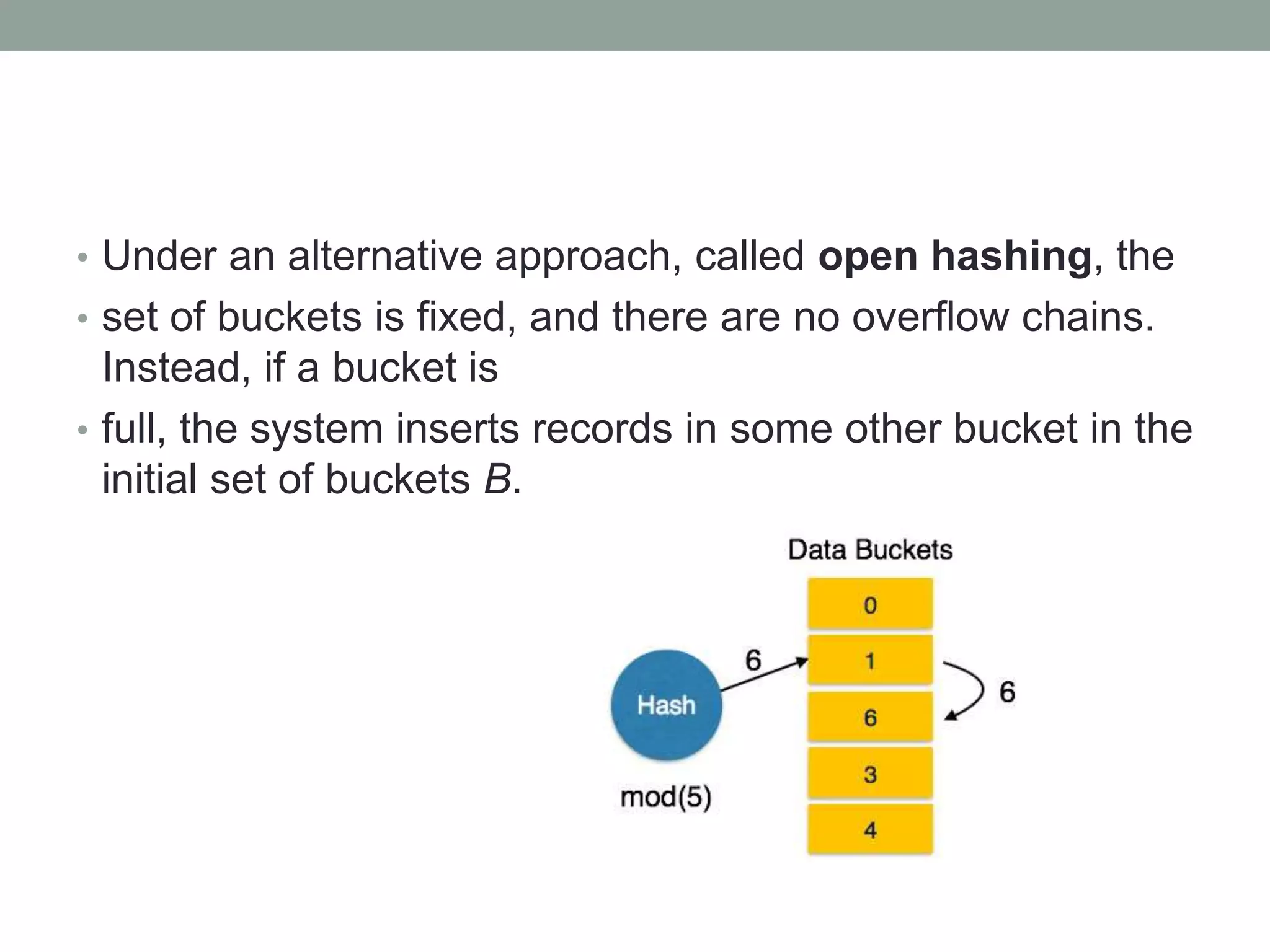
Chapter 10 discusses storage and file structures in databases, including types of storage (volatile, non-volatile), performance measures of disks, and file organization techniques like fixed-length and variable-length records. It explores data indexing and hashing methods to improve data retrieval speeds, detailing the use of ordered and hash indices, as well as collision resolution strategies such as open addressing and separate chaining. The chapter emphasizes the importance of efficient data organization to minimize access time and optimize memory usage.