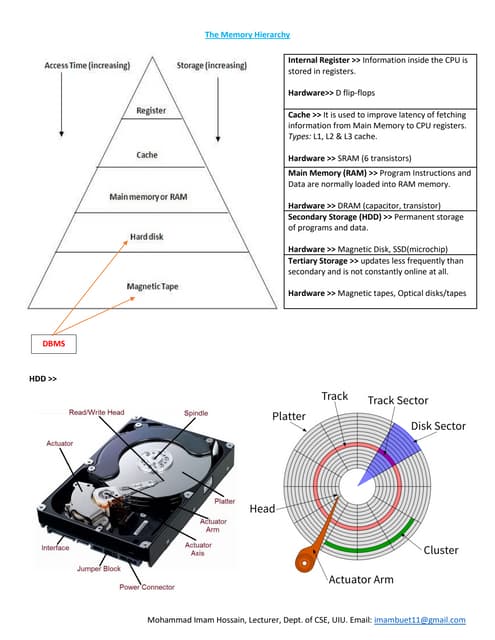
The document discusses various file organization methods and indexing techniques in database management systems (DBMS), focusing on their efficiency for data retrieval and manipulation. Key structures include heap file organization, primary and secondary indexes, hashing, and B-trees, each with distinct advantages and disadvantages depending on the use case. Overall, it highlights how these methods impact performance, especially regarding fast insertions, searches, and handling range queries.