Download to read offline










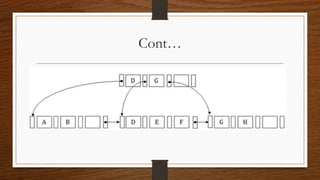
![Properties of B-Tree:
• All leaves are at the same level.
• A B-Tree is defined by the term minimum degree ‘t’. The value of t depends upon disk block size.
• Every node except root must contain at least (ceiling)([t-1]/2) keys. The root may contain minimum 1 key.
• All nodes (including root) may contain at most t – 1 keys.
• Number of children of a node is equal to the number of keys in it plus 1.
• All keys of a node are sorted in increasing order. The child between two keys k1 and k2 contains all keys in
the range from k1 and k2.
• B-Tree grows and shrinks from the root which is unlike Binary Search Tree. Binary Search Trees grow
downward and also shrink from downward.
• Like other balanced Binary Search Trees, time complexity to search, insert and delete is O(log n).](https://image.slidesharecdn.com/filestructurespart2-210424093922/85/File-Structures-Part-2-10-320.jpg)





The document discusses different file structures and indexing techniques used in databases. It describes secondary keys as keys that are not selected as the primary key but are candidate keys. It then explains inverted and multi-user files, and different file organization methods like sequential, heap, hash, and B-tree organizations. It provides details on B-trees and B+trees, including their properties, time complexities for operations, and structure for internal and leaf nodes in B+trees.


































![Presentation on b trees [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/presentationonbtreesautosaved-210209155822-thumbnail.jpg?width=640&height=640&fit=bounds)




















































