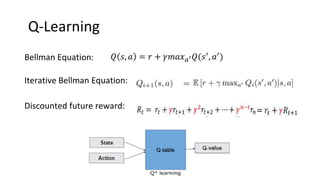
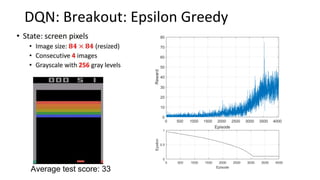
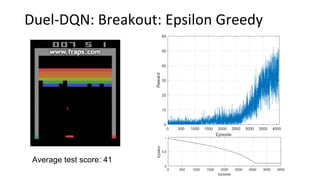
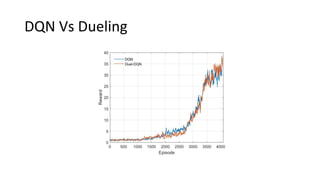
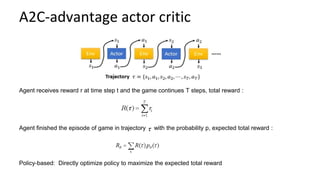
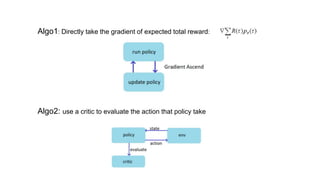
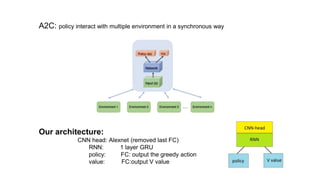
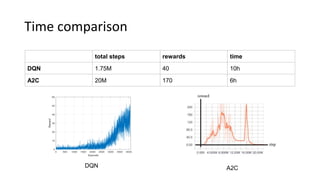
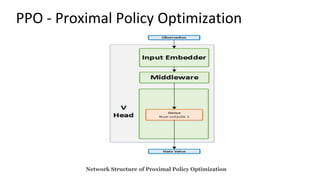
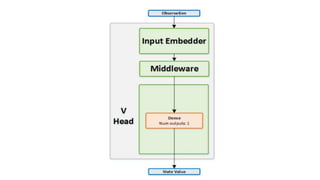
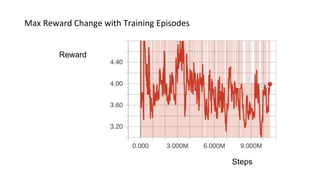
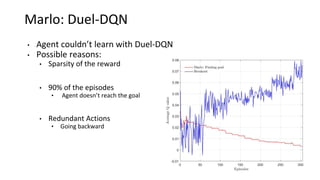
This document summarizes reinforcement learning experiments using the MarLӦ and Breakout environments. It introduces MarLӦ, a multi-agent Minecraft environment, and Breakout, the classic Atari game. It then compares the performance of DQN, Dueling DQN, A2C, and PPO on Breakout, finding that Dueling DQN and A2C learn best. However, these algorithms did not learn effectively in the more complex MarLӦ environment due to its sparsity of reward, redundant actions, and long reset times. Challenges of learning in MarLӦ included its complexity, long training times, and limited computing resources.



















![[1808.00177] Learning Dexterous In-Hand Manipulation](https://cdn.slidesharecdn.com/ss_thumbnails/learningdextrousinhandmanipulation-180814000608-thumbnail.jpg?width=640&height=640&fit=bounds)

![[1312.5602] Playing Atari with Deep Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/playingatariwithdeepreinforcementlearning-180814064557-thumbnail.jpg?width=640&height=640&fit=bounds)










































