Download as PDF, PPTX






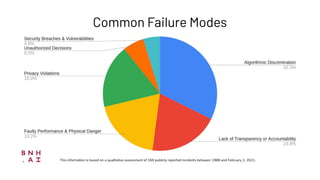


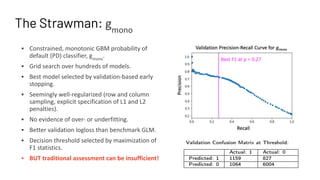
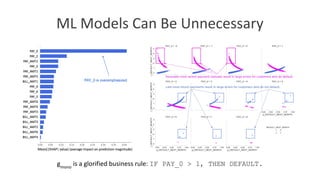

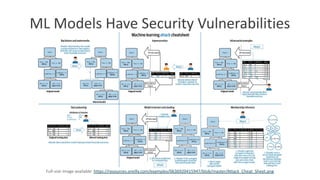




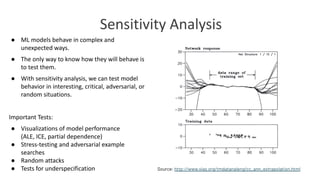



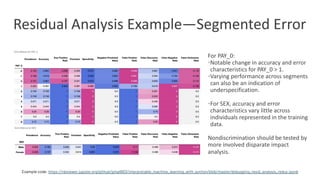
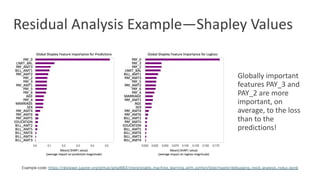
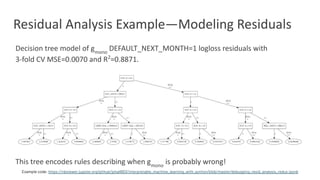










The document discusses model debugging as a crucial discipline for identifying and correcting errors in machine learning models, comparing its methods to traditional software debugging techniques. It emphasizes the importance of testing models, understanding their biases, and implementing robust governance and quality assurance practices to mitigate risks associated with AI. Various strategies for improving model reliability and performance are highlighted, including sensitivity analysis, residual analysis, and the importance of diverse teams and domain expertise.























































































