Downloaded 1,217 times







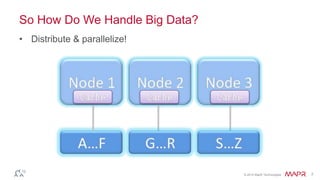






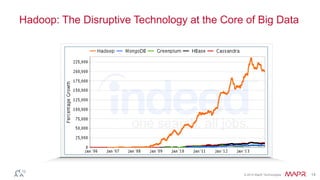
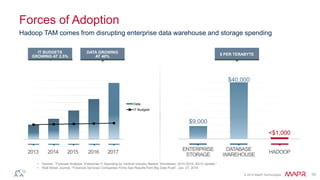








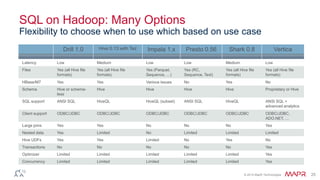
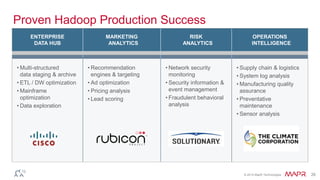










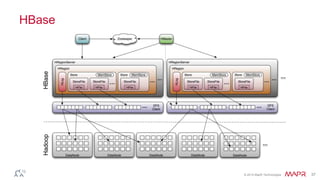


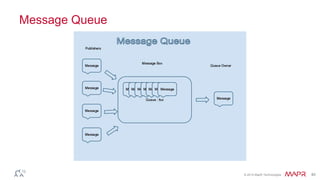


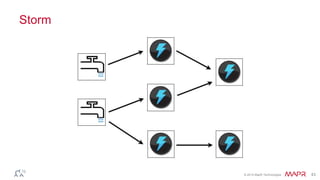


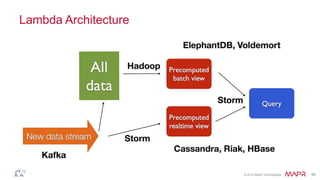
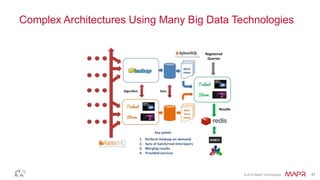



This document discusses big data and the Internet of Things (IoT). It states that while IoT data can be big data, big data strategies and technologies apply regardless of data source or industry. It defines big data as occurring when the size of data becomes problematic to store, move, extract, analyze, etc. using traditional methods. It recommends distributing and parallelizing data using approaches like Hadoop and discusses how technologies like SQL on Hadoop, Pig, Spark, HBase, queues, stream processing, and complex architectures can be used to handle big IoT and other big data.












































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)










