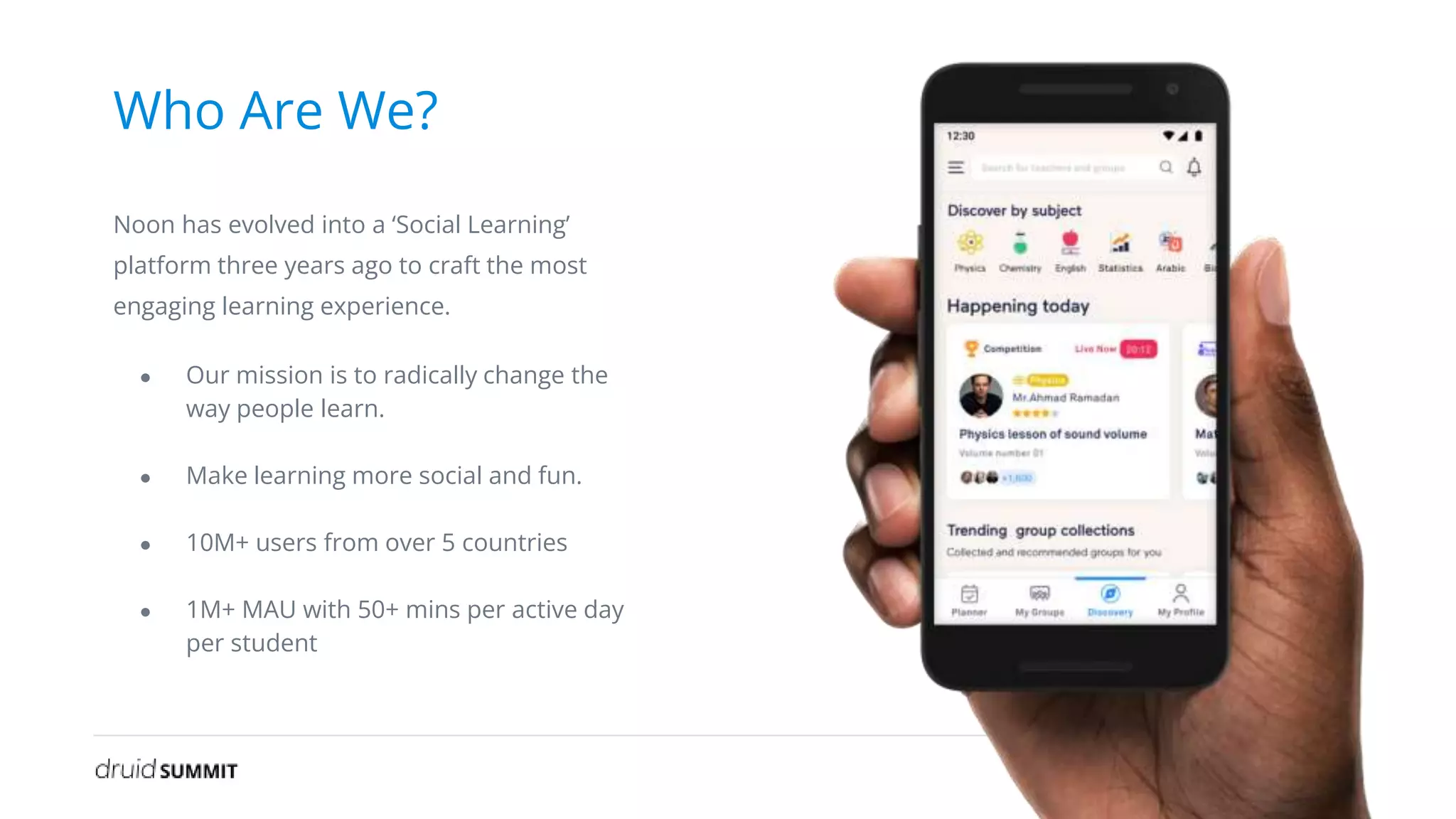
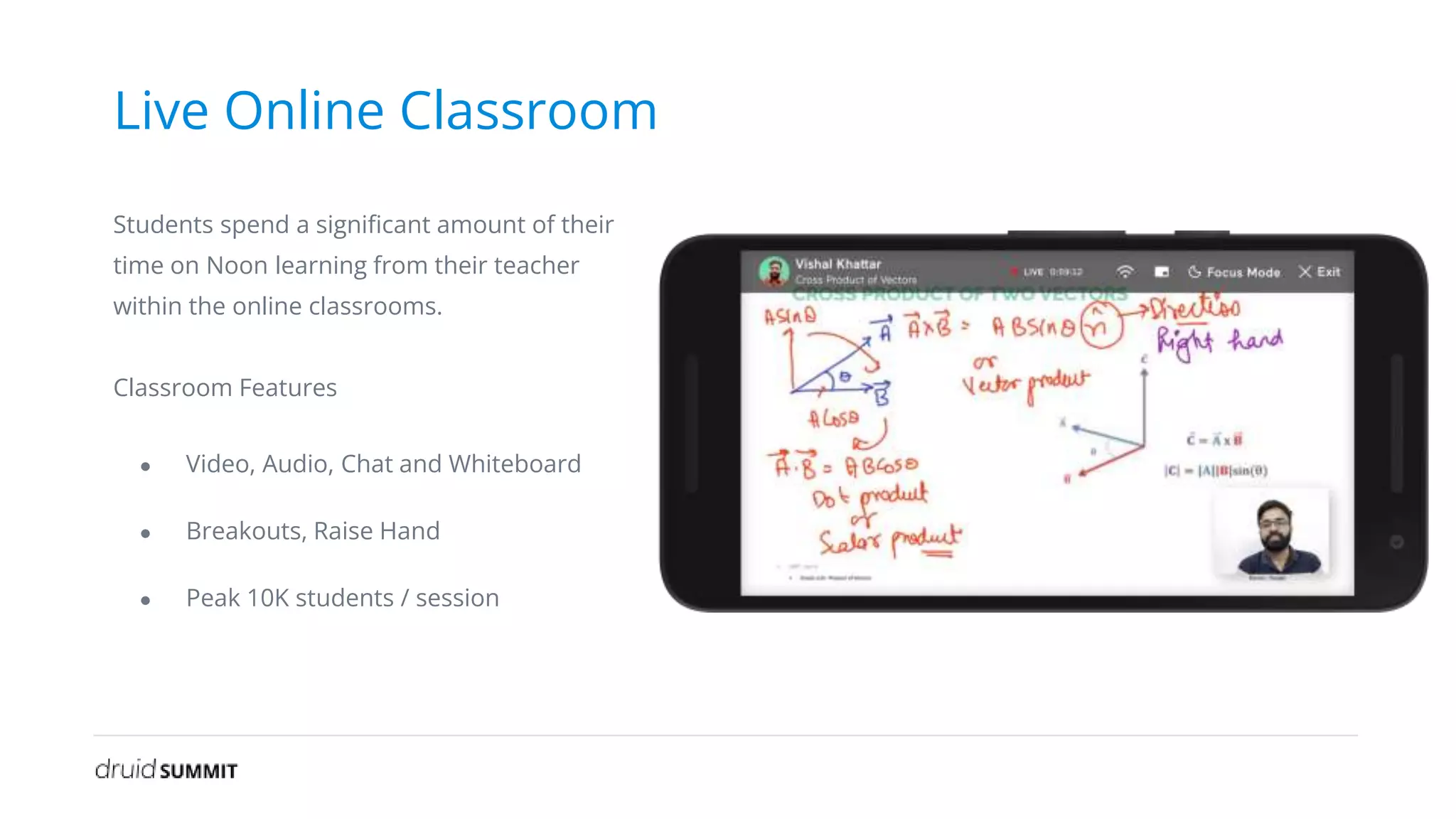
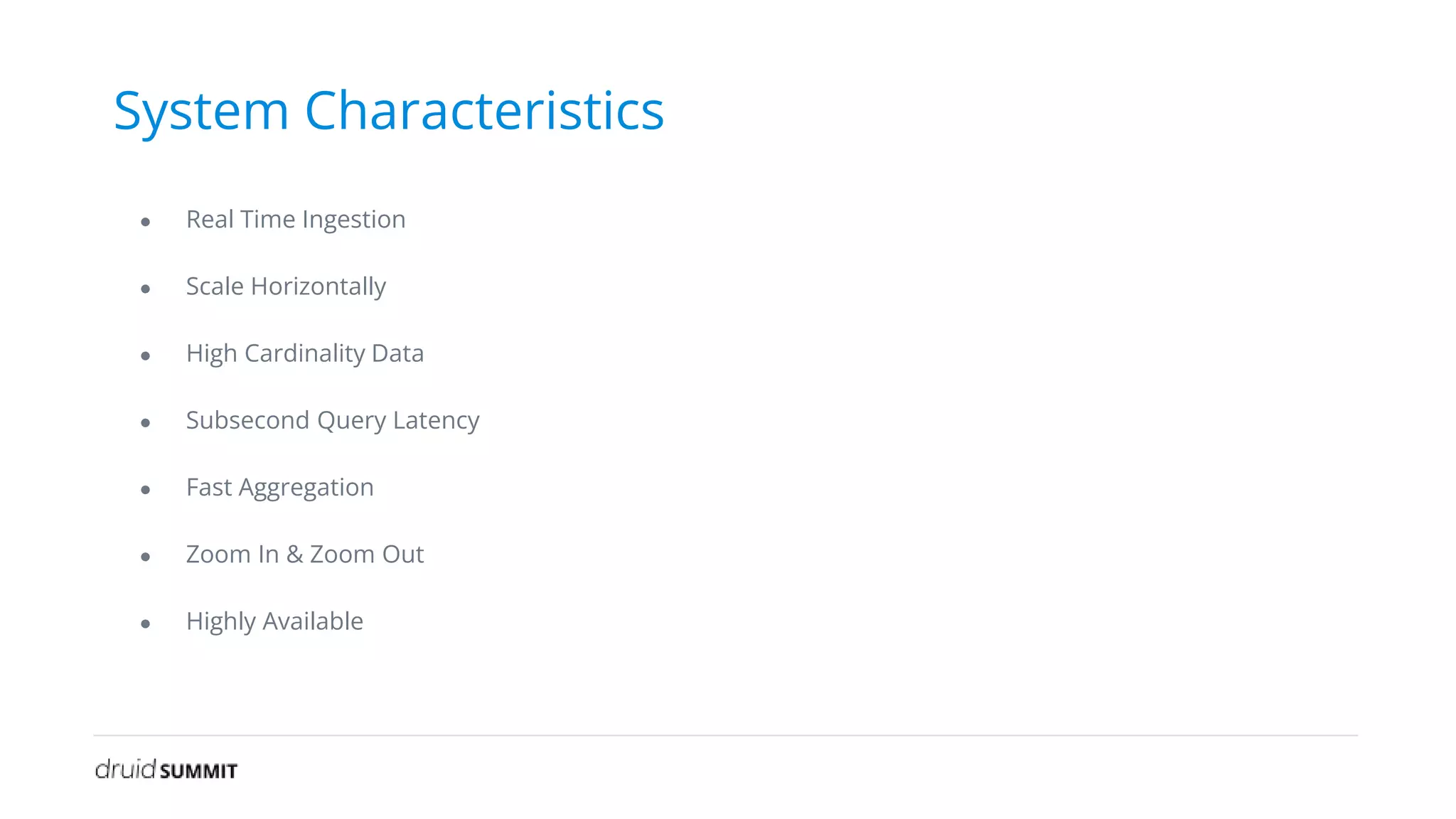
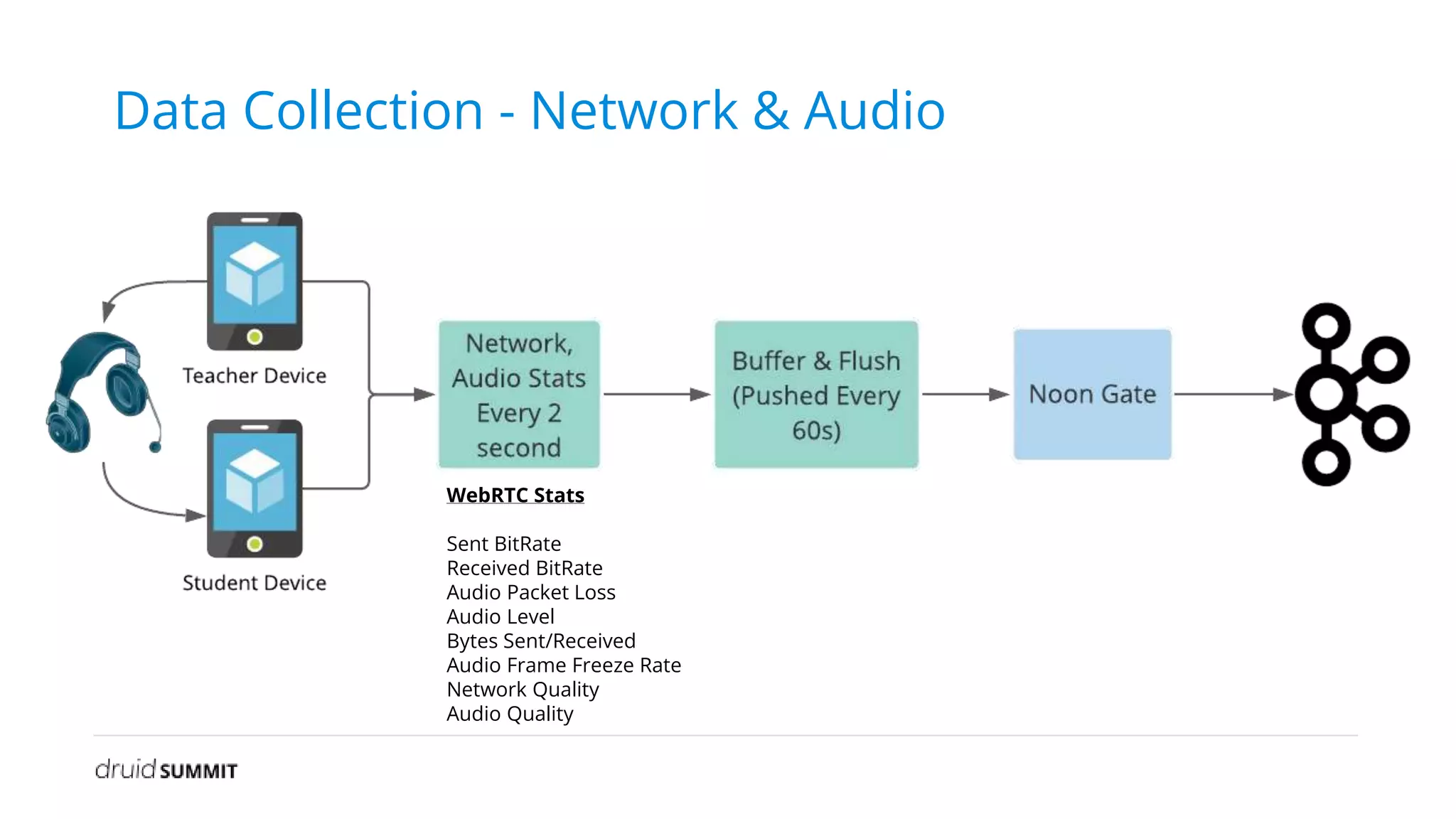
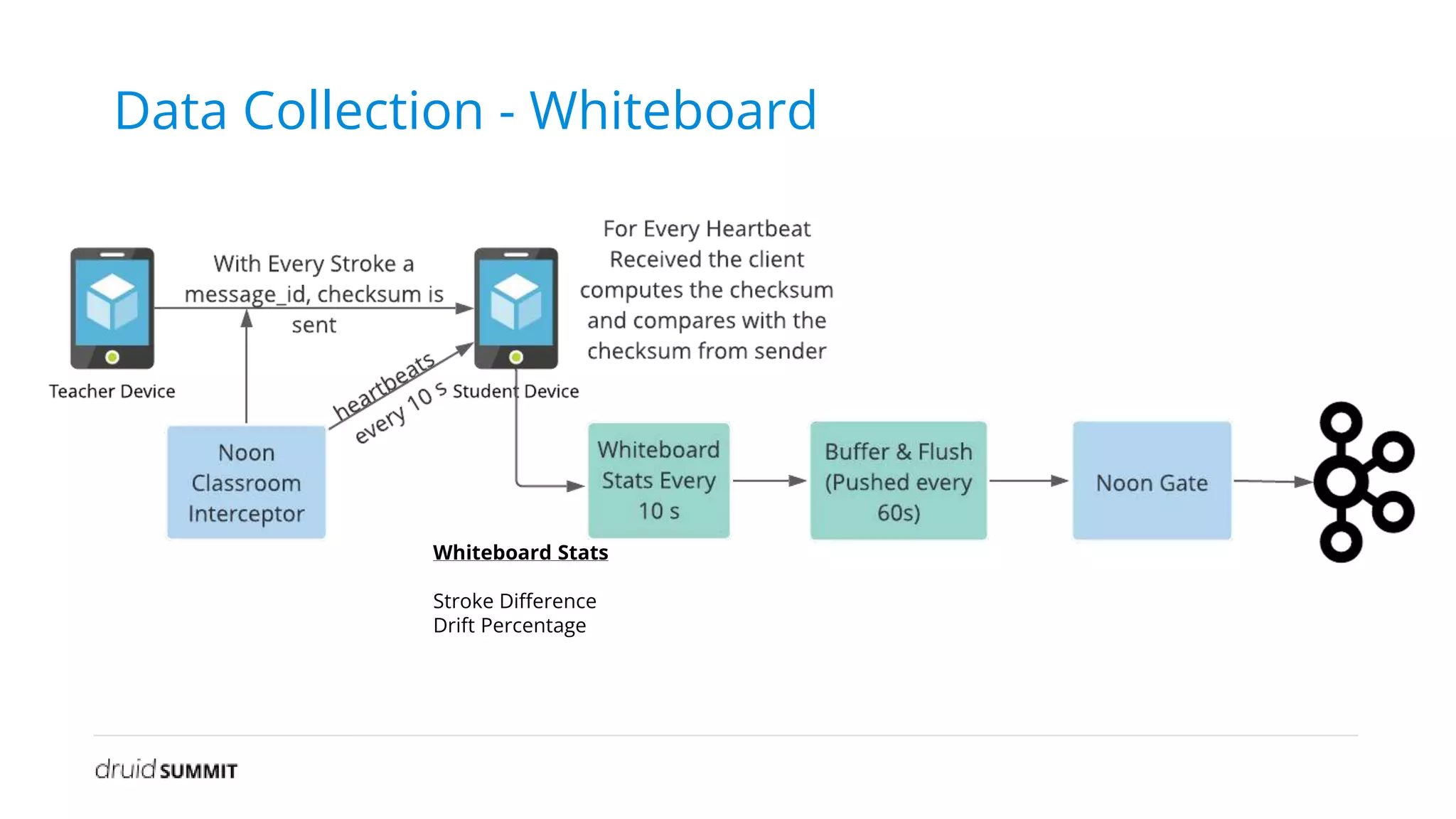
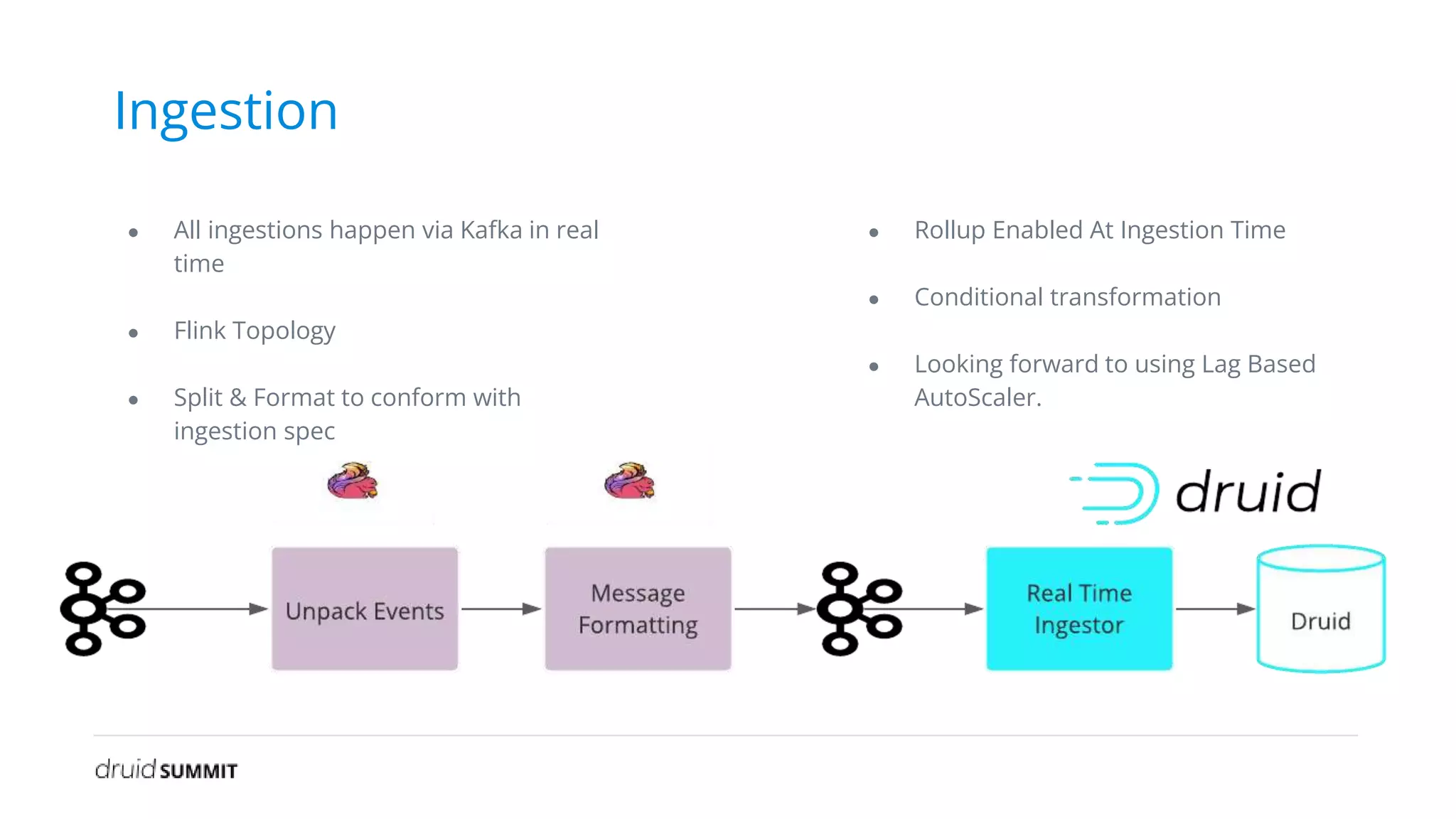
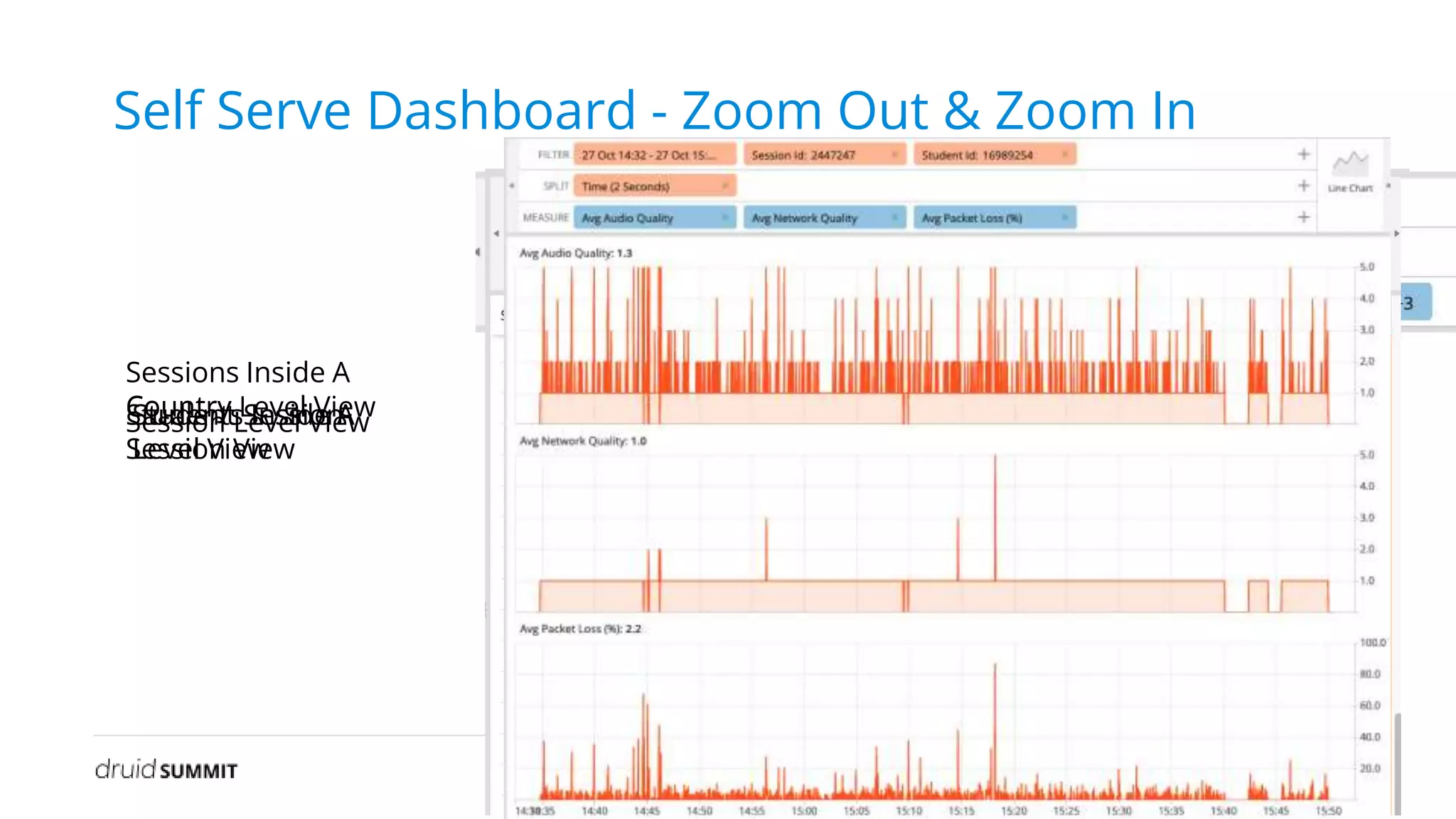
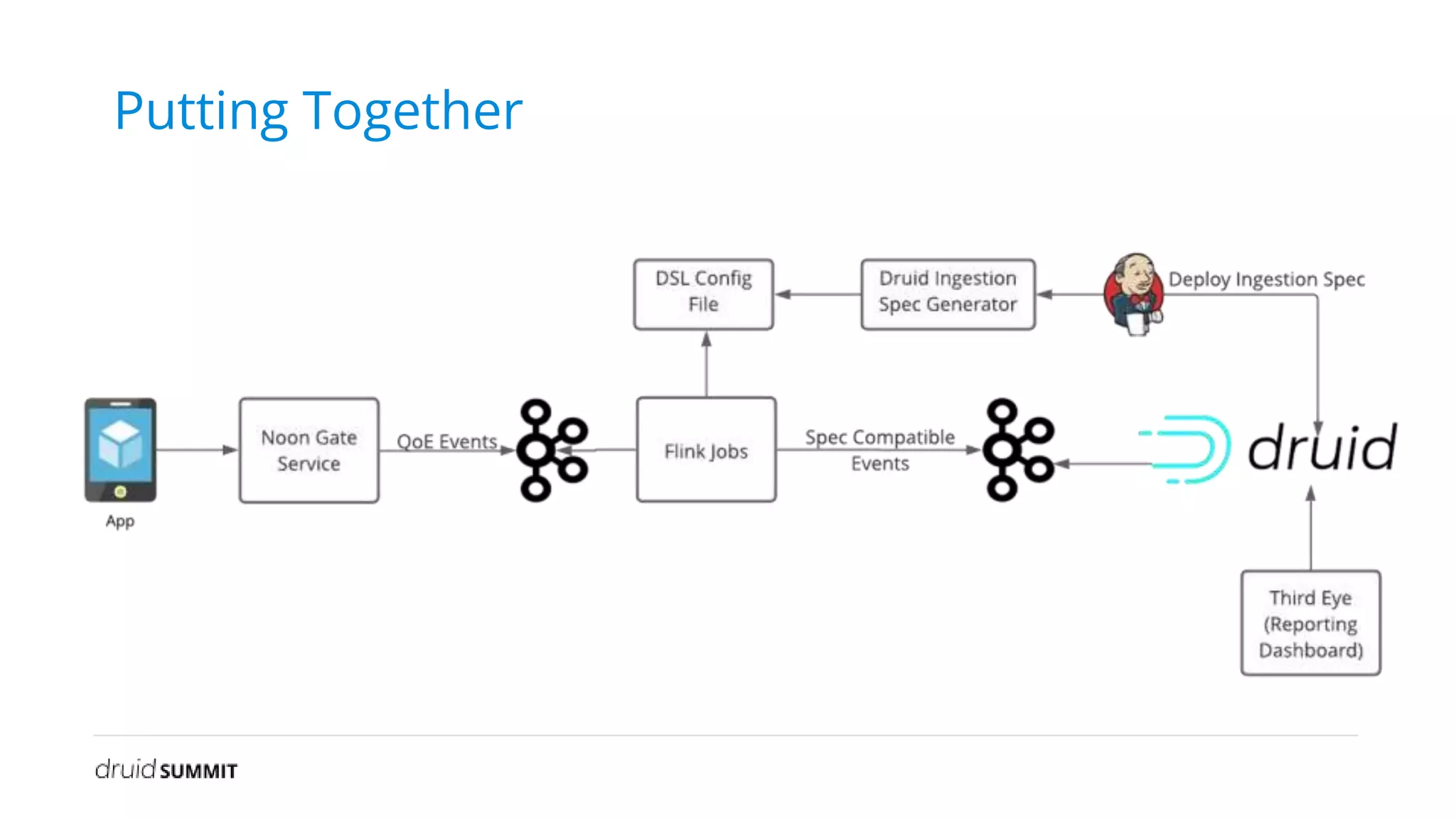
The document discusses Noon, a social learning platform utilizing Apache Druid for real-time classroom analytics to enhance the learning experience for over 10 million users. Key features include monitoring classroom metrics such as network quality and audio performance, as well as addressing technical challenges like audio lag and whiteboard issues. The implementation of Druid allows for fast, scalable, and efficient data ingestions and aggregations, significantly improving quality monitoring and student engagement.






























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















