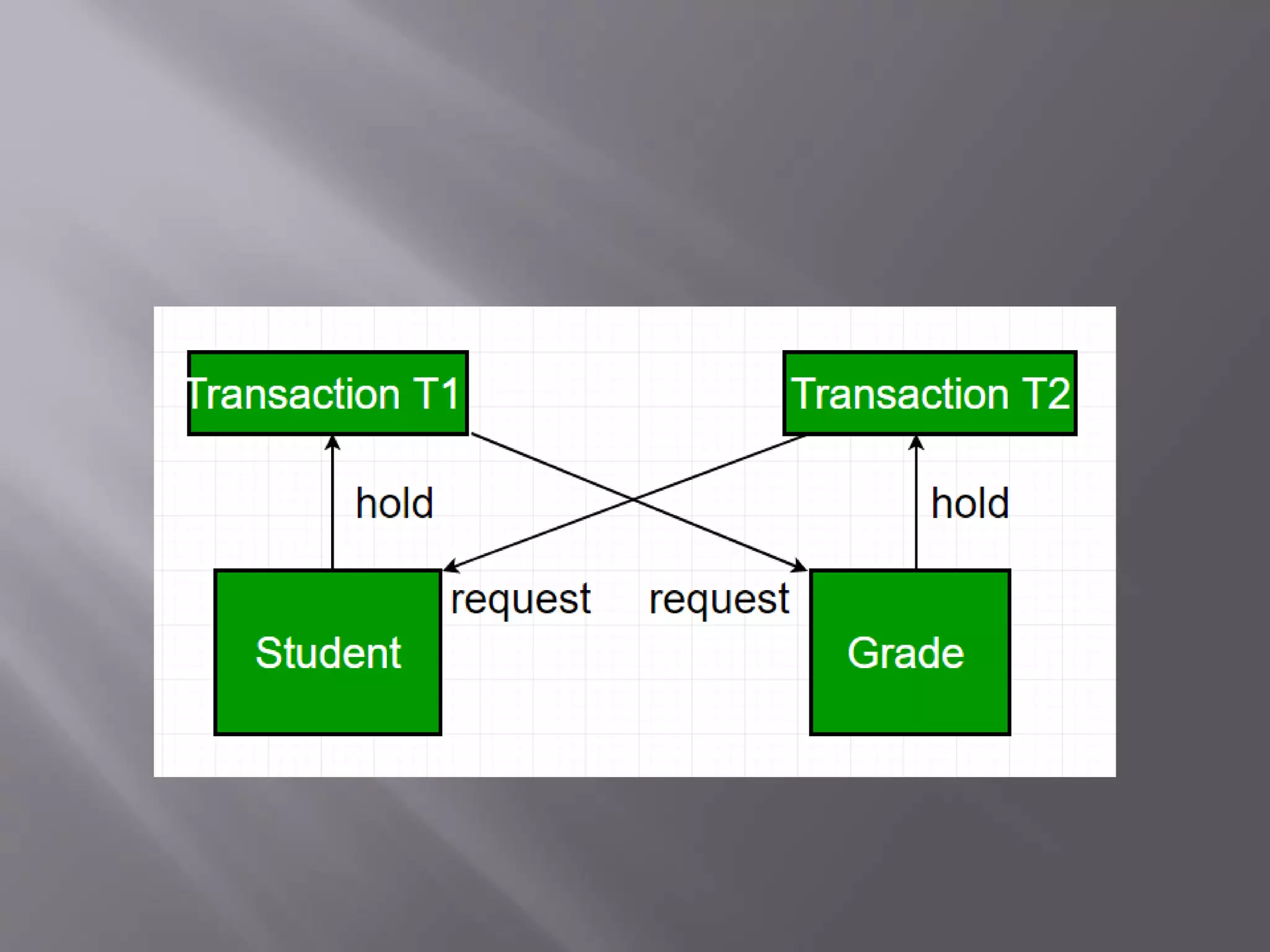
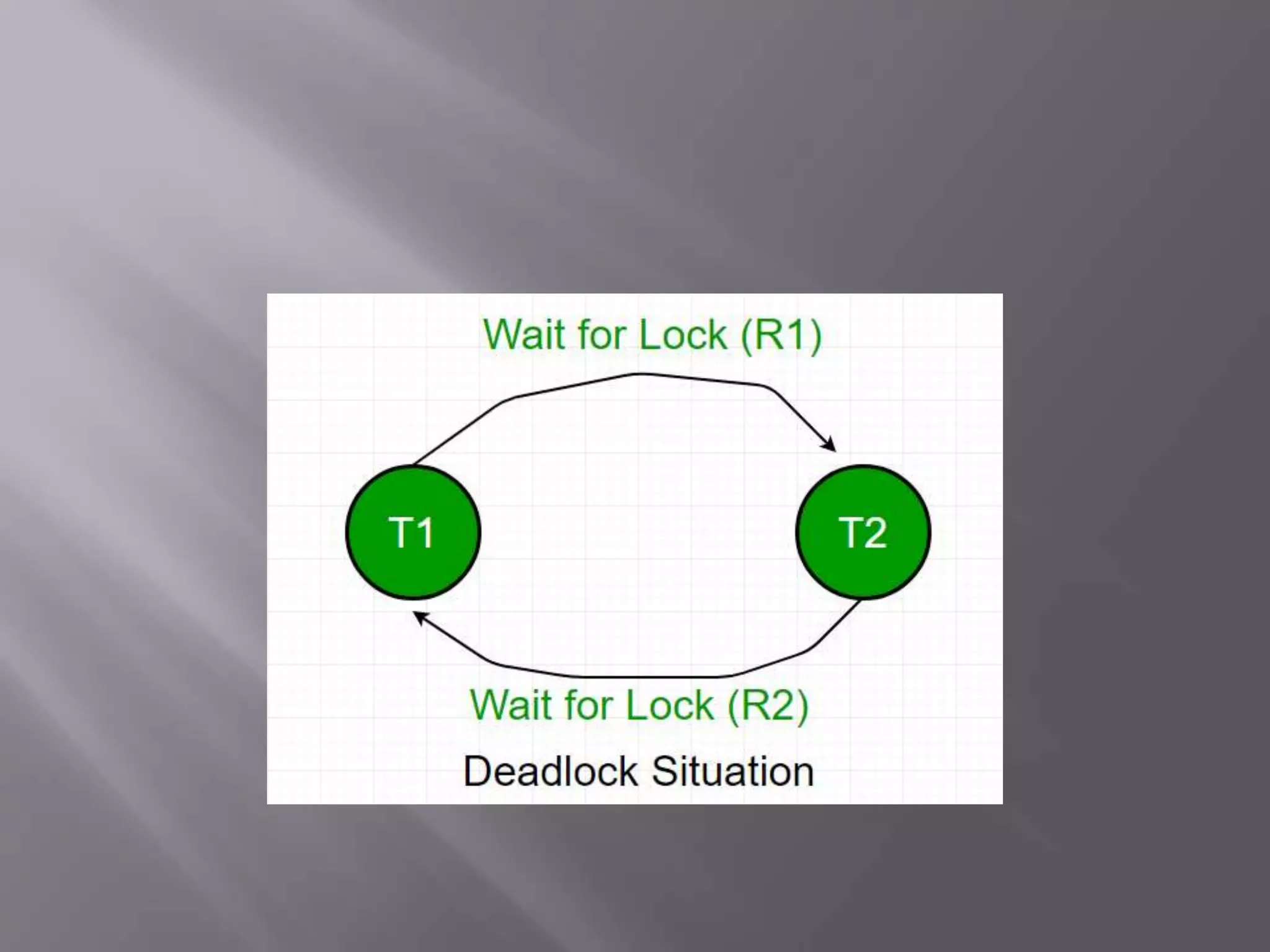
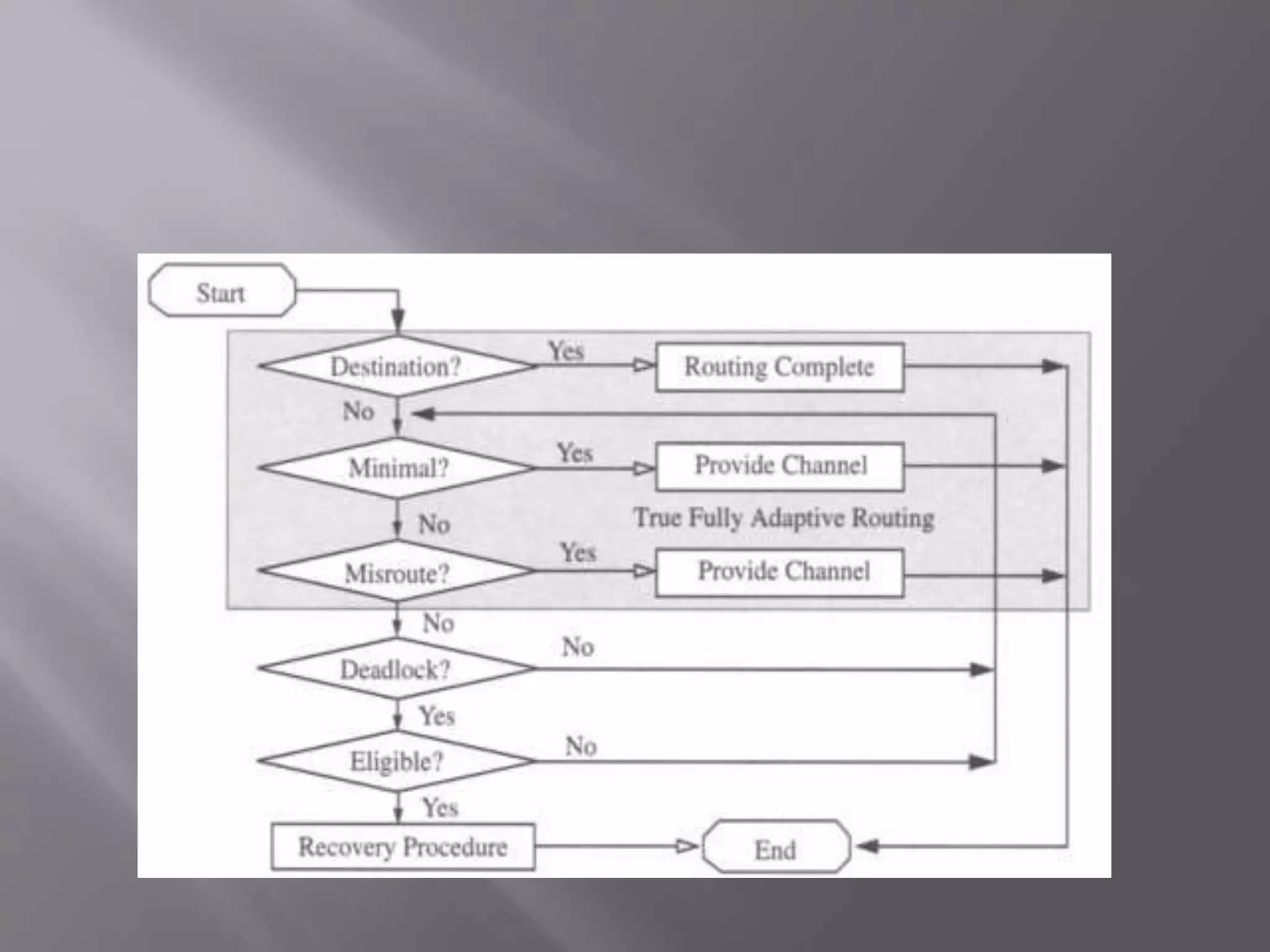
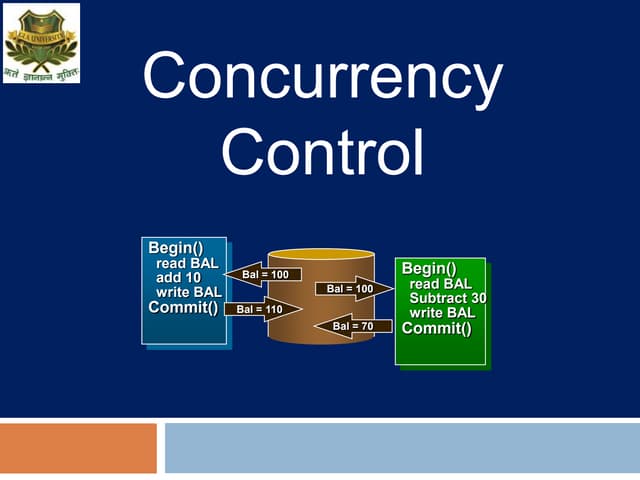
Deadlocks can occur in distributed database systems when transactions are waiting for data locked by other transactions across multiple sites. There are three main approaches to handle deadlocks - prevention, avoidance, and detection/removal. For avoidance and detection/removal, issues like transaction location and control must be addressed due to the distributed nature. Avoidance algorithms abort or wait younger transactions depending on a distributed wait-die or wound-wait approach. Detection builds global wait-for-graphs to detect cycles indicating deadlocks across sites.