Download as PDF, PPTX








![! Find anomalies in data, like: weird distribution of the
features, strange collected values, …
! Check how the ranking function performs before using
it in production: implement improvements, fix bugs, tune
parameters, …
! Save time and money. Put in production a bad ranking
function can worse the user experience on the website.
Advantages:
[Offline] A Business Perspective](https://image.slidesharecdn.com/chorus2021-rre-210128152832/75/Rated-Ranking-Evaluator-RRE-Hands-on-Relevance-Testing-Chorus-10-2048.jpg)



















![• DCG@K = Discounted Cumulative Gain@K
It measures the usefulness, or gain, of a document based
on its position in the result list.
Normalised Discounted Cumulative Gain
• NDCG@K = DCG@K/ Ideal DCG@K
• It is in the range [0,1]
Model1 Model2 Model3 Ideal
1 2 2 4
2 3 4 3
3 2 3 2
4 4 2 2
2 1 1 1
0 0 0 0
0 0 0 0
14.01 15.76 17.64 22.60
0.62 0.70 0.78 1.0
Normalized Discounted Cumulative Gain
relevance weight
result position
DCG
NDCG](https://image.slidesharecdn.com/chorus2021-rre-210128152832/75/Rated-Ranking-Evaluator-RRE-Hands-on-Relevance-Testing-Chorus-43-2048.jpg)


![• ERR@K = Expected Reciprocal Rank@K
It measures the probability of stopping at doc k, discounted
of the reciprocal of the position of a result
• It is in the range [0,1]
Expected Reciprocal Rank
Probability Relevance Grade
at rank r is satisfying
Probability Relevance grade
at rank I was not satisfying
probability at position i. Once the user is satisfied with
a document, he/she terminates the search and documents
below this result are not examined regardless of their posi-
tion. It is of course natural to expect Ri to be an increasing
function of the relevance grade, and indeed in what follows
we will assimilate it to the often loosely-defined notion of
“relevance”. This generic version of the cascade model is
summarized in Algorithm 1.
Algorithm 1 The cascade user model
Require: R1, . . . , R10 the relevance of the 10 URLs on the
result page.
1: i = 1
2: User examines position i.
3: if random(0,1) ≤ Ri then
4: User is satisfied with the document in position i and
stops.
5: else
6: i ← i + 1; go to 2
7: end if
Two instantiations of this model have been presented in
[12, 8]. In the former, Ri is the same as the attractiveness
defined above for position-based models: it measures a prob-
ability of click which can be interpreted as the relevance of
the snippet. In that model, it is assumed that the user is al-
with the gain function for DCG used in [4], we m
it to be:
R(g) :=
2g
− 1
2gmax
, g ∈ {0, . . . , gmax}.
When the document is non-relevant (g = 0), the p
that the user finds it relevant is 0, while when the
is extremely relevant (g = 4 if a 5 point scale is us
the probability of relevance is near 1.
We first define the metric in a more general wa
sidering a utility function ϕ of the position. This
typically satisfies ϕ(1) = 1 and ϕ(r) → 0 as r goes
Definition 1 (Cascade based metric). G
ity function ϕ, a cascade based metric is the expe
ϕ(r), where r is the rank where the user finds the
he was looking for. The underlying user model is th
model (2), where the Ri are given by (3).
In the rest of this paper we will be considering t
case ϕ(r) = 1/r, but there is nothing particular a
choice and, for instance, we could have instead pick
1
log2(r+1)
as in the discount function of DCG.
Definition 2 (Expected Reciprocal Ran
The Expected Reciprocal Rank is a cascade based m](https://image.slidesharecdn.com/chorus2021-rre-210128152832/75/Rated-Ranking-Evaluator-RRE-Hands-on-Relevance-Testing-Chorus-46-2048.jpg)











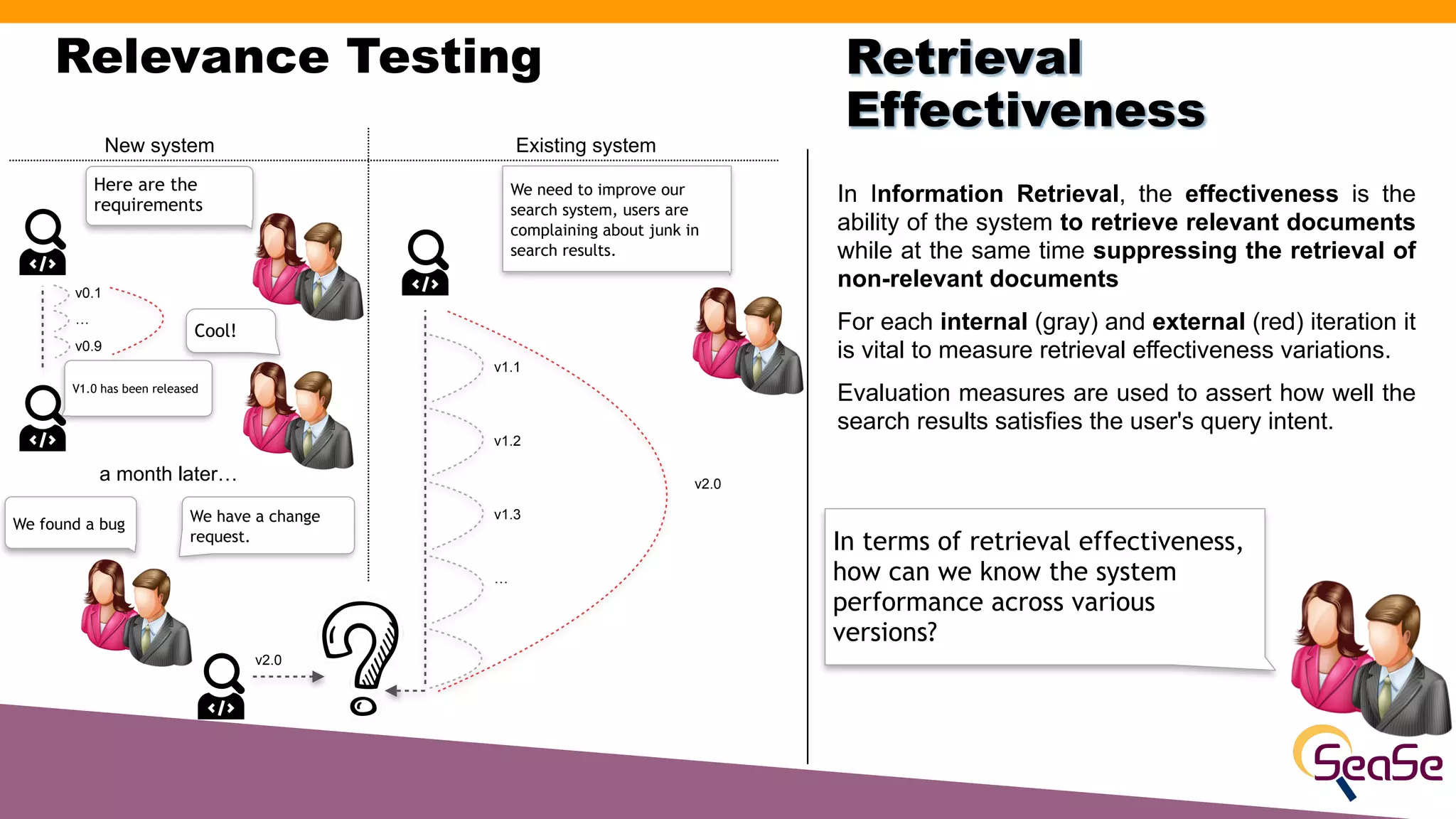
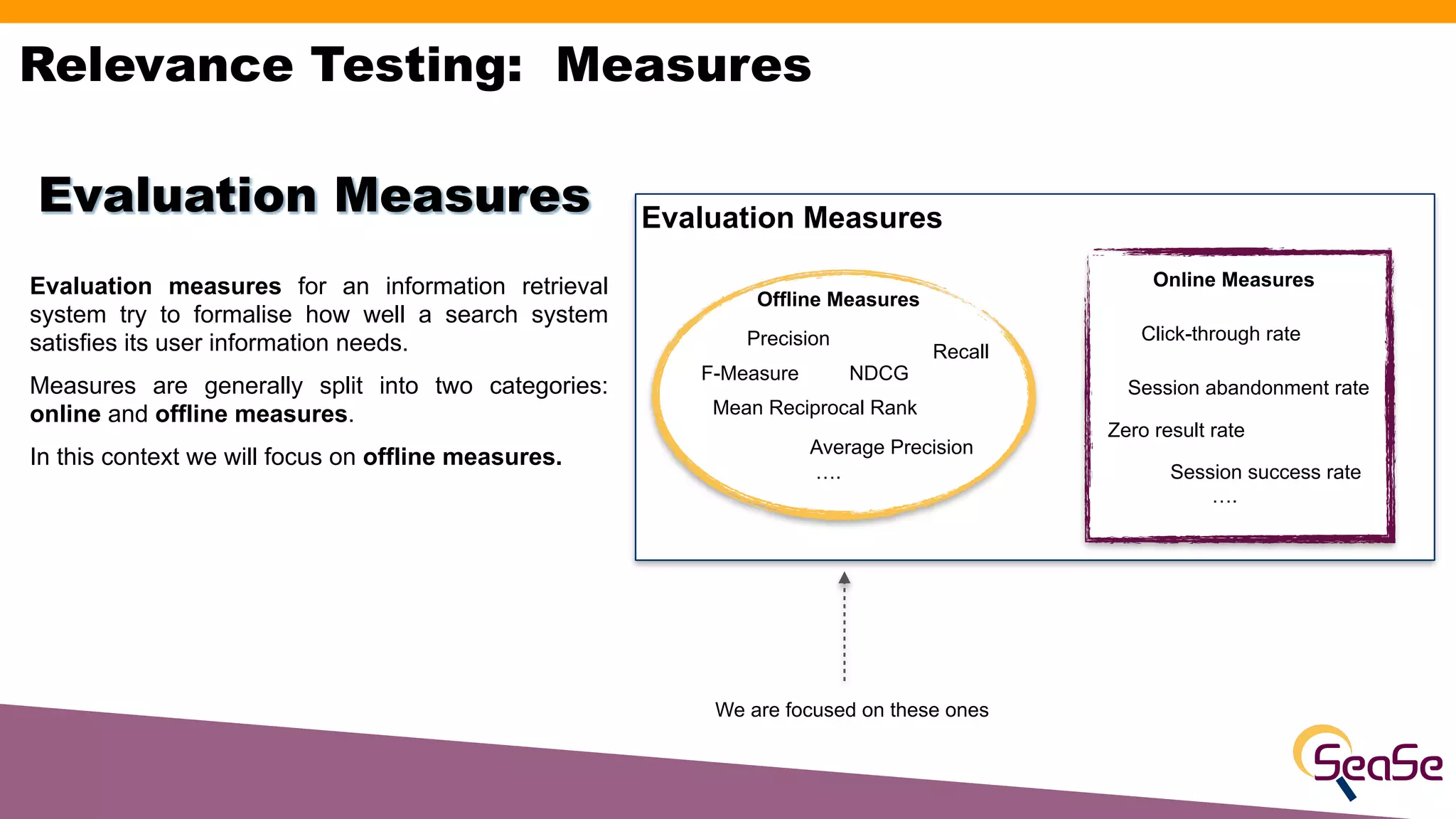
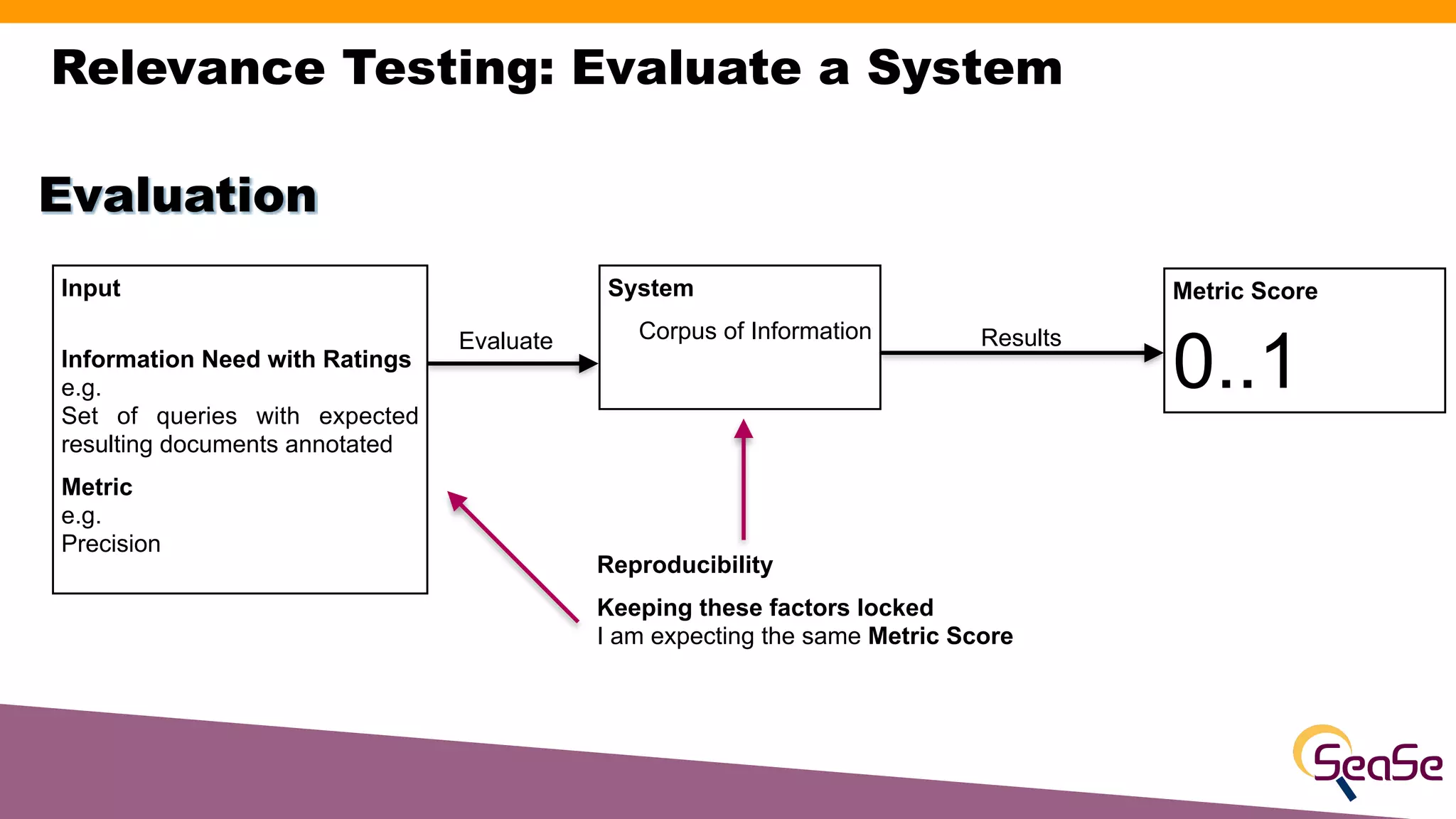
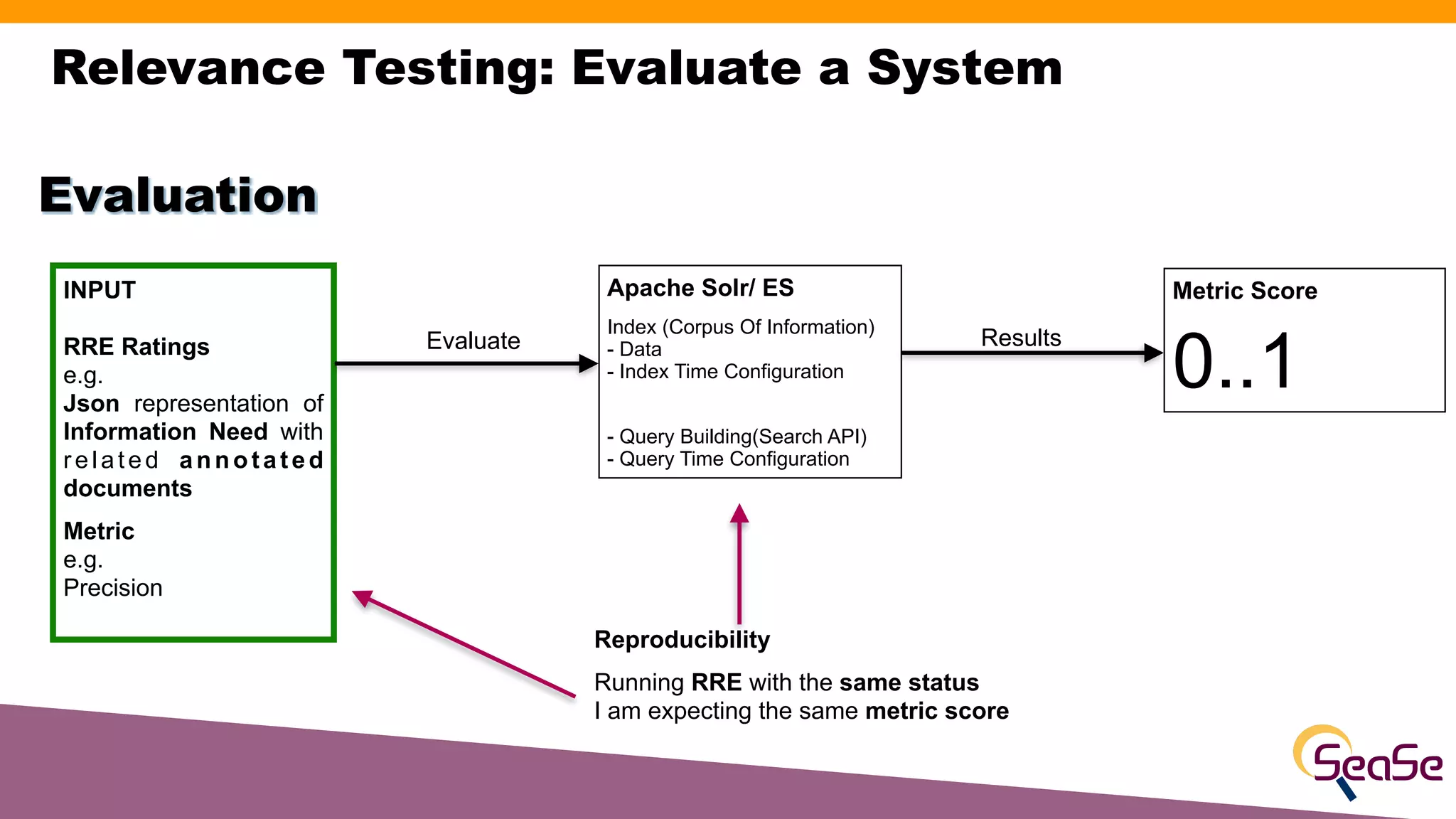
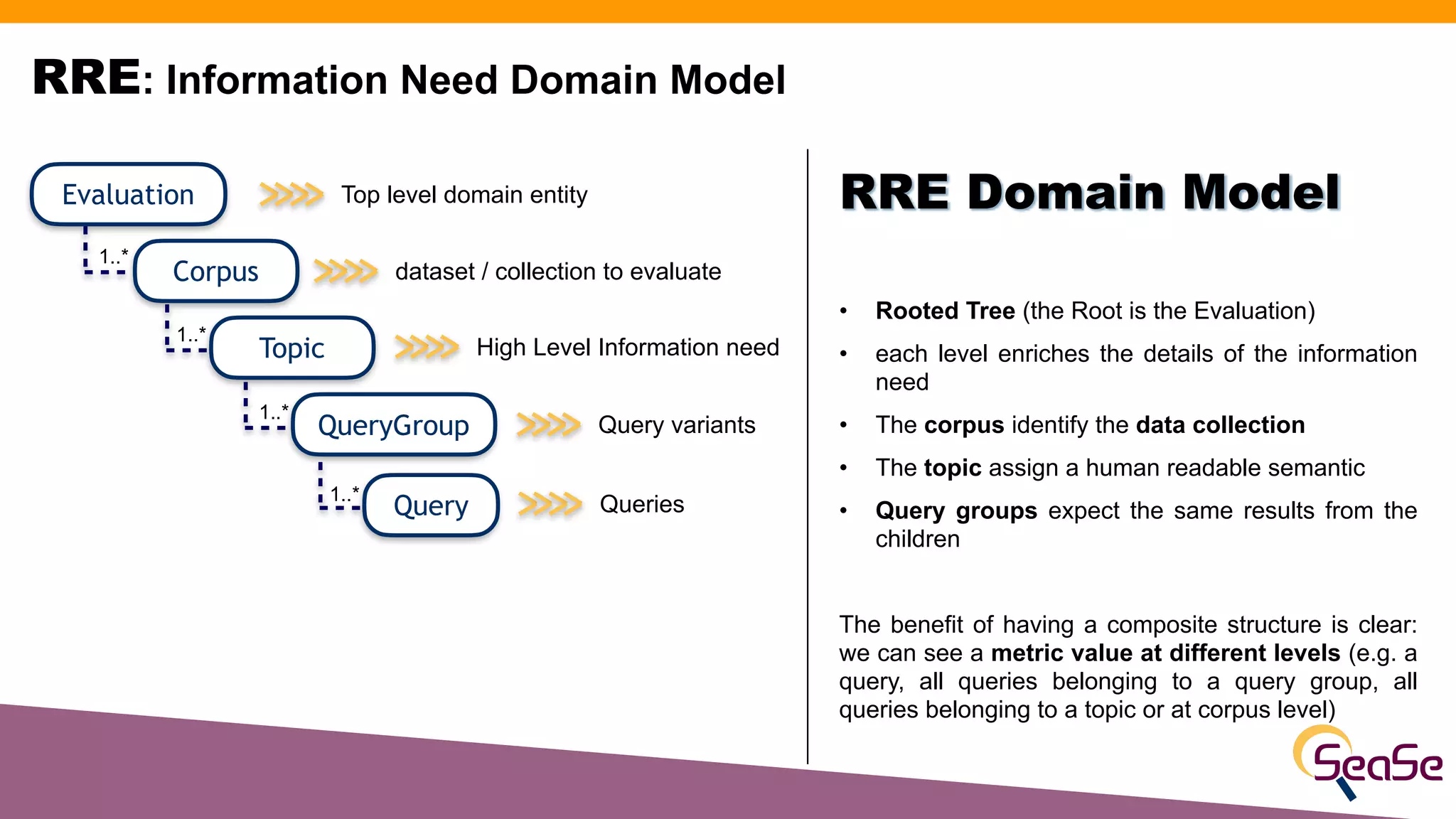
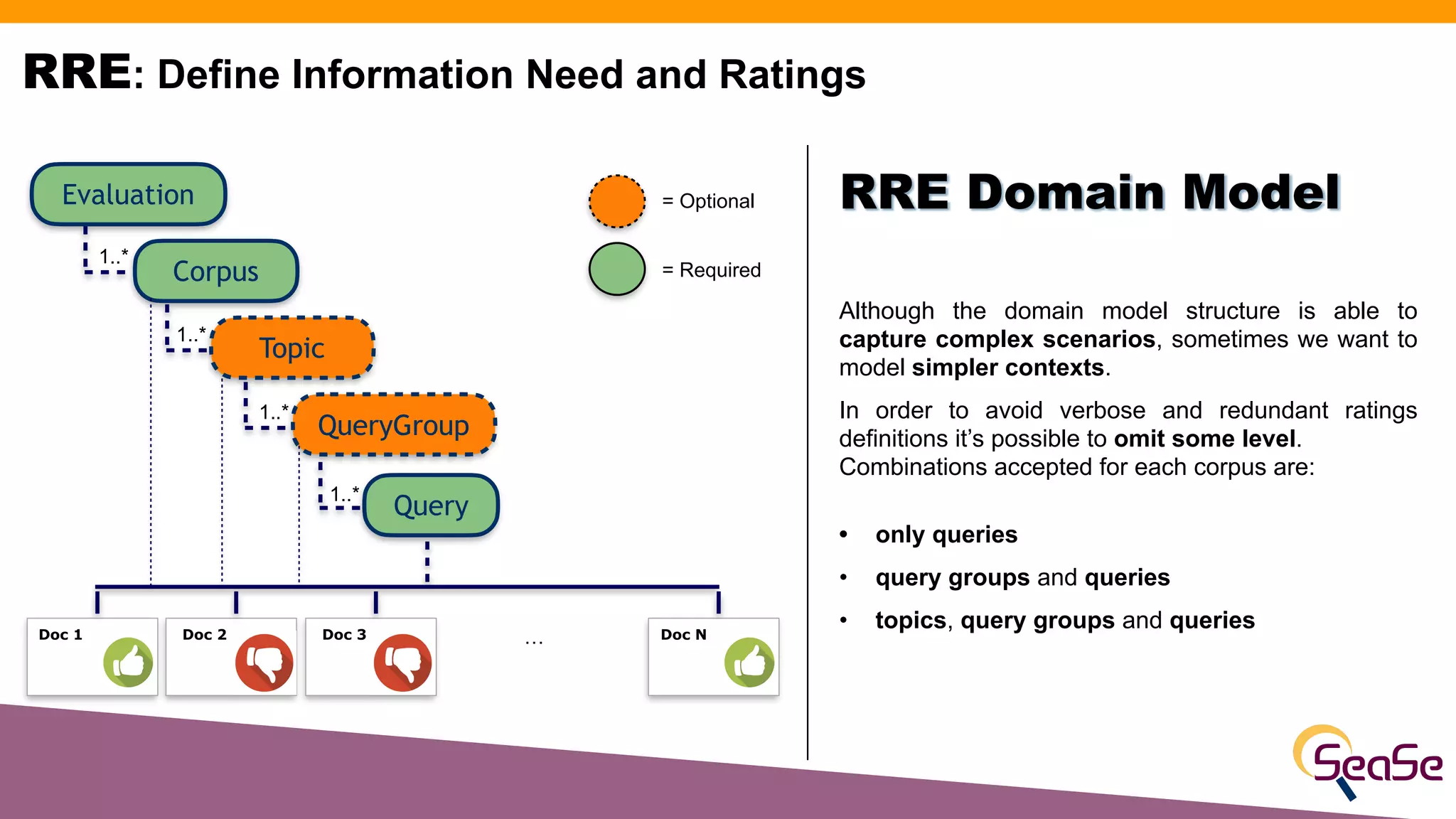
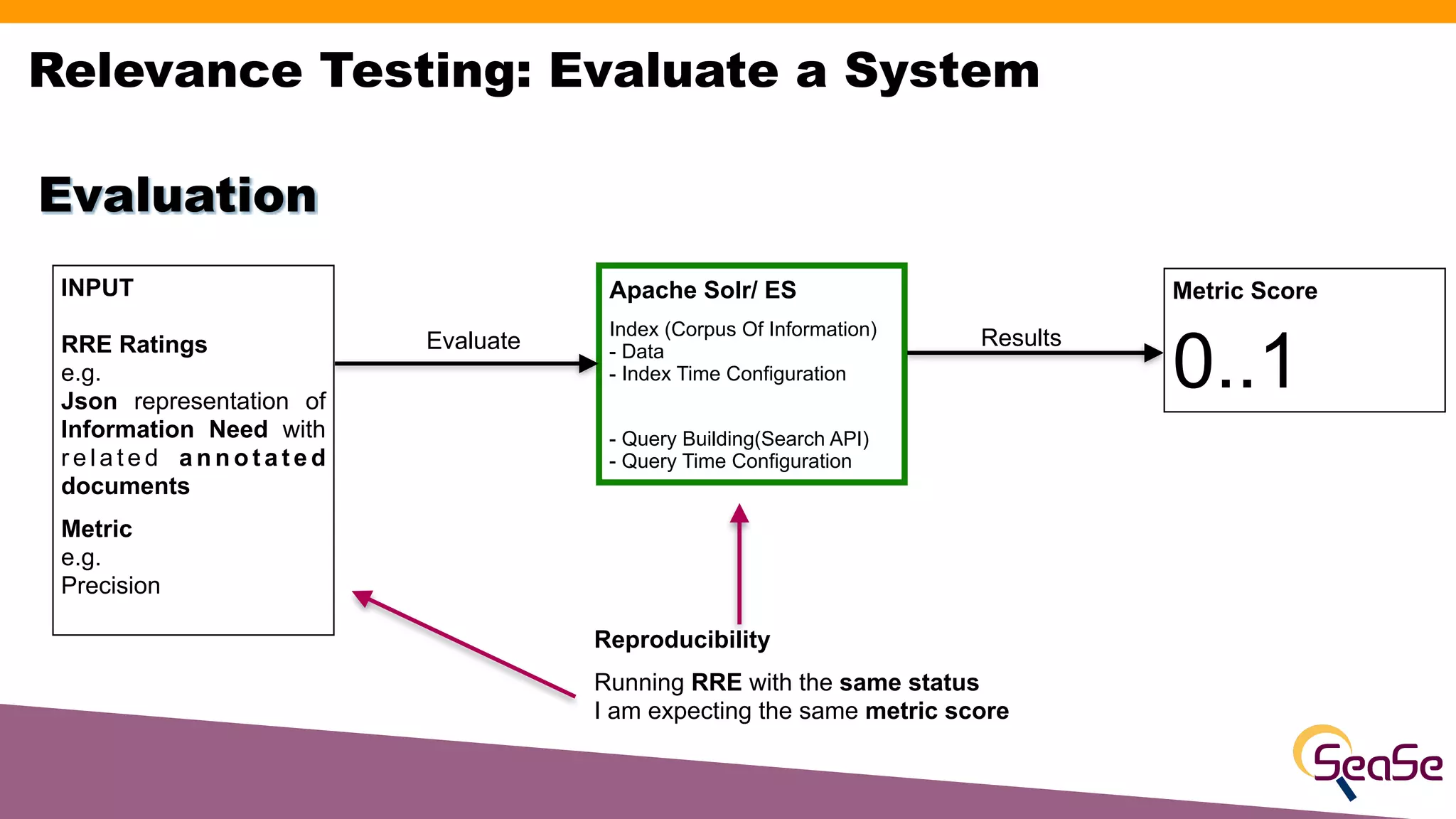
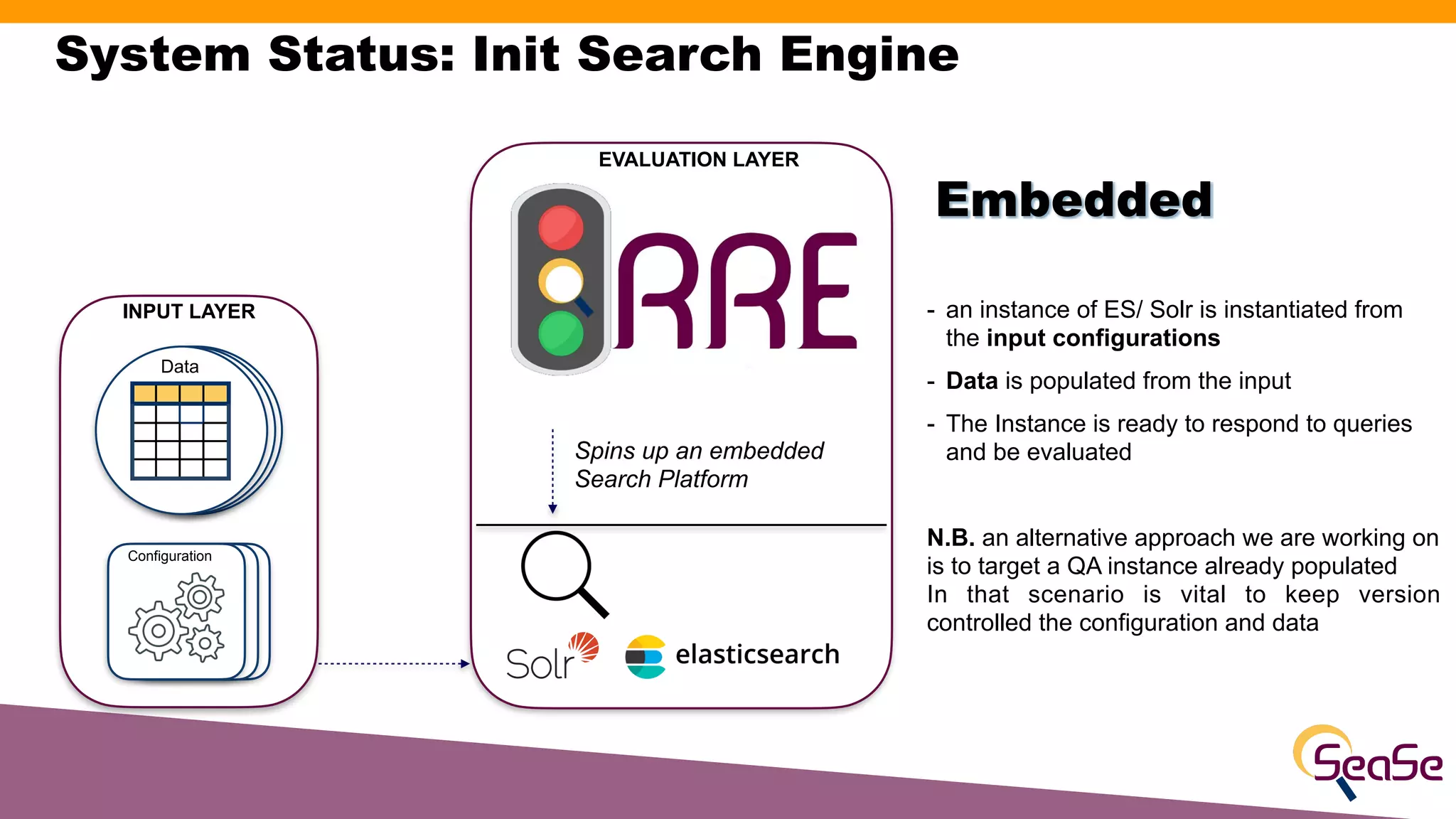
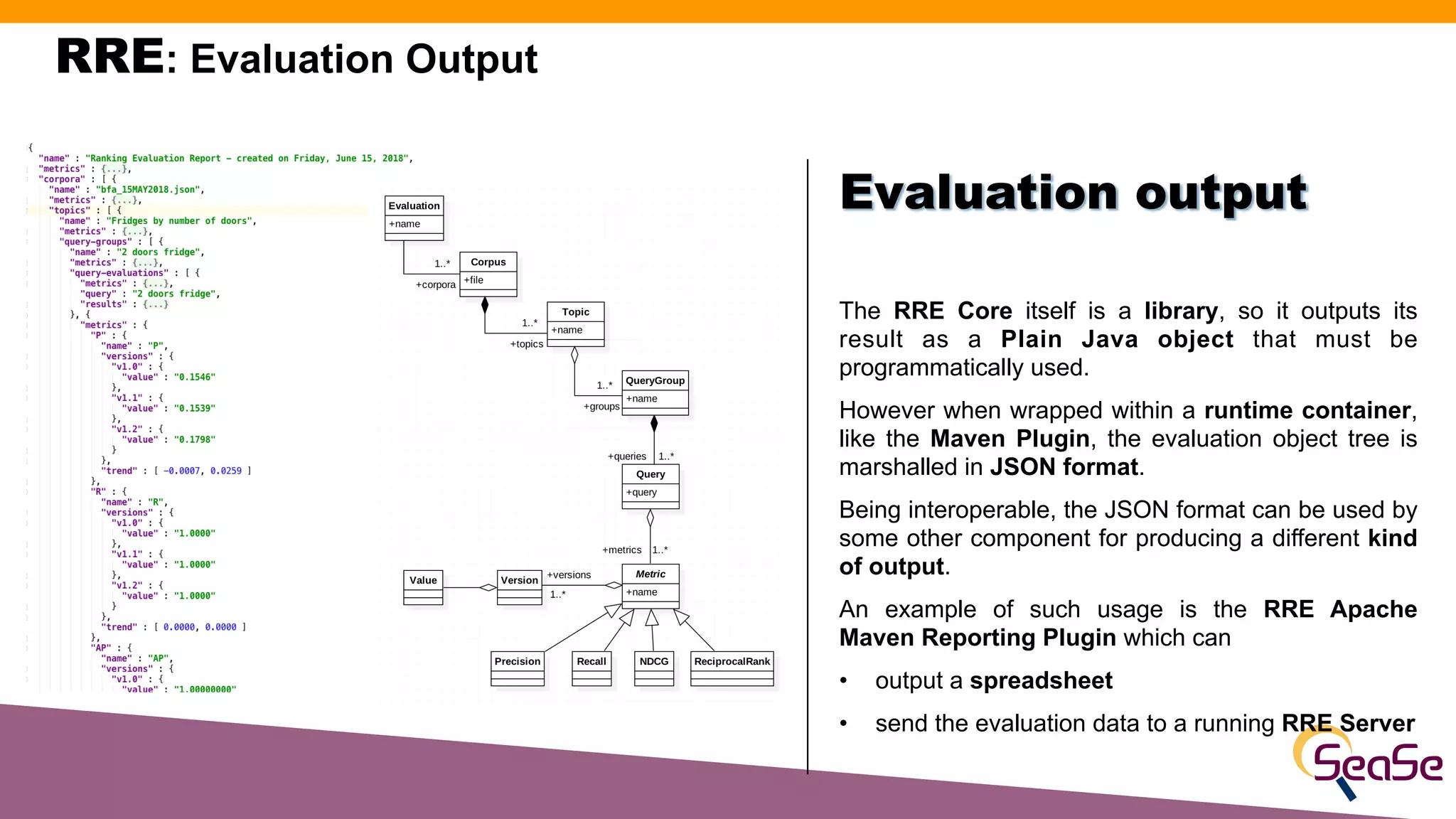
The document provides an overview of the Rated Ranking Evaluator (RRE), a framework developed for search quality evaluation focusing on relevance testing in information retrieval systems. It outlines the roles of the authors, the importance of relevance ratings, and various evaluation measures used to assess retrieval effectiveness across different versions of search systems, primarily targeting Apache Solr and Elasticsearch. Additionally, it discusses the implementation details, benefits, and planned future enhancements of the RRE framework.











![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)





























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)













