Download as PDF, PPTX







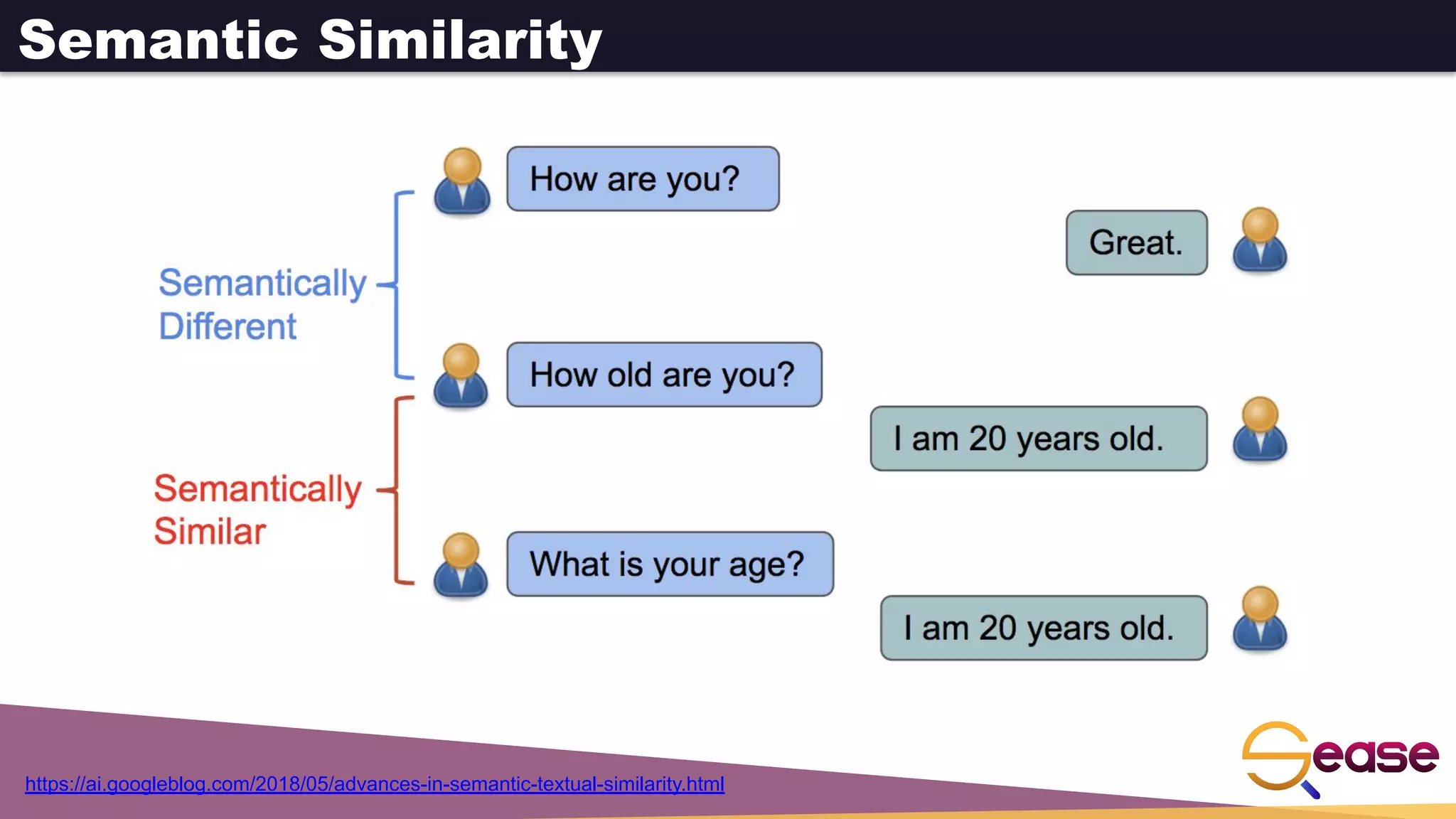

![Vector representation for query/documents
Sparse Dense
● e.g. Bag-of-words approach
● each term in the corpus
dictionary ->
one vector dimension
● number of dimensions ->
term dictionary cardinality
● the vector for any given
document contains mostly
zeroes
● Fixed number of dimensions
● Normally much lower than
term dictionary cardinality
● the vector for any given
document contains mostly
non-zeroes
How can you generate such
dense vectors?
D=[0, 0, 0, 0, 1, 0, 0, 0, 1, 0] D=[0.7, 0.9, 0.4, 0.6, 1, 0.4, 0.7, 0.8, 1, 0.9]](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-10-2048.jpg)






![org.apache.lucene.document.KnnVectorField
private static Field randomKnnVectorField
(Random random, String fieldName) {
VectorSimilarityFunction similarityFunction =
RandomPicks.randomFrom(random, VectorSimilarityFunction
.values());
float[] values = new float[randomIntBetween(1, 10)];
for (int i = 0; i < values.length; i++) {
values[i] = randomFloat();
}
return new KnnVectorField(fieldName, values, similarityFunction
);
}
Document doc = new Document();
doc.add(
new KnnVectorField(
"field", new float[] {j, j}, VectorSimilarityFunction
.EUCLIDEAN));
Apache Lucene - indexing](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-21-2048.jpg)

![org.apache.lucene.search.KnnVectorQuery
/**
* Find the <code>k</code> nearest documents to the target vector according to the
vectors in the
* given field. <code>target</code> vector.
*
* @param field a field that has been indexed as a {@link KnnVectorField}.
* @param target the target of the search
* @param k the number of documents to find
* @param filter a filter applied before the vector search
* @throws IllegalArgumentException if <code>k</code> is less than 1
*/
public KnnVectorQuery
(String field, float[] target, int k, Query filter) {
this.field = field;
this.target = target;
this.k = k;
if (k < 1) {
throw new IllegalArgumentException(
"k must be at least 1, got: " + k);
}
this.filter = filter;
}
Apache Lucene - searching](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-23-2048.jpg)

![Apache Solr 9.0 - Schema
DenseVectorField
The dense vector field gives the possibility of indexing and searching dense vectors of float elements.
For example:
[1.0, 2.5, 3.7, 4.1]
Here’s how DenseVectorField should be configured in the schema:
<fieldType name="knn_vector" class="solr.DenseVectorField" vectorDimension ="4"
similarityFunction ="cosine"/>
<field name="vector" type="knn_vector" indexed="true" stored="true"/>
vectorDimension
The dimension of the dense vector to
pass in.
Accepted values: Any integer < = 1024.
similarityFunction
Vector similarity function; used in
search to return top K most similar
vectors to a target vector.
Accepted values: euclidean,
dot_product or cosine.
● euclidean: Euclidean distance
● dot_product: Dot product
● cosine: Cosine similarity](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-25-2048.jpg)

![Apache Solr 9.0 - Indexing
JSON
[{ "id": "1",
"vector": [1.0, 2.5, 3.7,
4.1]
},
{ "id": "2",
"vector": [1.5, 5.5, 6.7,
65.1]
}
]
XML
<add>
<doc>
<field name="id">1</field>
<field name="vector">1.0</field>
<field name="vector">2.5</field>
<field name="vector">3.7</field>
<field name="vector">4.1</field>
</doc>
<doc>
<field name="id">2</field>
<field name="vector">1.5</field>
<field name="vector">5.5</field>
<field name="vector">6.7</field>
<field name="vector">65.1</field>
</doc>
</add>
SolrJ
final SolrClient client =
getSolrClient();
final SolrInputDocument d1 = new
SolrInputDocument();
d1.setField("id", "1");
d1.setField("vector",
Arrays.asList(1.0f, 2.5f, 3.7f,
4.1f));
final SolrInputDocument d2 = new
SolrInputDocument();
d2.setField("id", "2");
d2.setField("vector",
Arrays.asList(1.5f, 5.5f, 6.7f,
65.1f));
client.add(Arrays.asList(d1,
d2));
N.B. from indexing and
storing perspective a dense
vector field is not any
different from an array of float
elements](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-27-2048.jpg)
![Apache Solr 9.0 - Searching
knn Query Parser
The knn k-nearest neighbors query parser allows to find the k-nearest documents to the target vector
according to indexed dense vectors in the given field.
Required Default: none
Optional Default: 10
f
The DenseVectorField to search in.
topK
How many k-nearest results to return.
Here’s how to run a KNN search:
e.g.
&q={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-28-2048.jpg)
![Apache Solr 9.0-Searching with Filter Queries(fq)
When using knn in these scenarios make sure you have a clear understanding of how filter queries
work in Apache Solr:
The Ranked List of document IDs resulting from the main query q is intersected with the set of
document IDs deriving from each filter query fq.
e.g.
Ranked List from q=[ID1, ID4, ID2, ID10] <intersects> Set from fq={ID3, ID2, ID9, ID4}
= [ID4,ID2]
Usage with Filter Queries
The knn query parser can be used in filter queries:
&q=id:(1 2 3)&fq={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]
The knn query parser can be used with filter queries:
&q={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]&fq=id:(1 2 3)
N.B. this can be called ‘post filtering’, ‘pre filtering’ is coming in a future release](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-29-2048.jpg)
![Apache Solr 9.0 - Reranking
When using knn in re-ranking pay attention to the topK parameter.
The second pass score(deriving from knn) is calculated only if the document d from the first pass is
within the k-nearest neighbors(in the whole index) of the target vector to search.
This means the second pass knn is executed on the whole index anyway, which is a current
limitation.
The final ranked list of results will have the first pass score(main query q) added to the second pass
score(the approximated similarityFunction distance to the target vector to search) multiplied by a
multiplicative factor(reRankWeight).
Details about using the ReRank Query Parser can be found in the Query Re-Ranking section.
Usage as Re-Ranking Query
The knn query parser can be used to rerank first pass query results:
&q=id:(3 4 9 2)&rq={!rerank reRankQuery=$rqq reRankDocs=4
reRankWeight=1}&rqq={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]
N.B. pure re-scoring is coming in a later release](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-30-2048.jpg)
![Apache Solr 9.0 - Hybrid Dense/Sparse search
…/solr/dense/select?indent=true&q={!bool should=$clause1 should=$clause2}
&clause1={!type=field f=id v='901'}
&clause2={!knn f=vector topK=10}[0.4,0.5,0.3,0.6,0.8]
&fl=id,score,vector
"debug":{
"rawquerystring":"{!bool should=$clause1 should=$clause2}",
"querystring":"{!bool should=$clause1 should=$clause2}",
"parsedquery":"id:901
KnnVectorQuery(KnnVectorQuery:vector[0.4,...][10])",
"parsedquery_toString":"id:901 KnnVectorQuery:vector[0.4,...][10]",](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-31-2048.jpg)


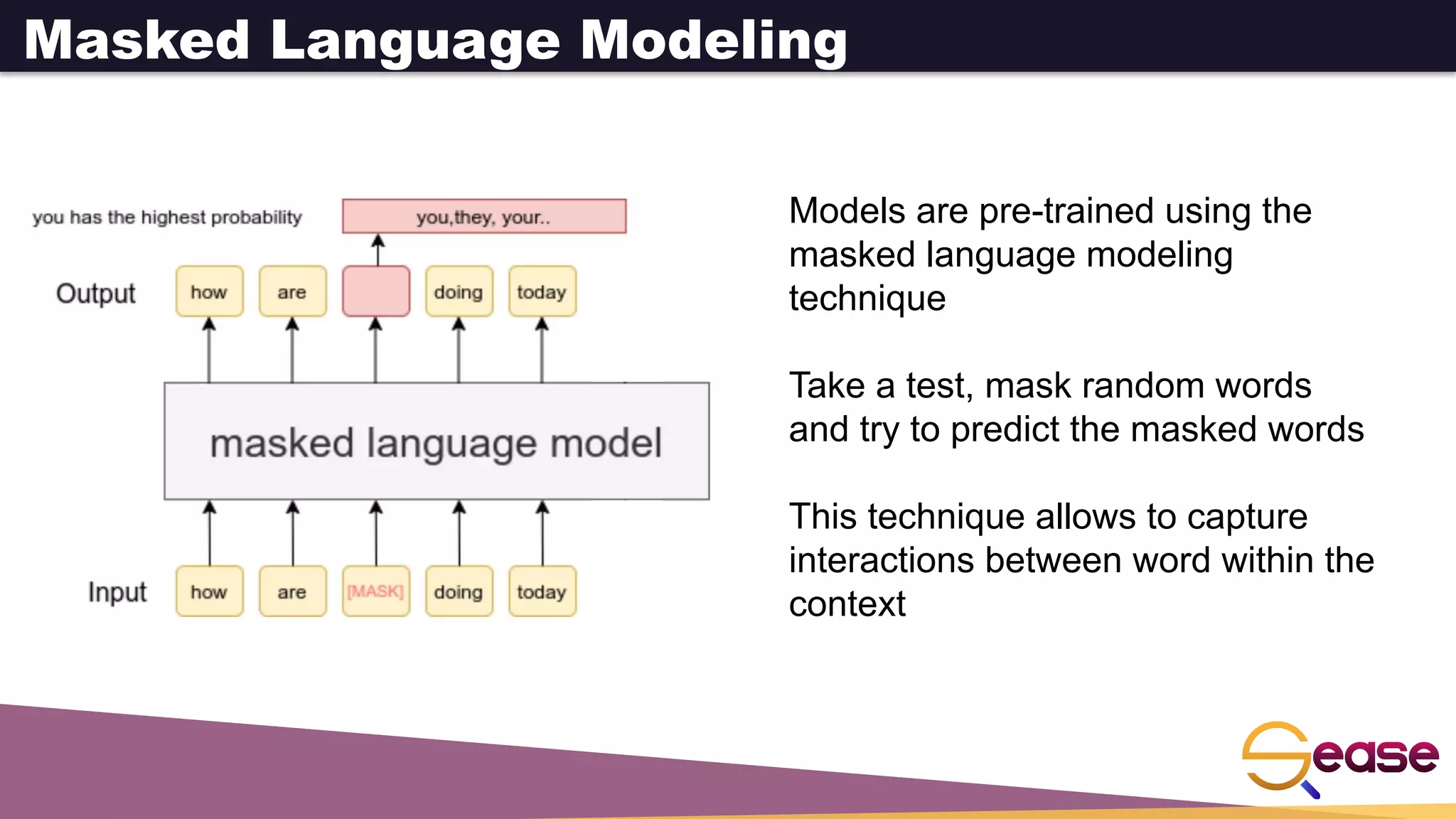
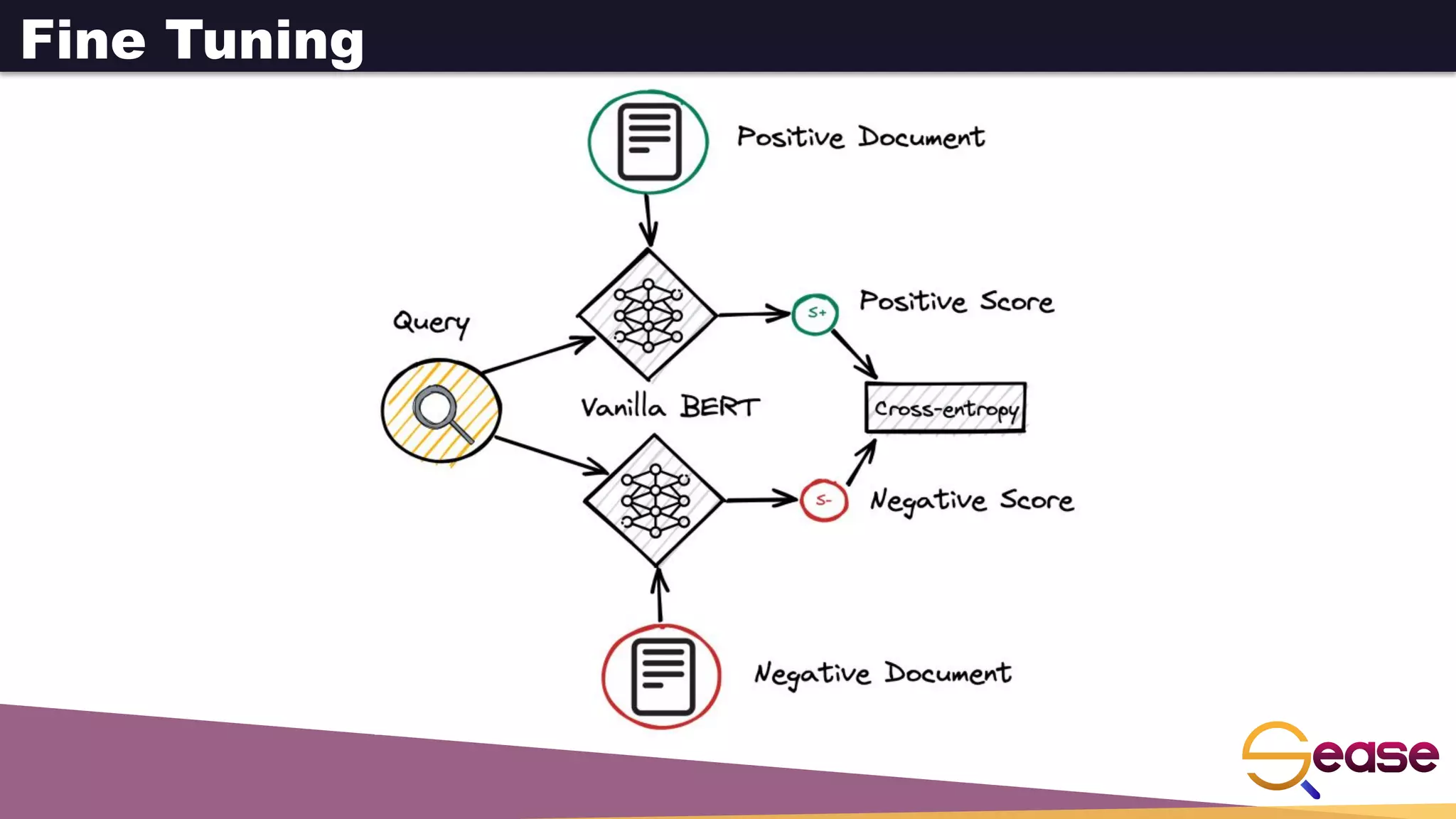
![Bidirectional Encoder Representations from Transformers
Large model (many dimensions and layers – base: 12 layers and
768 dim.)
Special tokens:
[CLS] Classification token, used as pooling operator to get a
single vector per sequence
[MASK] Used in the masked language model, to predict this
word
[SEP] Used to separate sentences
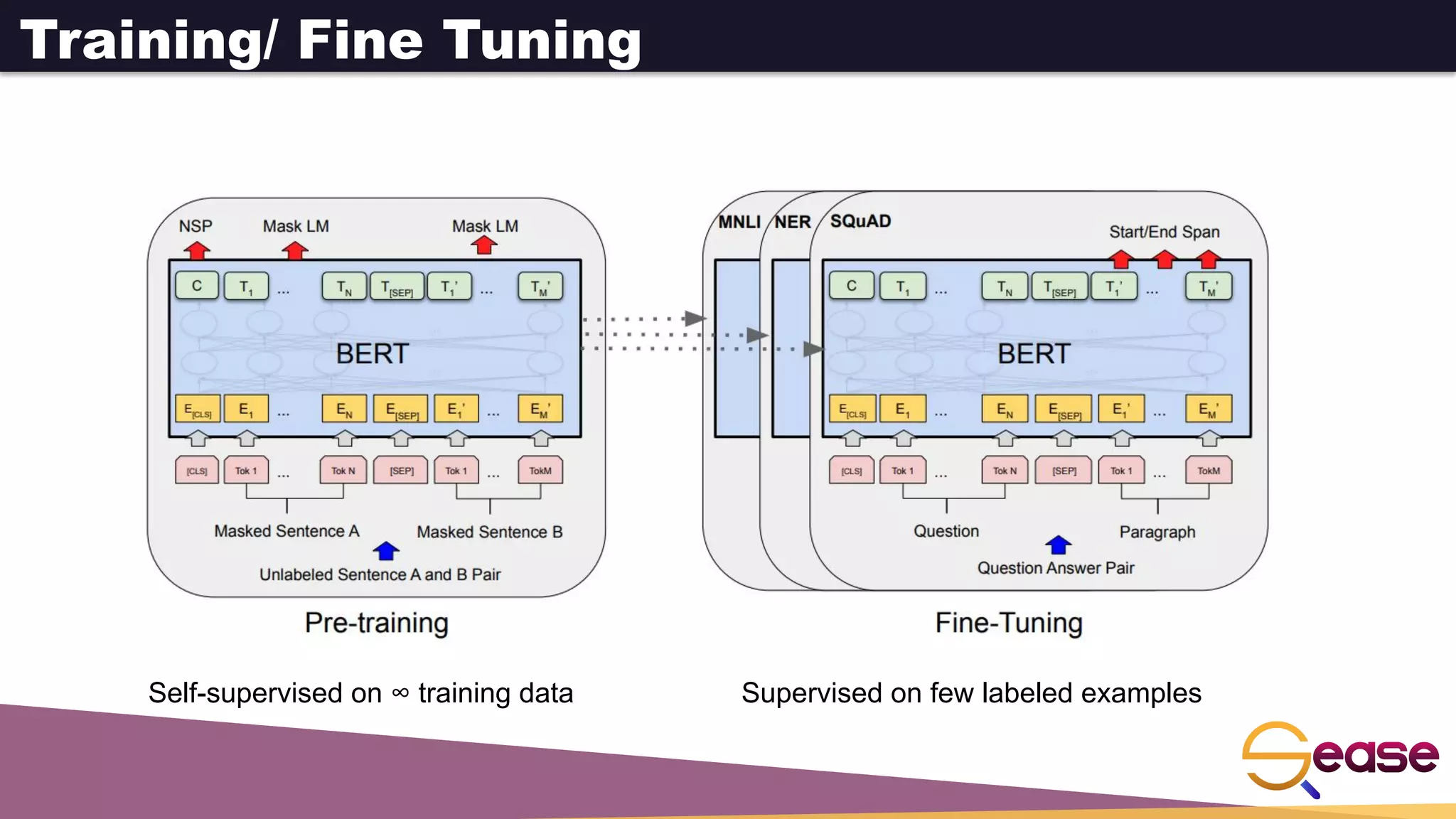
Devlin, Chang, Lee, Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019.
BERT to the rescue!
https://sease.io/2021/12/using-bert-to-improve-search-relevance.html](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-36-2048.jpg)
![From Text to Vectors
from sentence_transformers import SentenceTransformer
import torch
import sys
BATCH_SIZE = 50
MODEL_NAME = ‘msmarco-distilbert-base-dot-prod-v3’
model = SentenceTransformer(MODEL_NAME)
if torch.cuda.is_available():
model = model.to(torch.device(“cuda”))
def main():
input_filename = sys.argv[1]
output_filename = sys.argv[2]
create_embeddings(input_filename, output_filename)
https://pytorch.org
https://pytorch.org/tutorials/beginne
r/basics/quickstart_tutorial.html
https://www.sbert.net
https://www.sbert.net/docs/pretrain
ed_models.html](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-39-2048.jpg)
![From Text to Vectors
def create_embeddings(input_filename, output_filename):
with open(input_filename, ‘r’, encoding=“utf-8") as f:
with open(output_filename, ‘w’) as out:
processed = 0
sentences = []
for line in f:
sentences.append(line)
if len(sentences) == BATCH_SIZE:
processed += 1
if (processed % 1000 == 0):
print(“processed {} documents”.format(processed))
vectors = process(sentences)
for v in vectors:
out.write(‘,’.join([str(i) for i in v]))
out.write(‘n’)
sentences = []
Each line in the
input file is a
sentence.
In this example we
consider each
sentence a
separate
document to be
indexed in Apache
Solr.](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-40-2048.jpg)
![From Text to Vectors
def process(sentences):
embeddings = model.encode(sentences, show_progress_bar=True)
return embeddings
embeddings is an
array [] of vectors
Each vector
represents a
sentence](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-41-2048.jpg)

![Future Works: [Solr] Codec Agnostic
May 2022 - Apache Lucene 9.1 in Apache Solr
https://issues.apache.org/jira/browse/SOLR-16204
https://issues.apache.org/jira/browse/SOLR-16245
Currently it is possible to configure the codec to use for the HNSW
implementation in Lucene.
The proposal is to change this so that the user can only configure
the algorithm (HNSW now and default, maybe IVFFlat in the future?
https://issues.apache.org/jira/browse/LUCENE-9136)
<fieldType name="knn_vector"
class="solr.DenseVectorField"
vectorDimension="4"
similarityFunction="cosine"
codecFormat="Lucene90HnswVecto
rsFormat"
hnswMaxConnections="10"
hnswBeamWidth="40"/>](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-43-2048.jpg)
![Future Works: [Solr] Pre-filtering
Mar 2022 - Apache Lucene 9.1
Pre filters with KNN queries
https://issues.apache.org/jira/browse/LUCENE-10382
https://issues.apache.org/jira/browse/SOLR-16246
This PR adds support for a query filter in KnnVectorQuery. First, we gather the
query results for each leaf as a bit set. Then the HNSW search skips over the
non-matching documents (using the same approach as for live docs). To prevent
HNSW search from visiting too many documents when the filter is very selective,
we short-circuit if HNSW has already visited more than the number of documents
that match the filter, and execute an exact search instead. This bounds the
number of visited documents at roughly 2x the cost of just running the exact
filter, while in most cases HNSW completes successfully and does a lot better.](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-44-2048.jpg)
![Future Works: [Lucene] VectorSimilarityFunction simplification
https://issues.apache.org/jira/browse/LUCENE-10593
The proposal in this Pull Request aims to:
1) the Euclidean similarity just returns the score, in line with the other similarities, with the
formula currently used
2) simplify the code, removing the bound checker that's not necessary anymore
3) refactor here and there to be in line with the simplification
4) refactor of NeighborQueue to clearly state when it's a MIN_HEAP or MAX_HEAP, now
debugging is much easier and understanding the HNSW code is much more intuitive](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-45-2048.jpg)
![Future Works: [Solr] BERT Integration
We are planning to contribute:
1) an update request processor, that takes in input a BERT model and does the inference
vectorization at indexing time
2) a query parser, that takes in input a BERT model and does the inference vectorization at
query time](https://image.slidesharecdn.com/denseretrievalwithapachesolrneuralsearch-220726110953-d4a2510a/75/Dense-Retrieval-with-Apache-Solr-Neural-Search-pdf-46-2048.jpg)



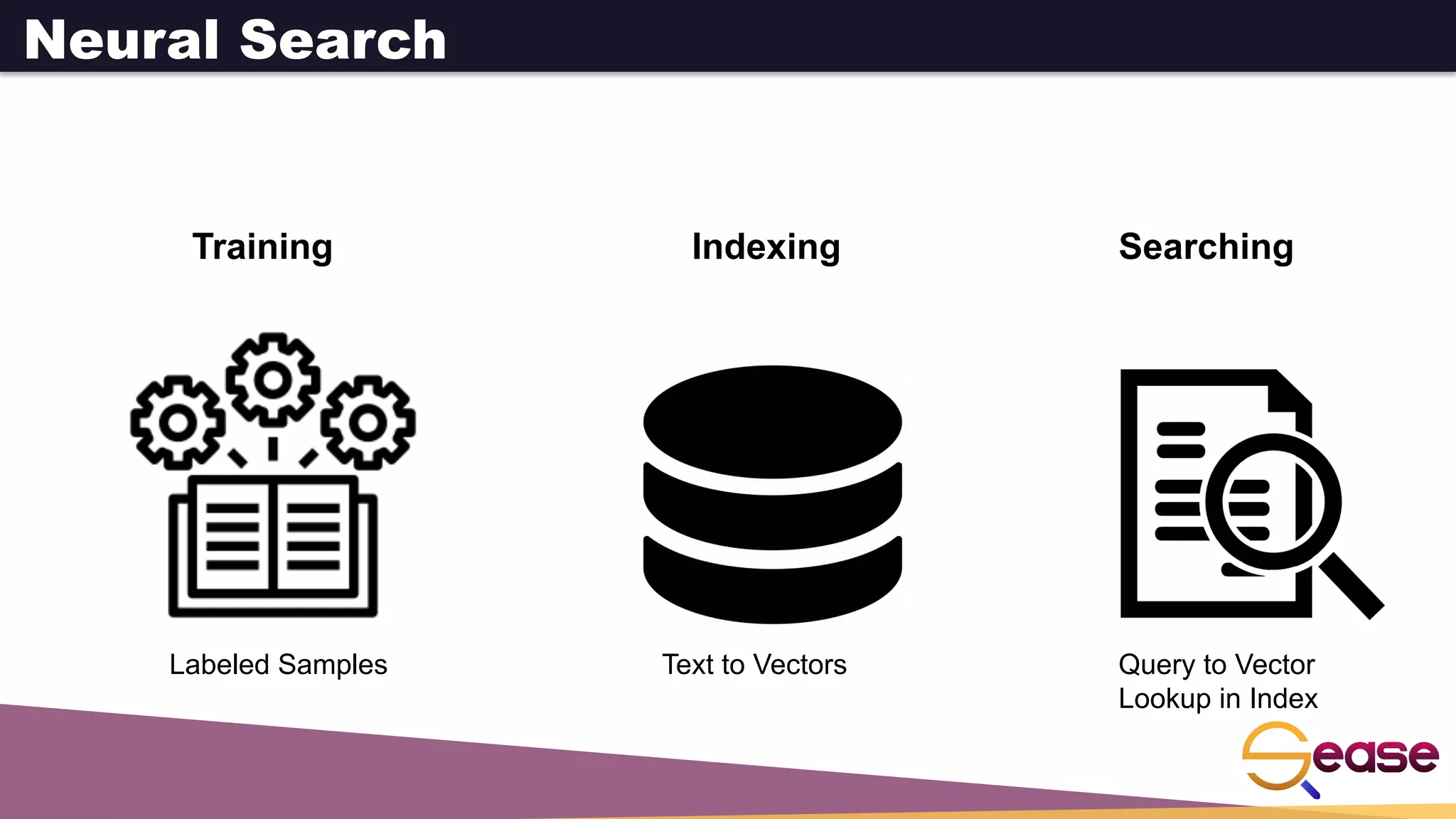
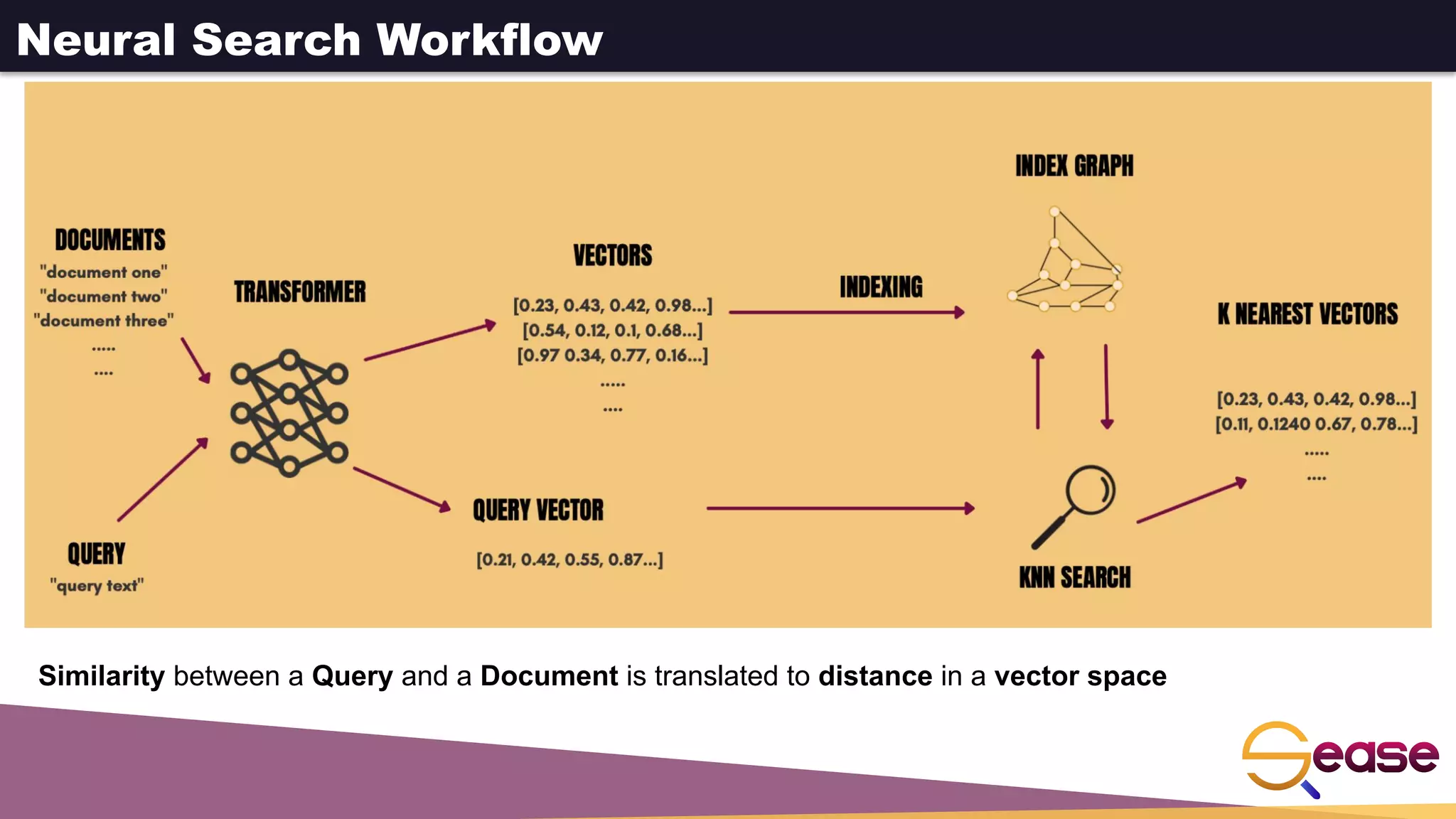
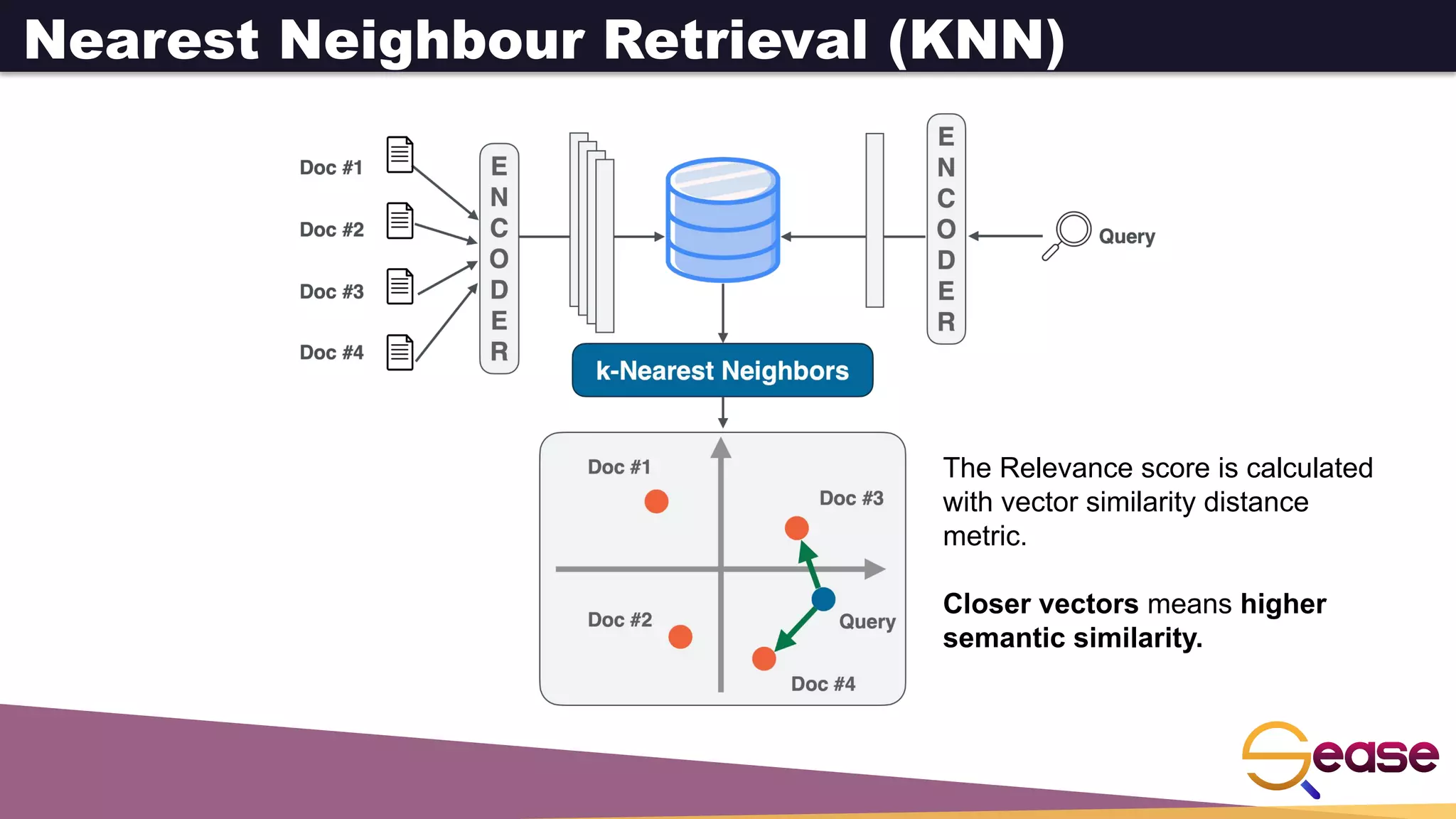
This document provides an overview of dense retrieval with Apache Solr neural search. It discusses semantic search problems that neural search aims to address through vector-based representations of queries and documents. It then describes Apache Solr's implementation of neural search using dense vector fields and HNSW graphs to perform k-nearest neighbor retrieval. Functions are shown for indexing and searching vector data. The document also discusses using vector queries for filtering, re-ranking, and hybrid searches combining dense and sparse criteria.























































































