Download to read offline






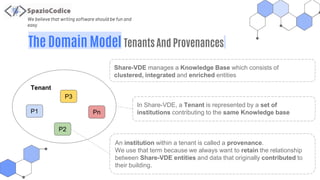
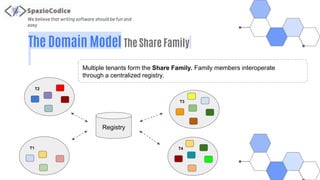
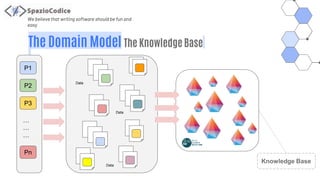
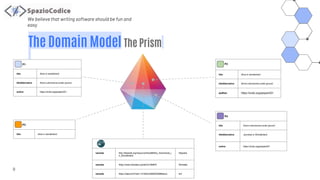

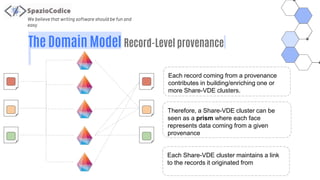
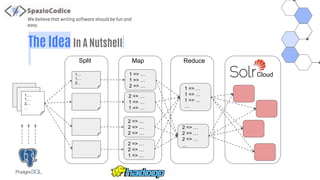









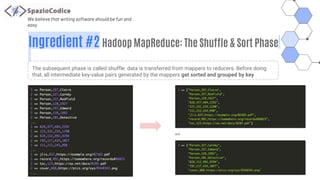
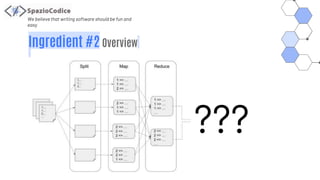








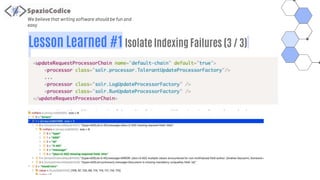







The document discusses the Share-VDE project, focusing on creating a fun and easy software development environment. It outlines the project's domain model, data organization, and processing methodologies using technologies like PostgreSQL, Hadoop MapReduce, and Apache Solr. Key insights and lessons learned from implementation challenges highlight the importance of data management, system architecture, and indexing tactics for large-scale projects.



































































