Download as PDF, PPTX








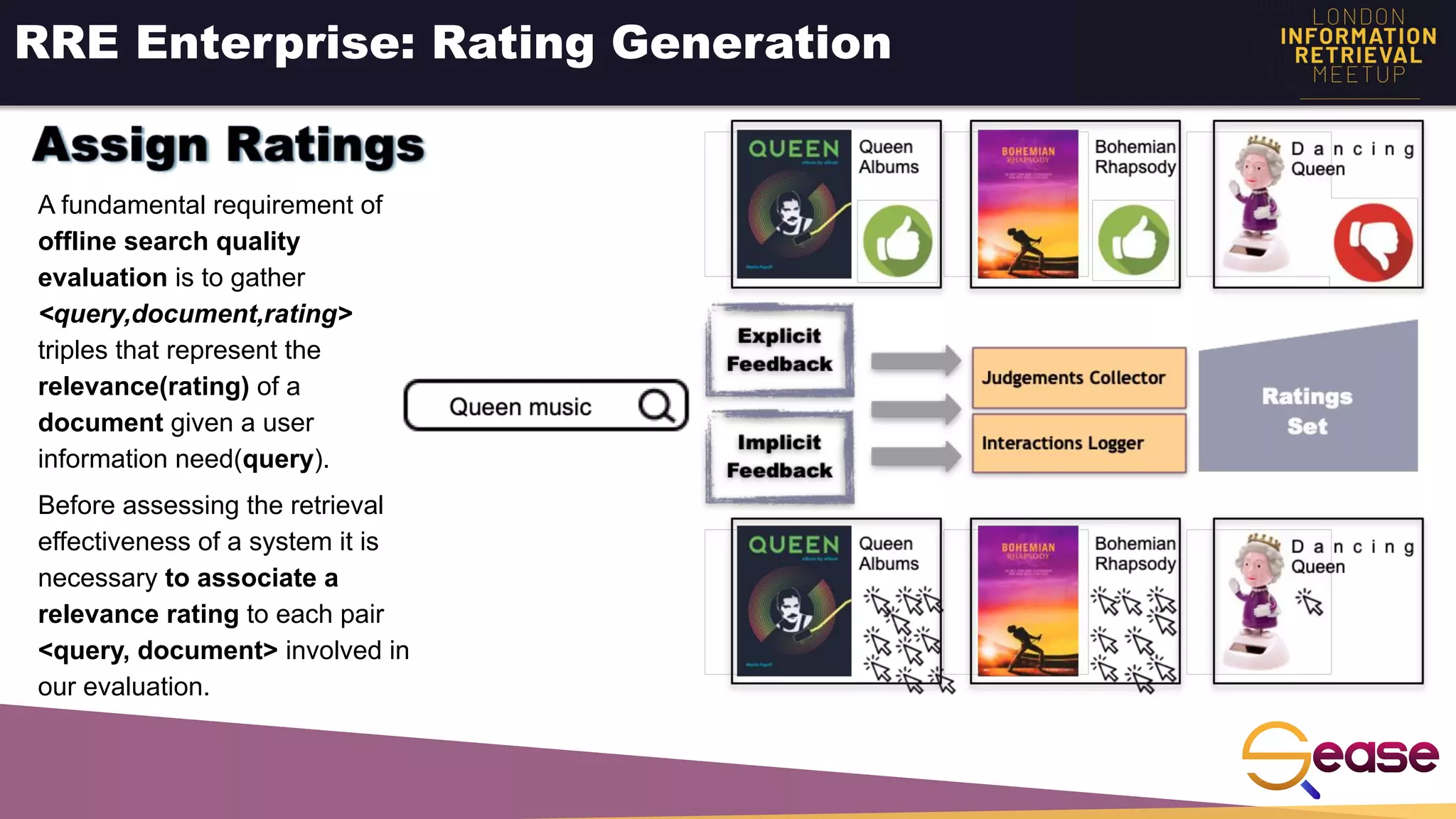
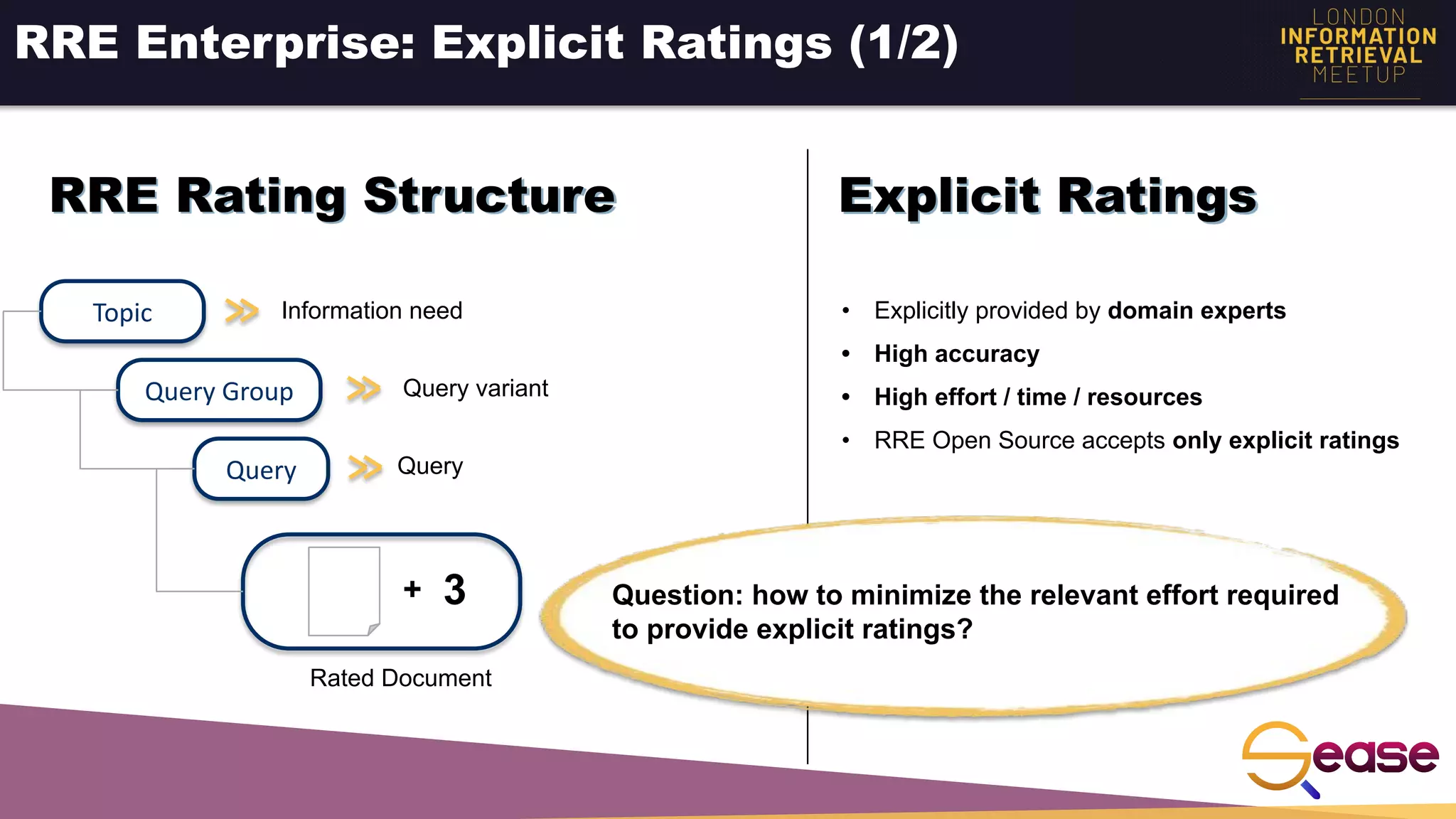





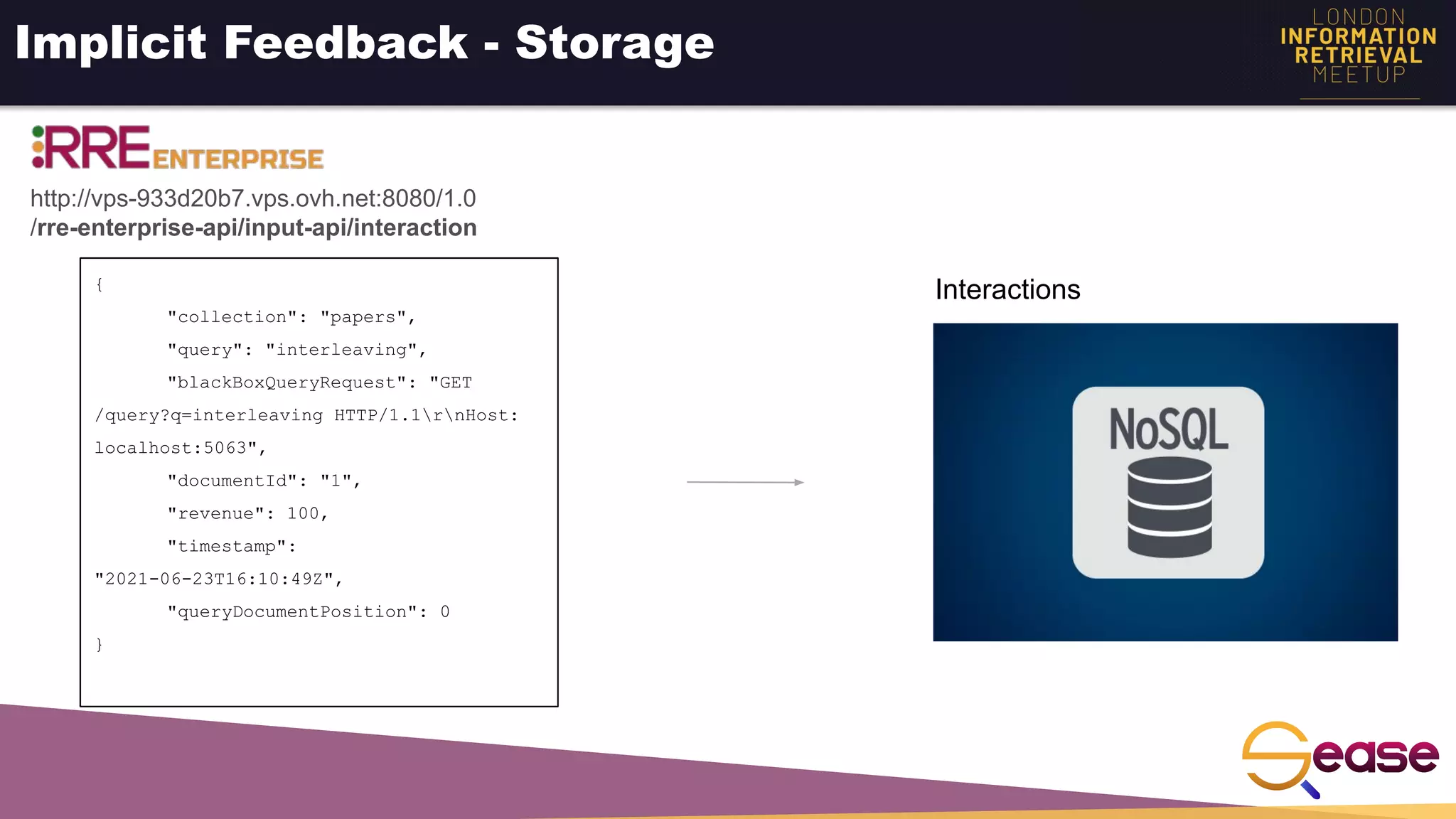

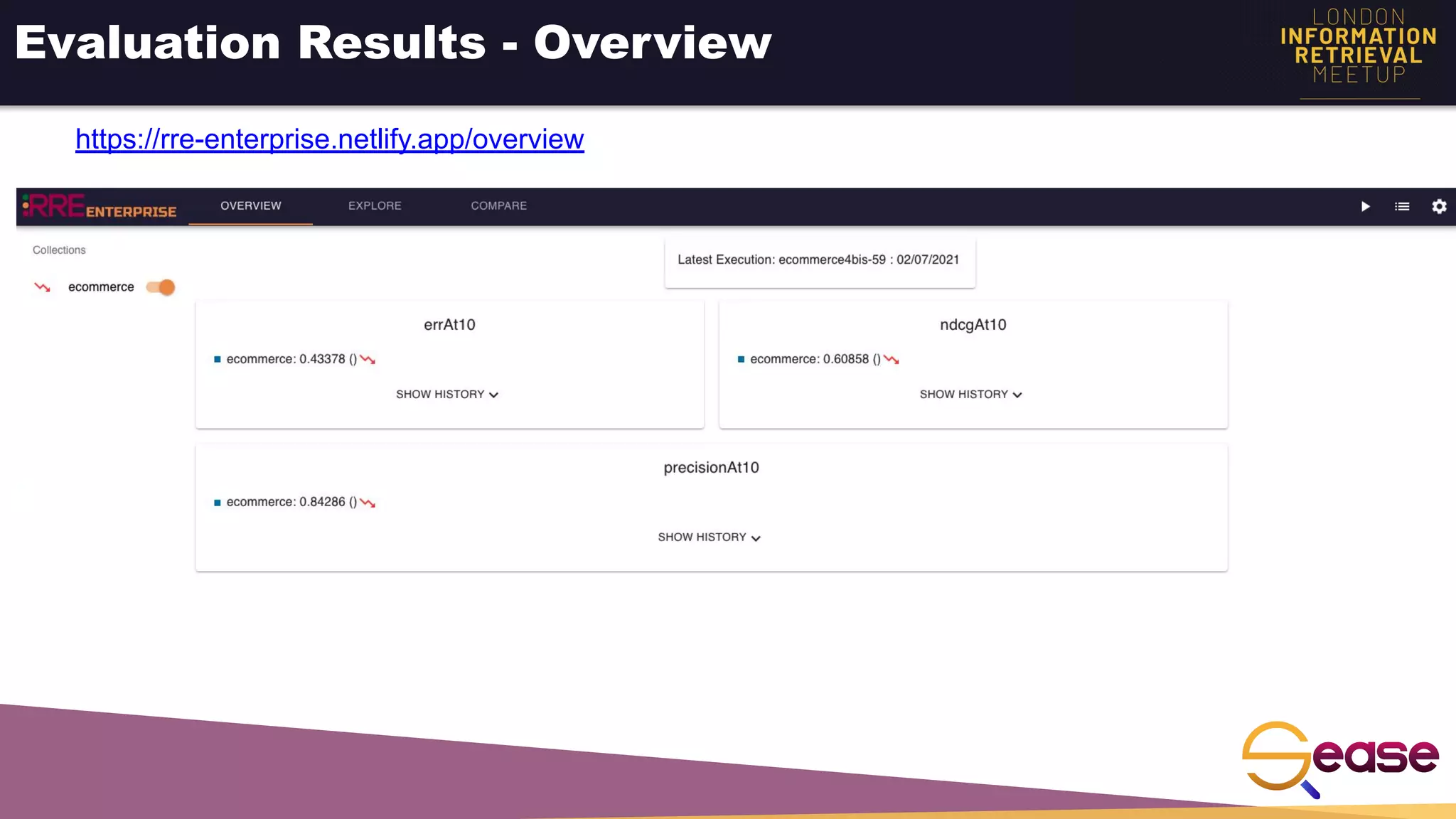
![Implicit Feedback - Estimate Relevance
Global Max: 1 Local Max: [0...1]
Global Min: 0 Local Min: [0...1]
Simple Click Model
0 1 2 3 4
Rating
Metric Score
0 1
0.5](https://image.slidesharecdn.com/rre-enterprise-meetup-2021-210916132025/75/Rated-Ranking-Evaluator-Enterprise-the-next-generation-of-free-Search-Quality-Evaluation-Tools-34-2048.jpg)


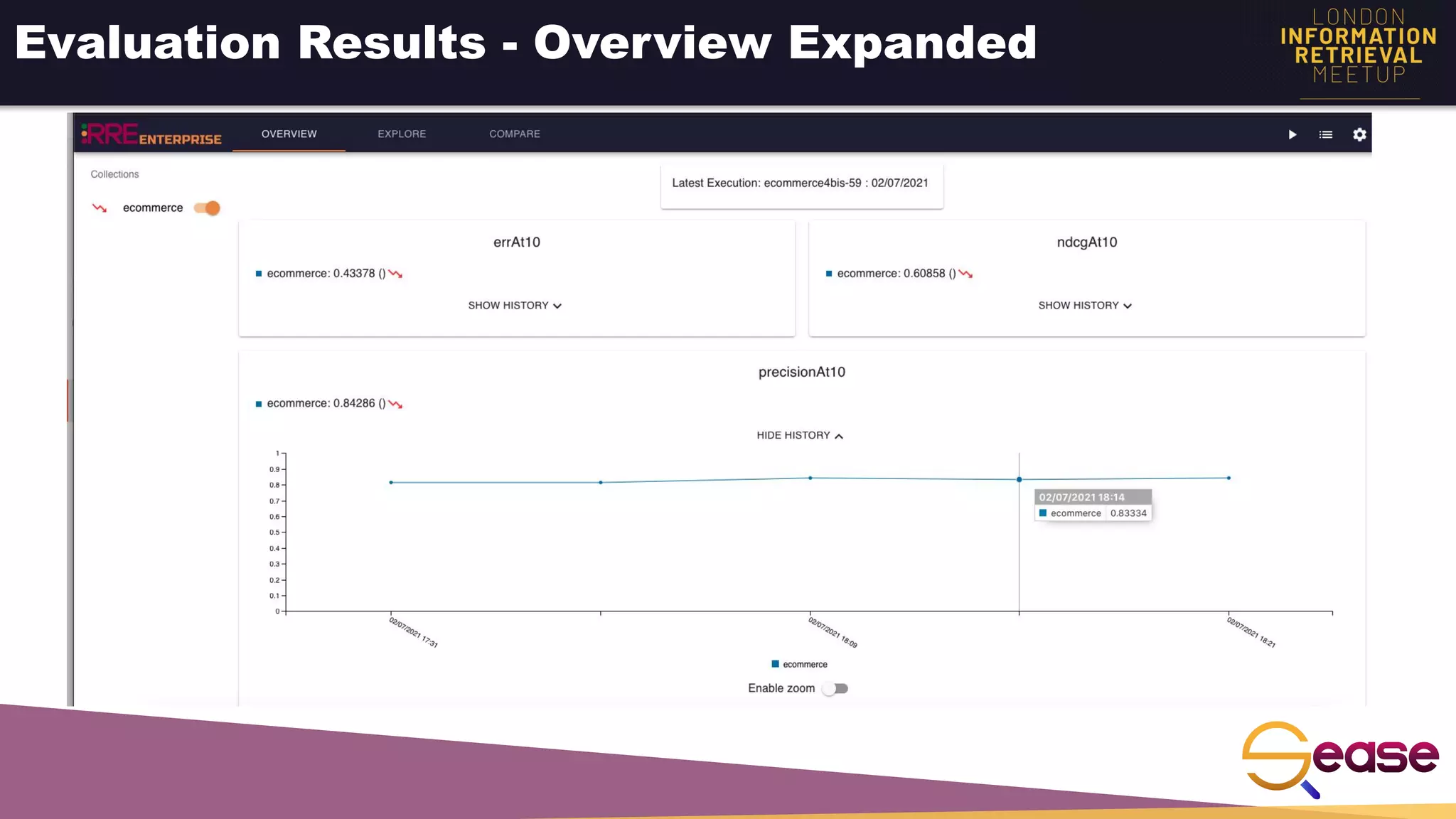
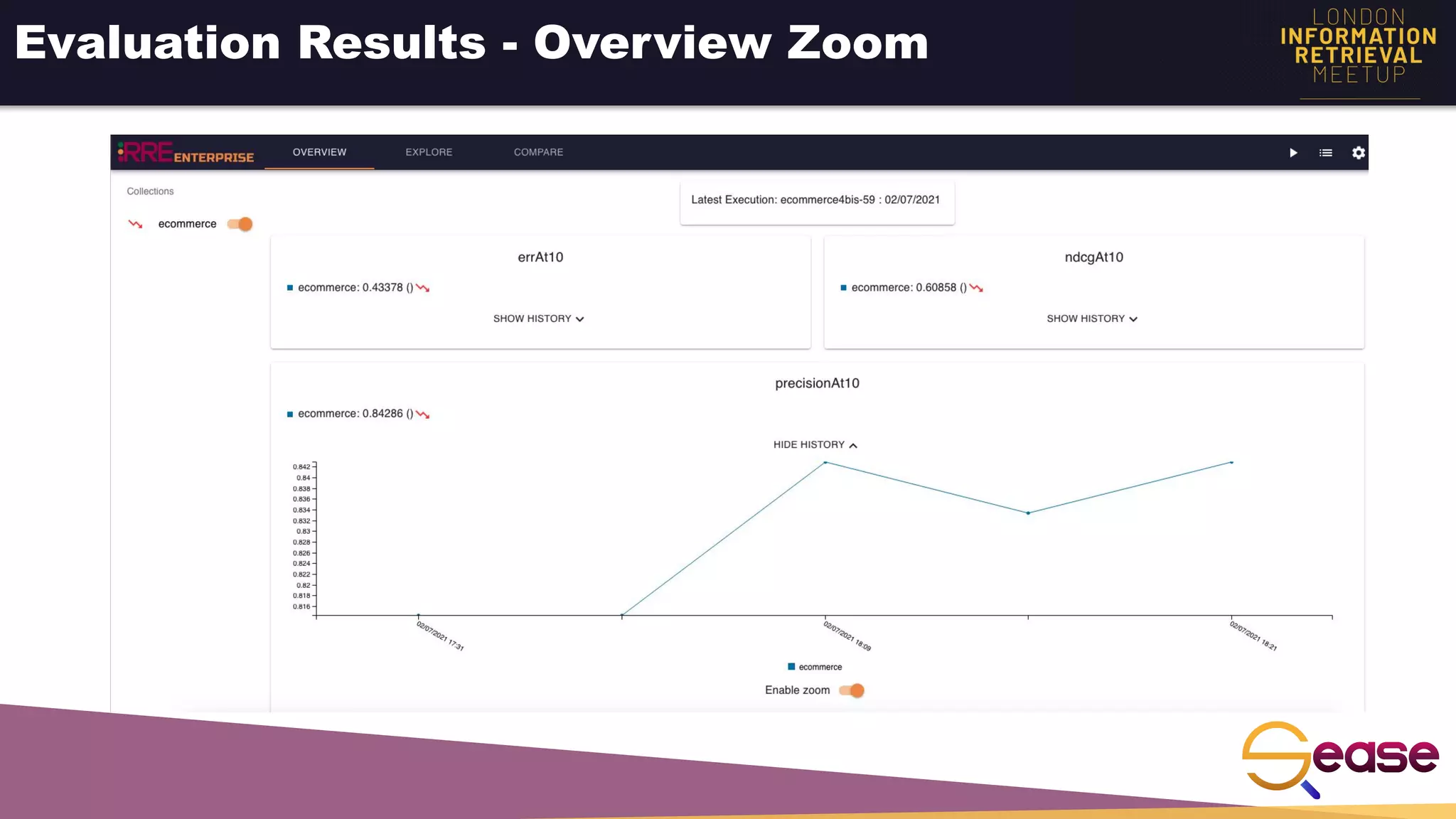
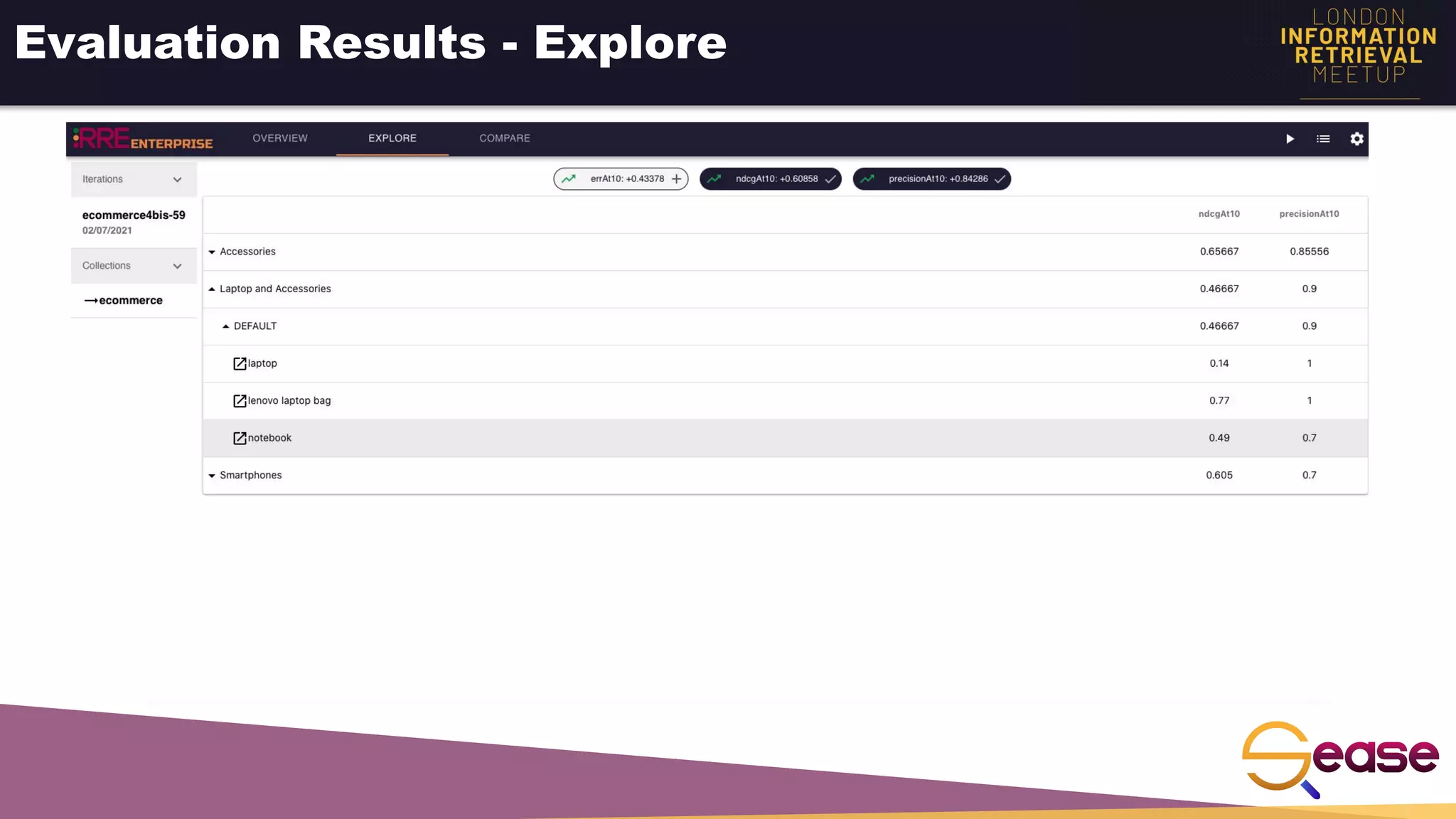
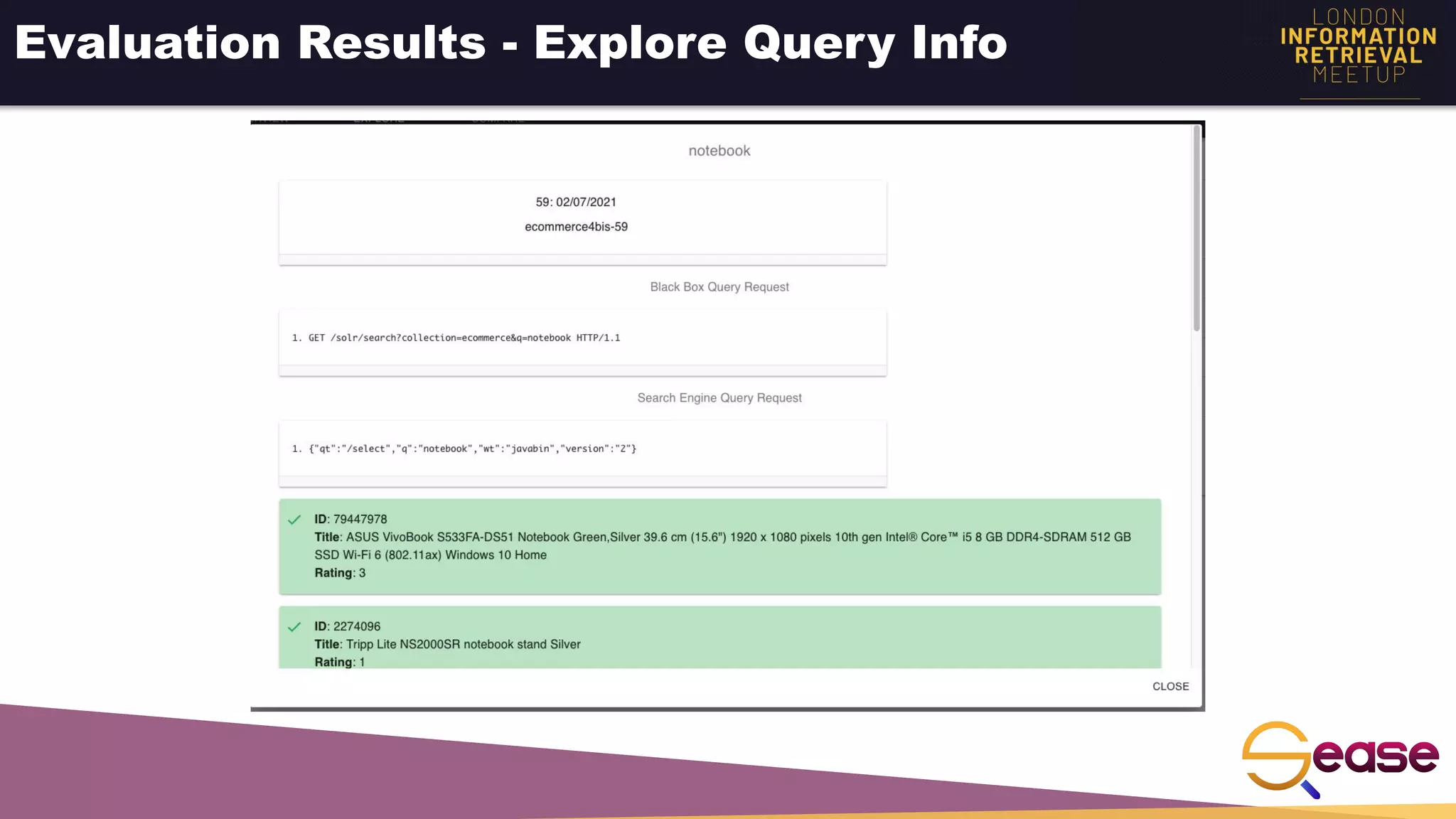

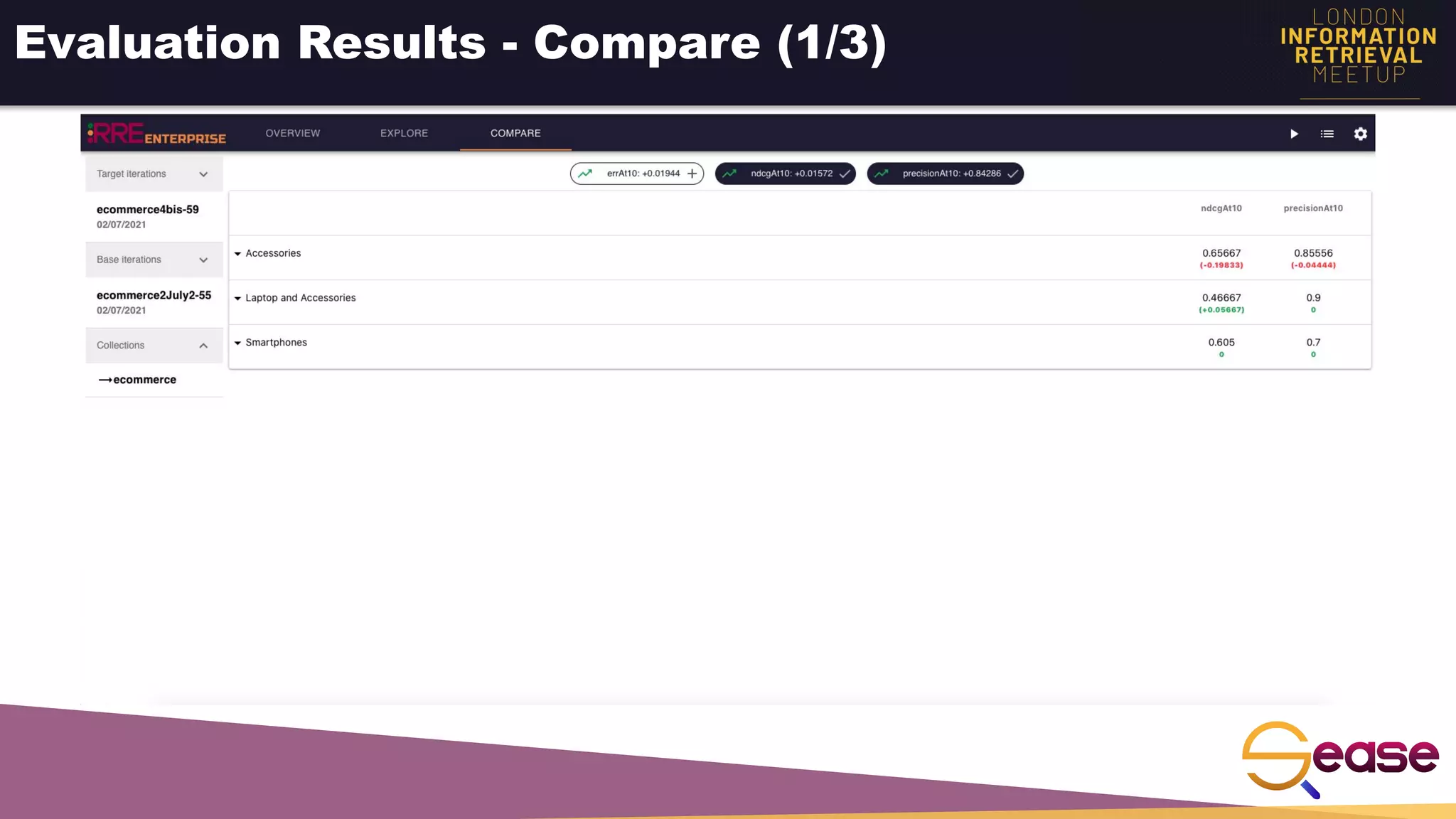
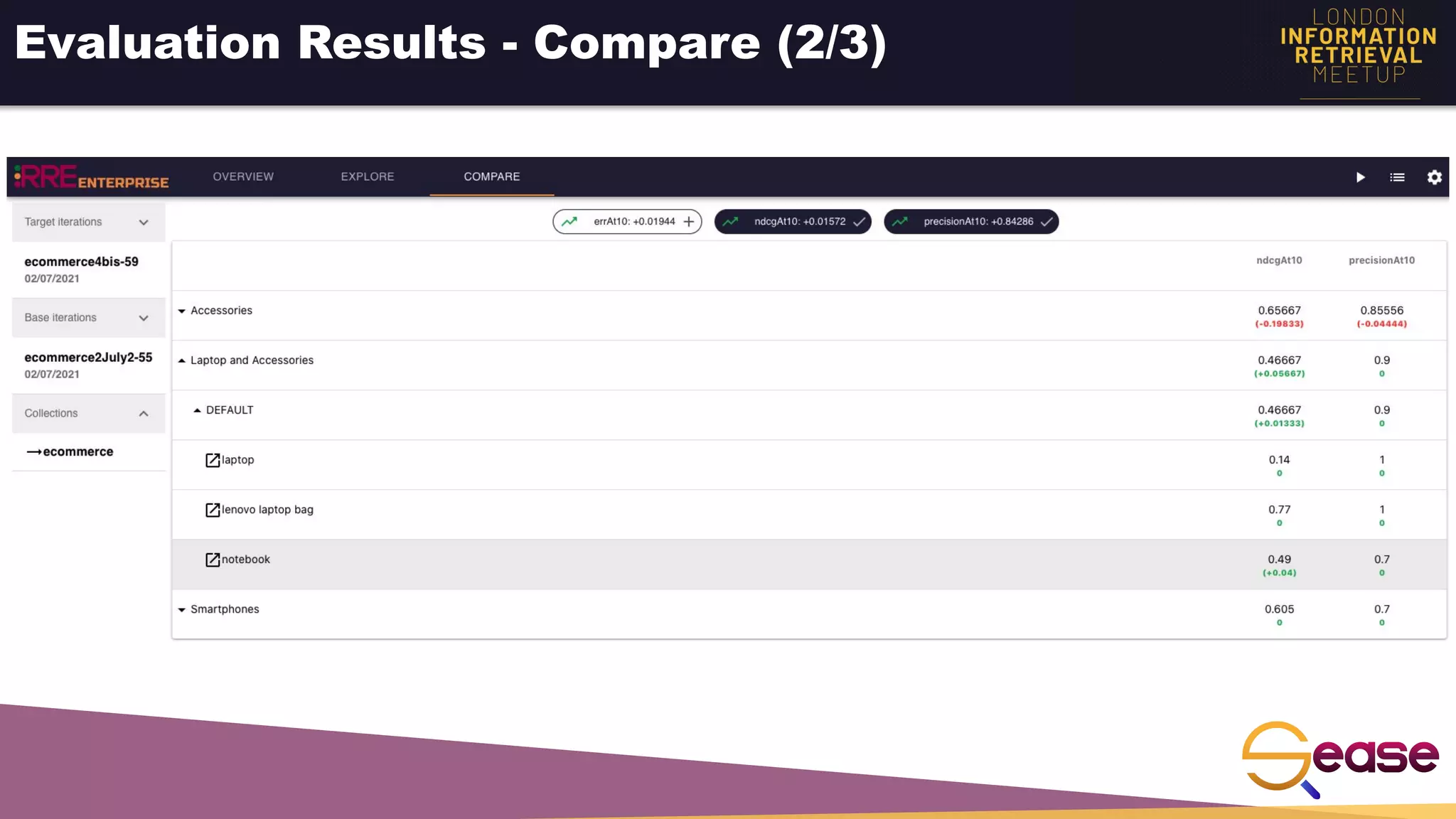
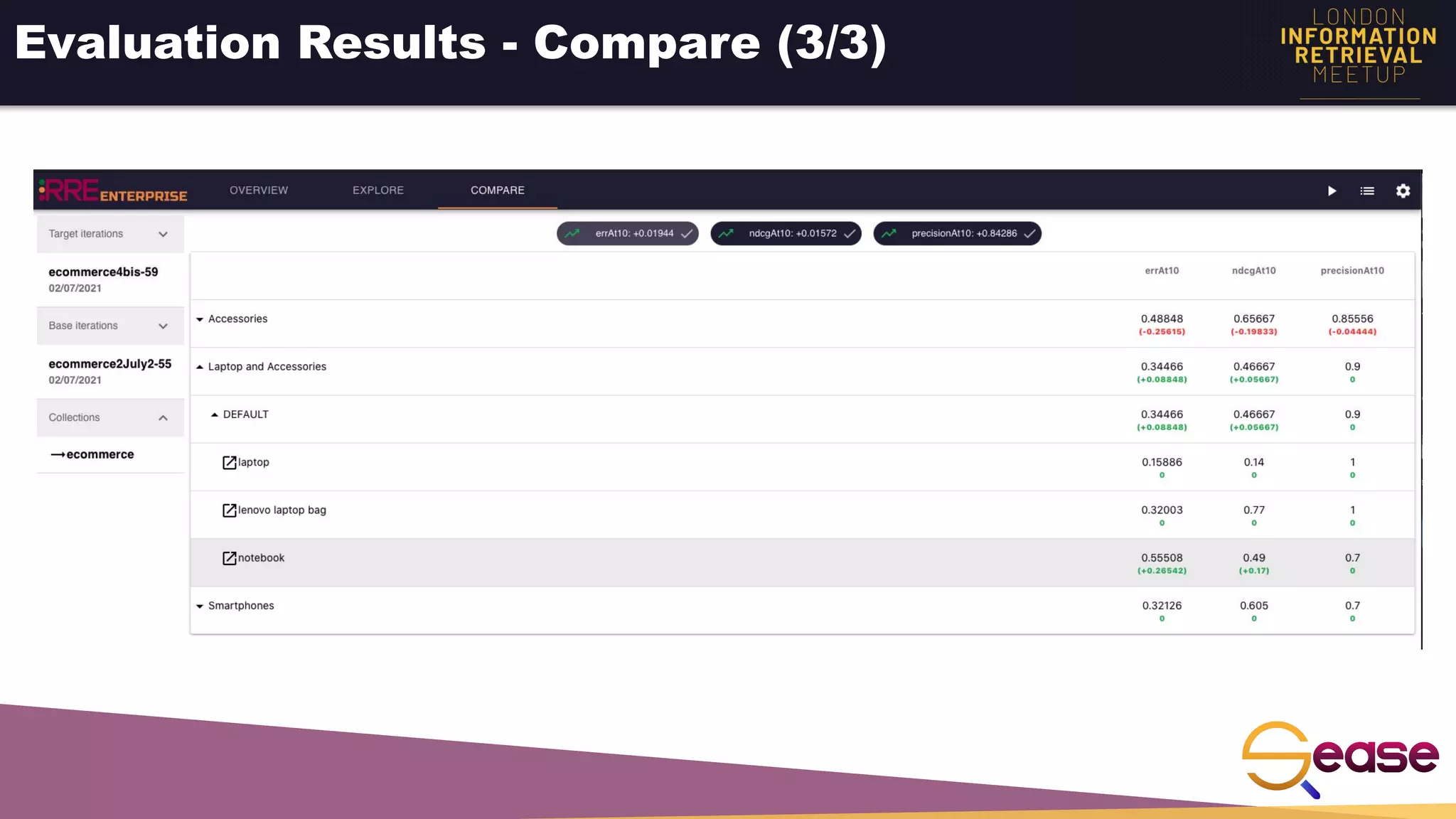




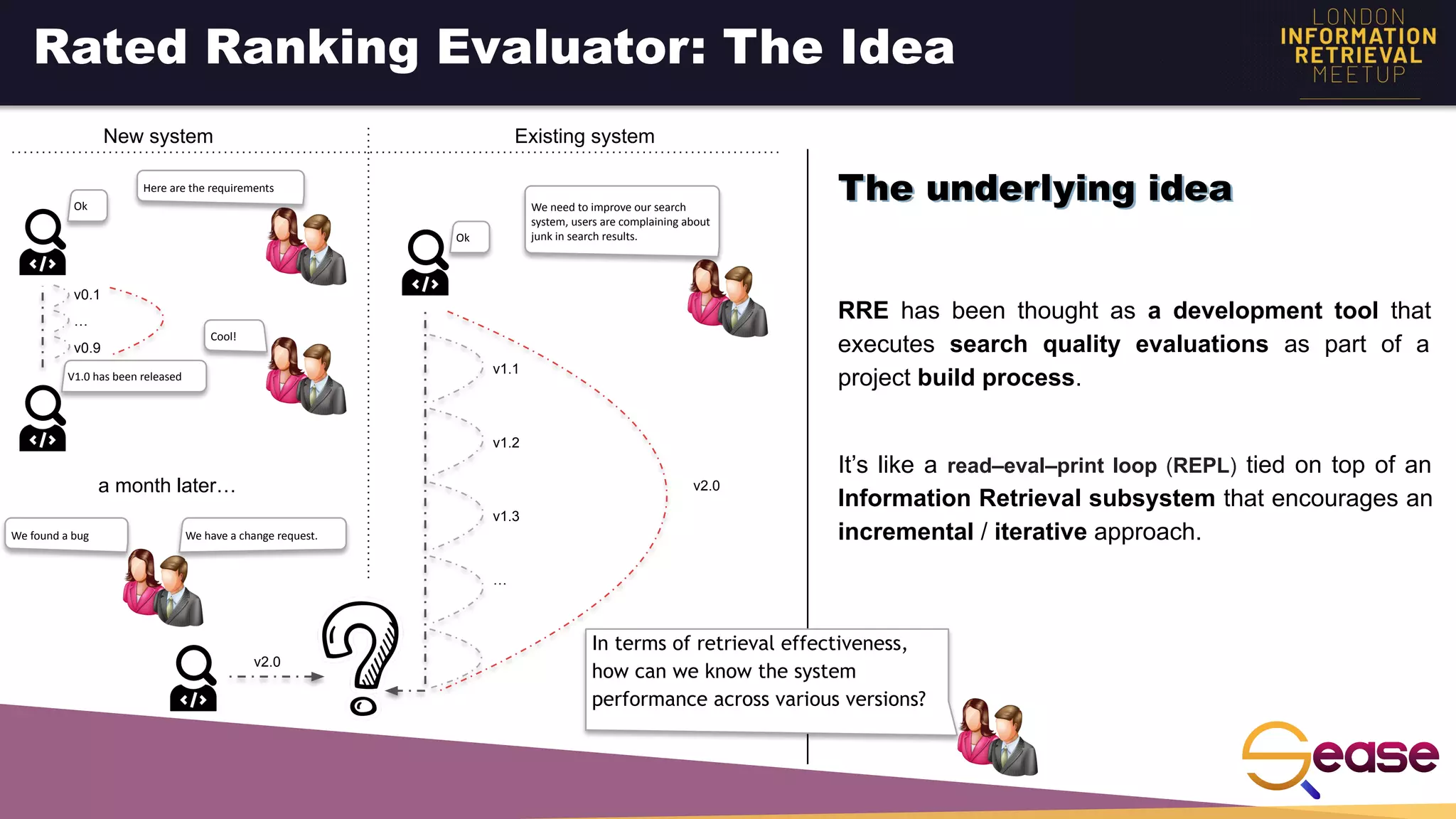
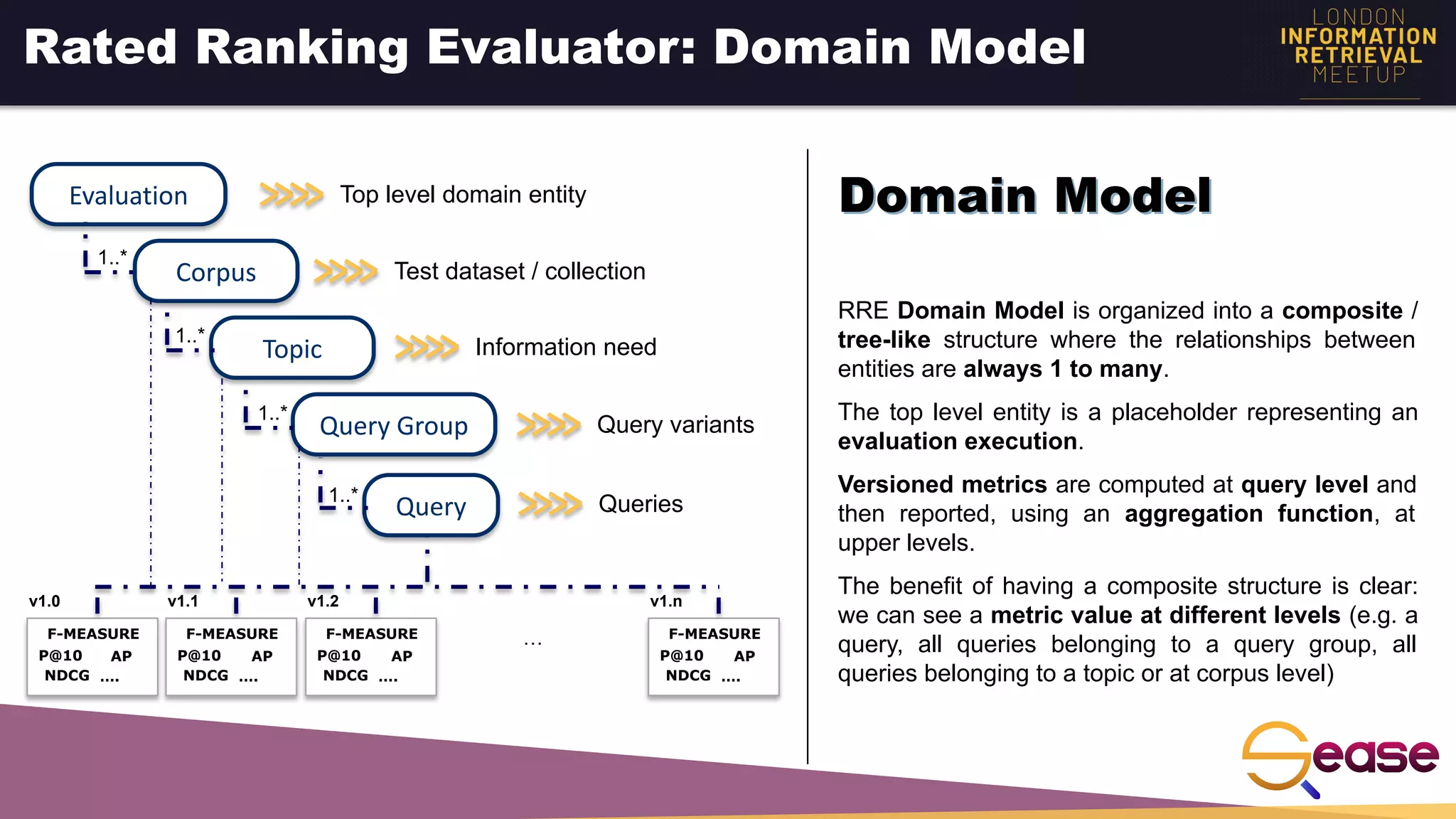
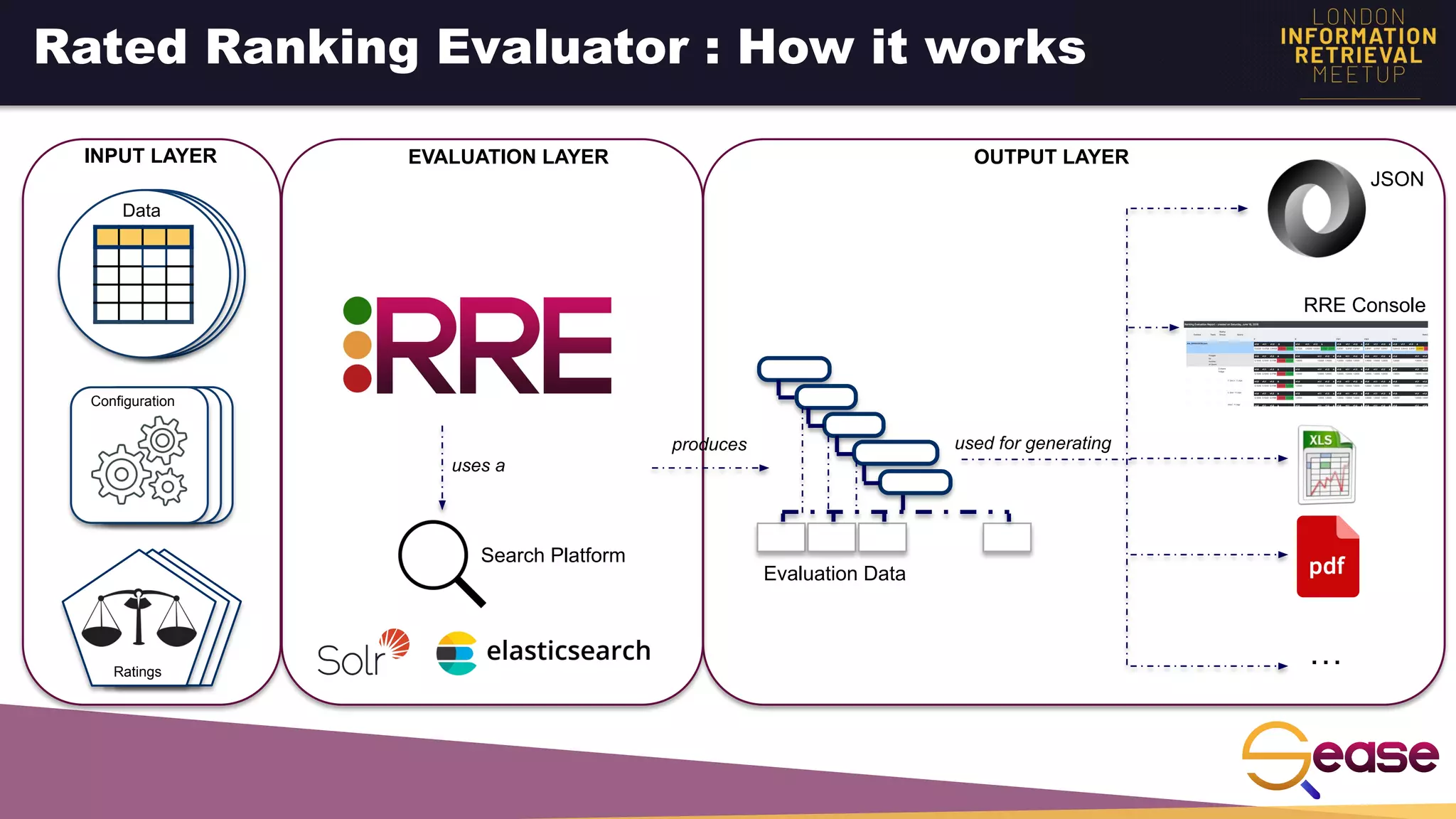
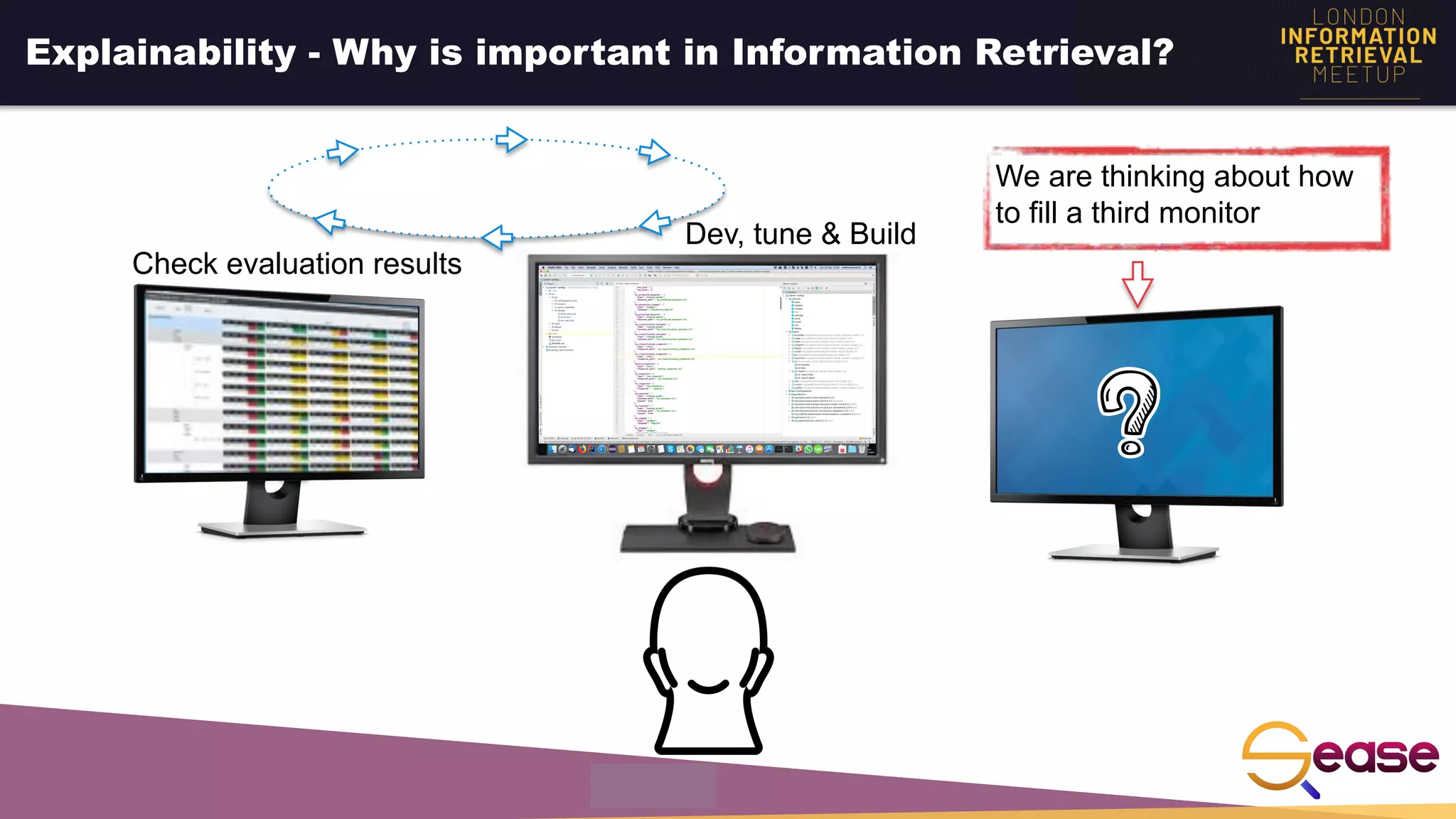
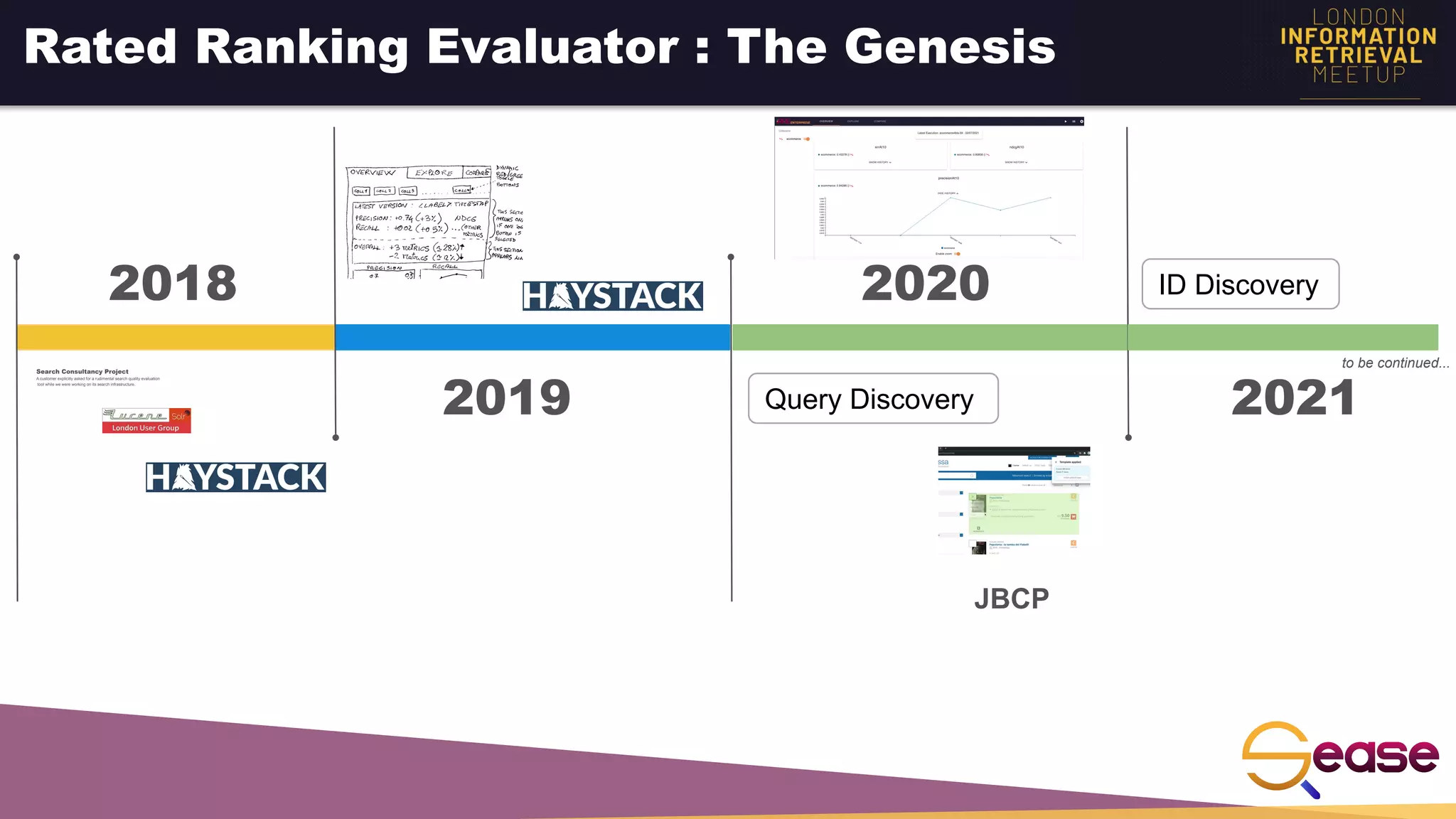
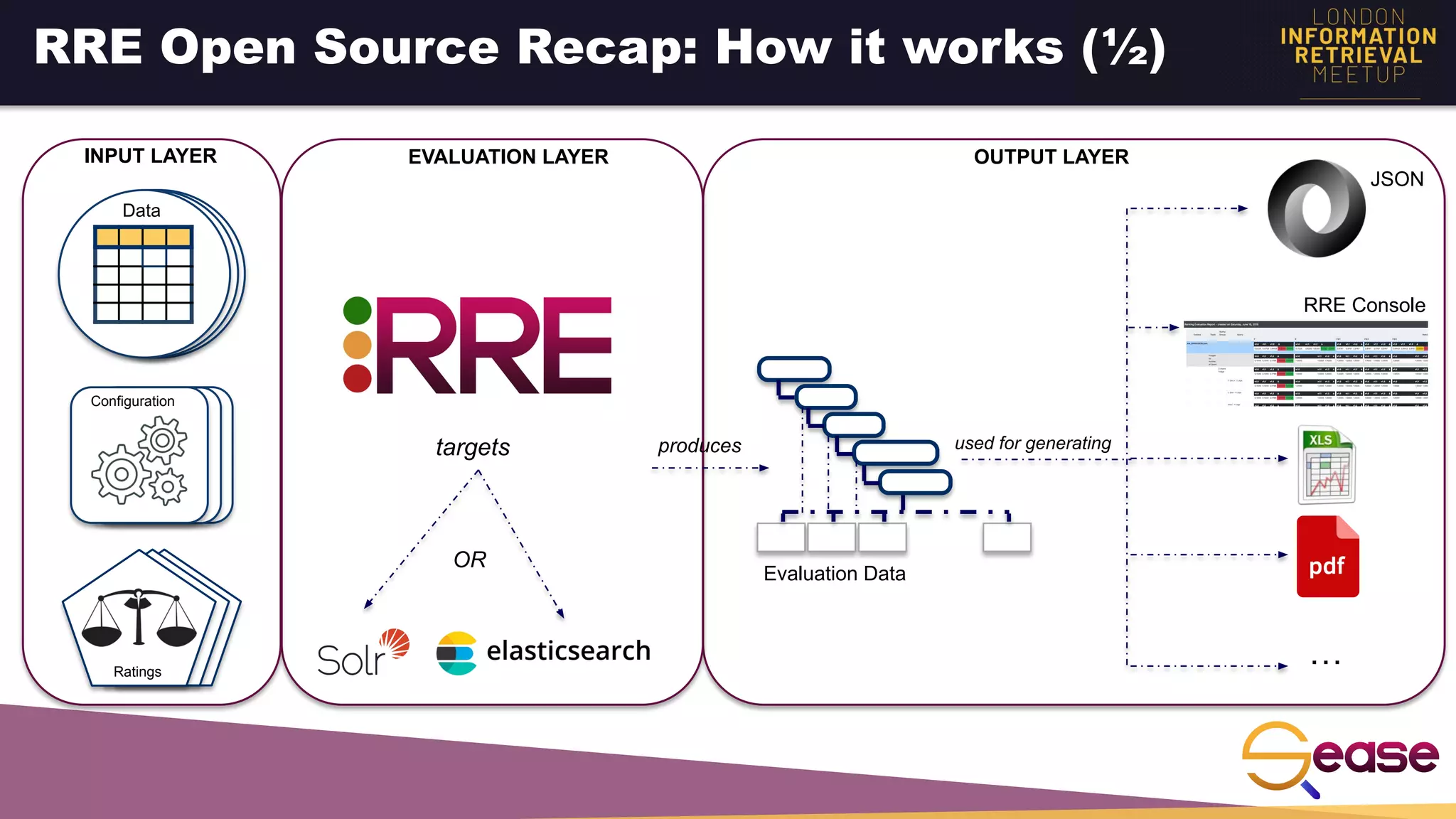
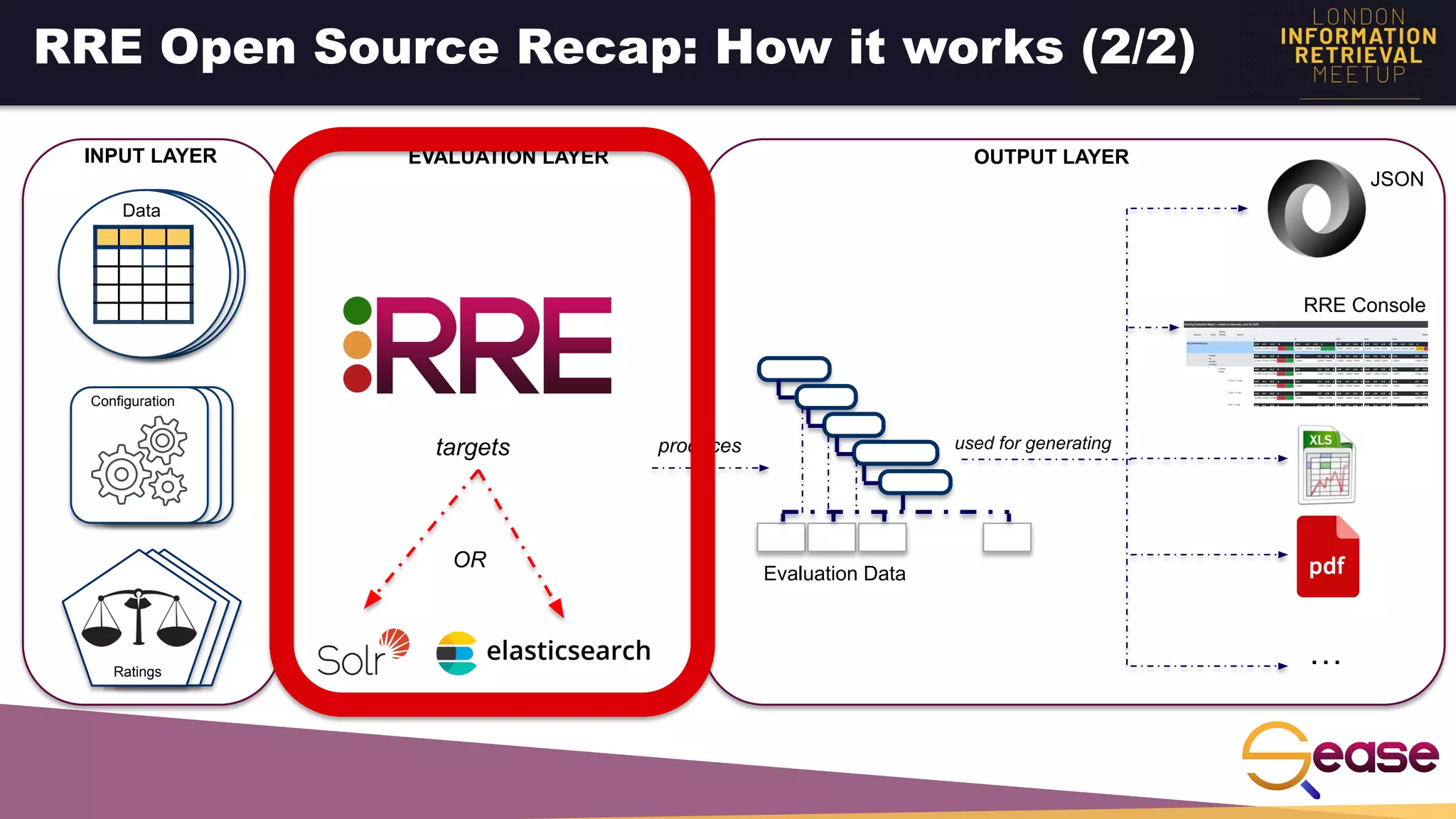
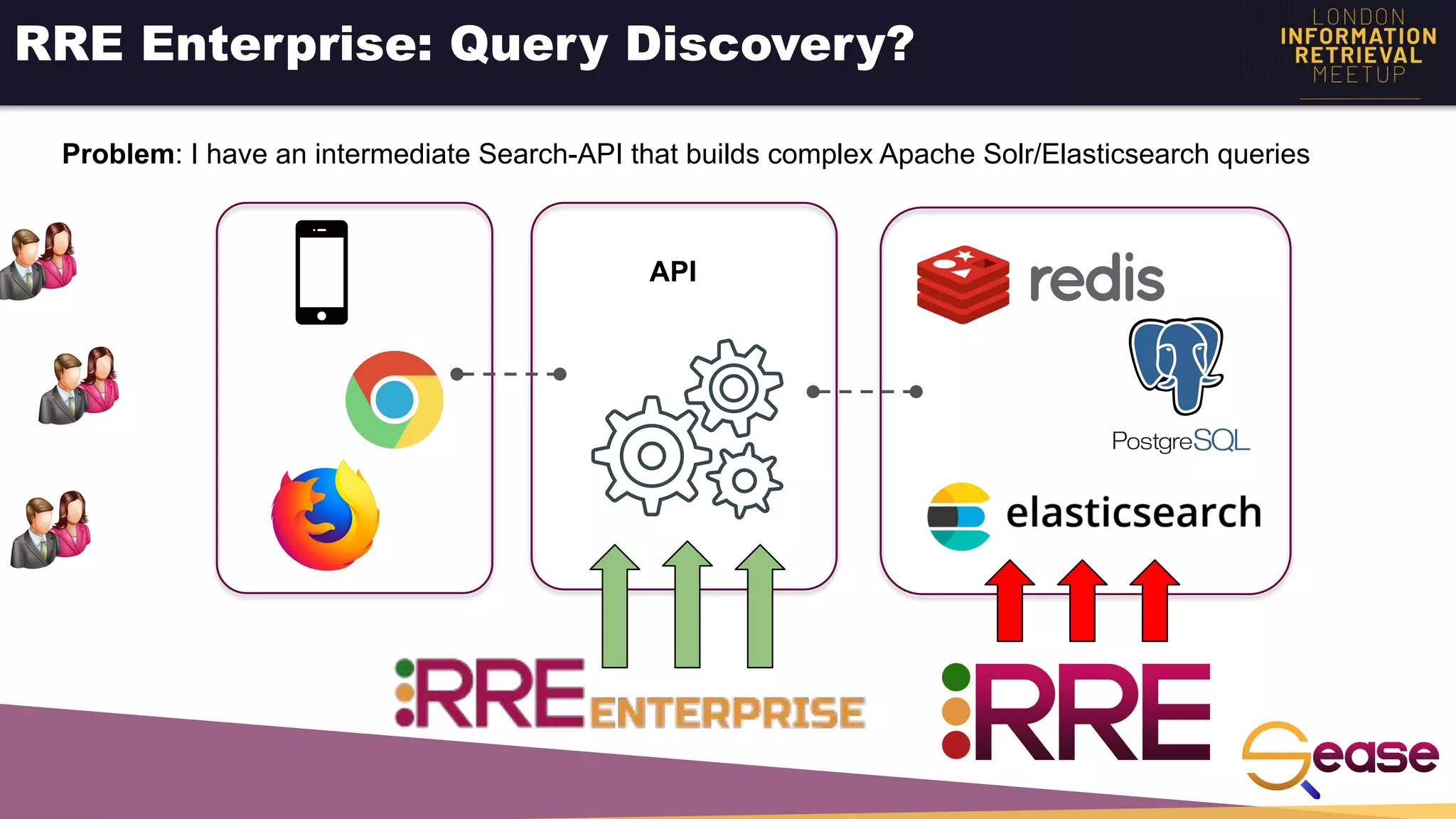
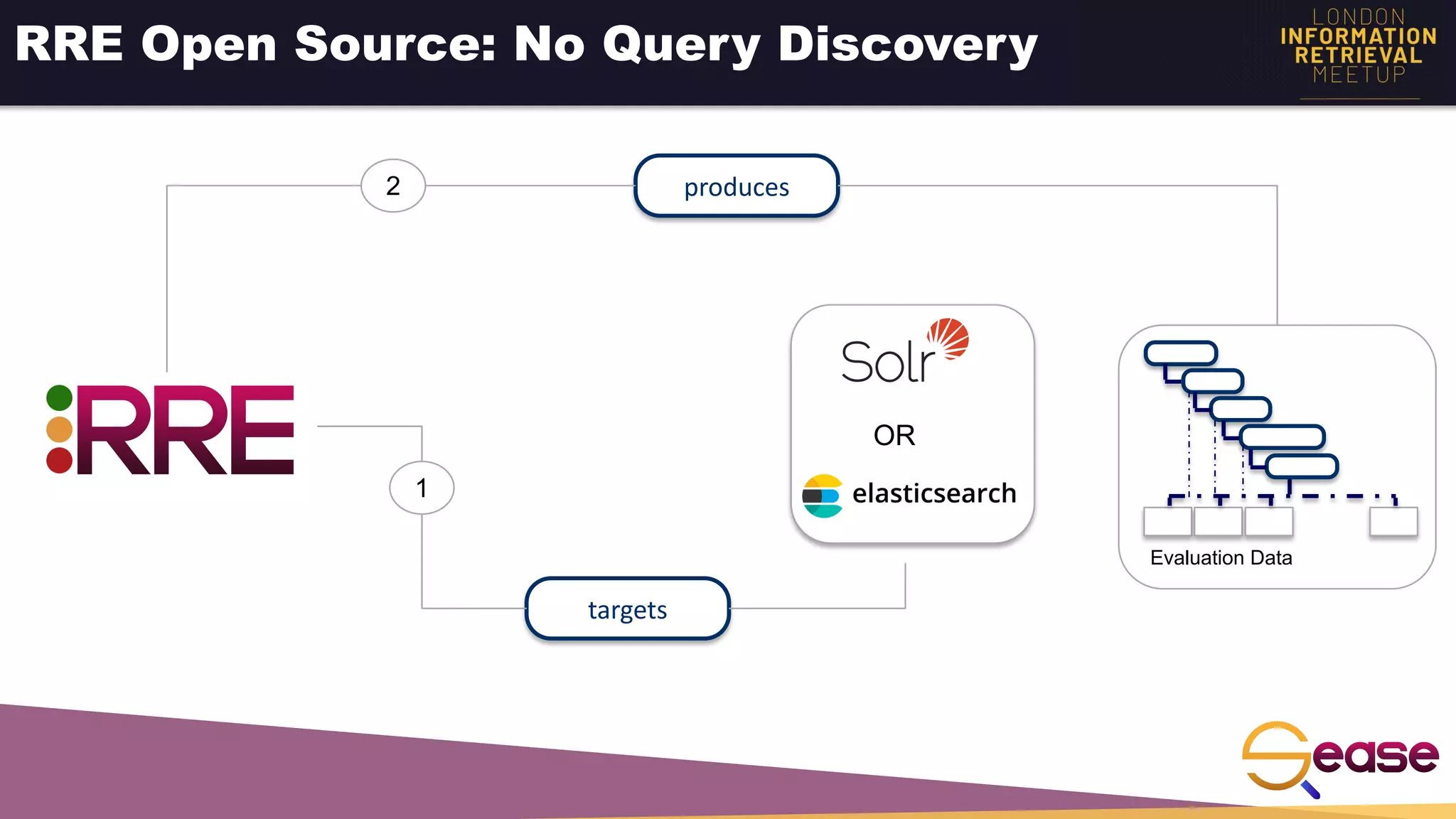
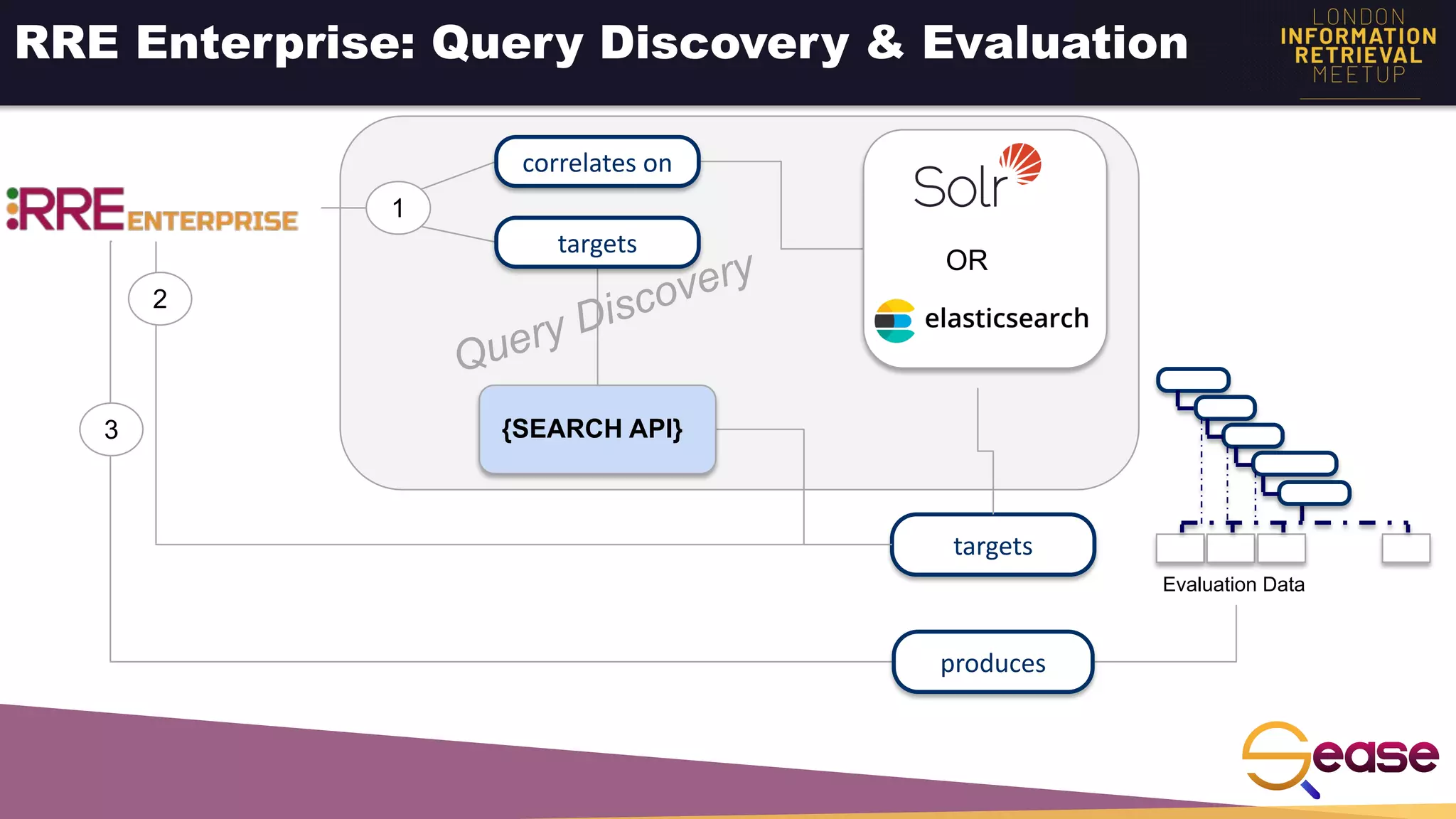
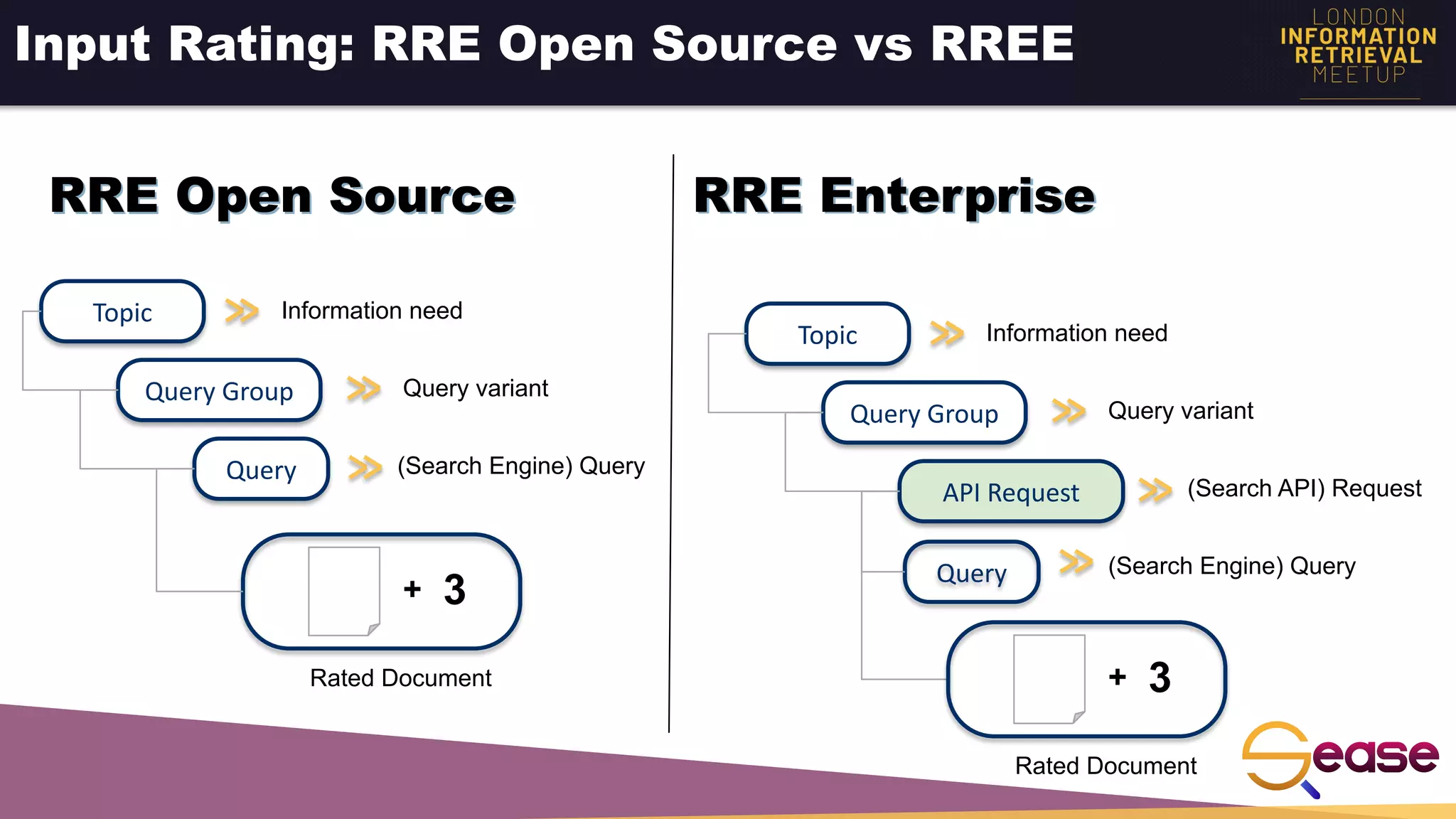
Rated Ranking Evaluator Enterprise is an enterprise version of the open source Rated Ranking Evaluator search quality evaluation tool. It features query discovery to automatically extract queries from a search API, rating generation using both explicit ratings and implicit feedback, and an interactive UI for exploring and comparing evaluation results. The UI provides overview, exploration, and comparison views of evaluation data to meet the needs of business stakeholders and software engineers. Future work aims to improve the tool's capabilities around configuration, multimedia support, insights generation, and click modeling.




































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















