


















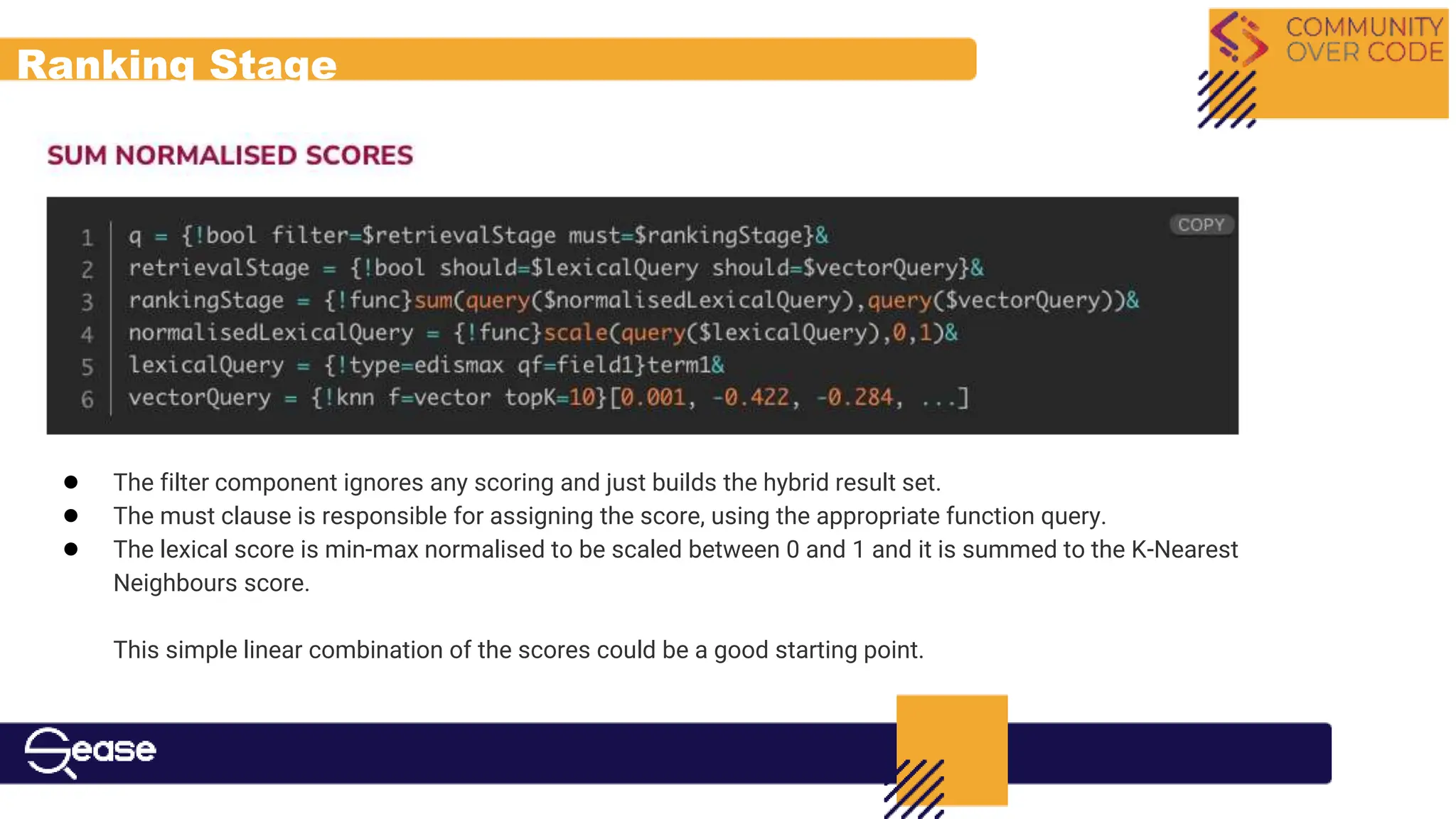
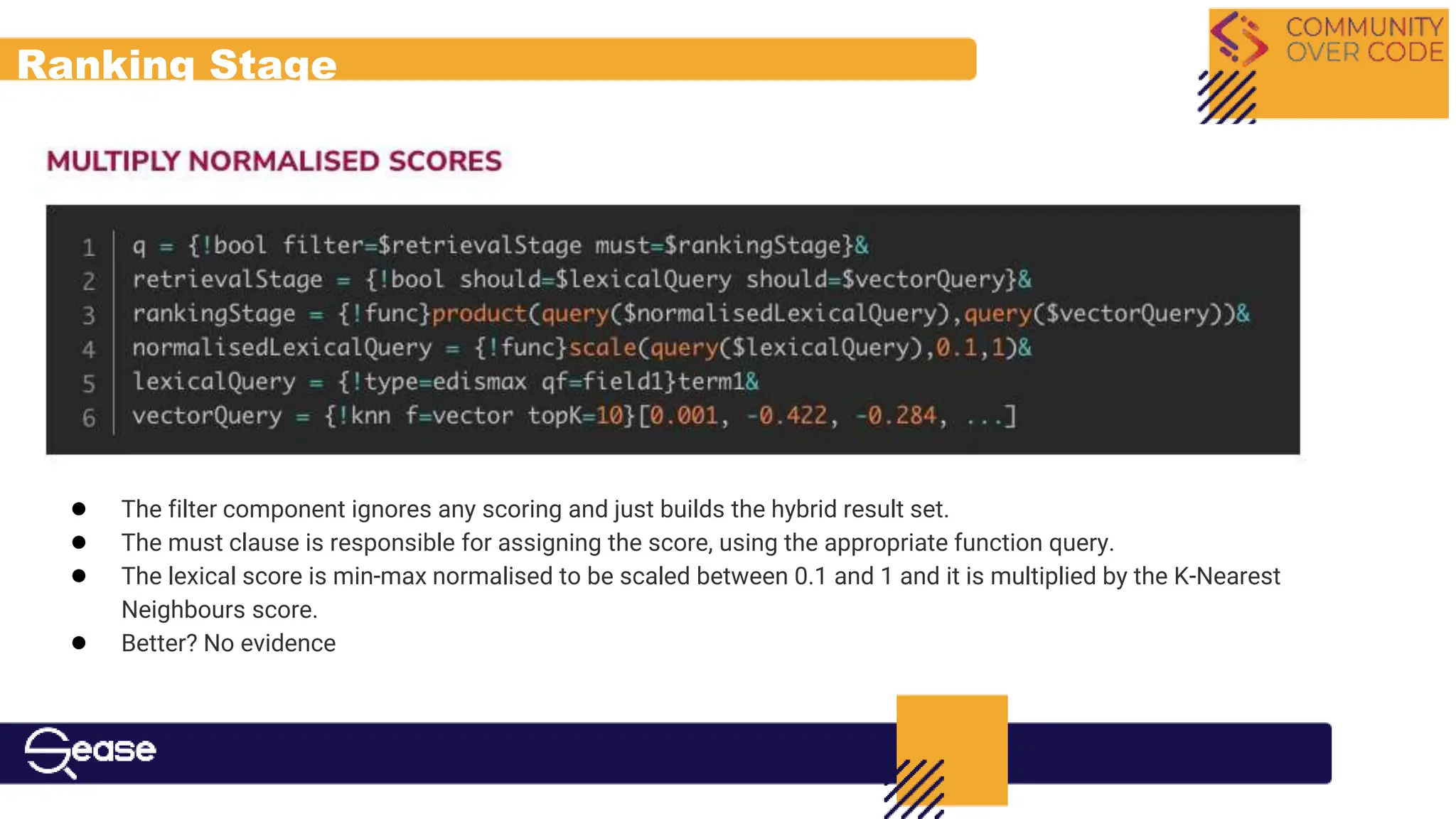
![The Ranking Problem
● We need a score that reflects the best relevance ordering
● KNN candidates present a score [-1 … 1]
● Lexical candidates present an unbounded score (potentially on a complete
different scale)
N.B. combining Lexical scores with vector-based similarity (and potentially other
features) is not a solved problem
What options do we have right now in Apache Solr?](https://image.slidesharecdn.com/communityovercode24hybridsearchwithapachesolr-240619165539-62c3866f/75/Hybrid-Search-With-Apache-Solr-22-2048.jpg)









The document discusses hybrid search techniques using Apache Solr, focusing on integrating traditional keyword-based and vector-based search methods to improve result relevance and diversity. It highlights the limitations of vector-based search, including issues with explainability and relevance scoring, and explains how hybrid ranking can mitigate these problems. Future developments and support for features like learning to rank and reciprocal rank fusion are also mentioned.
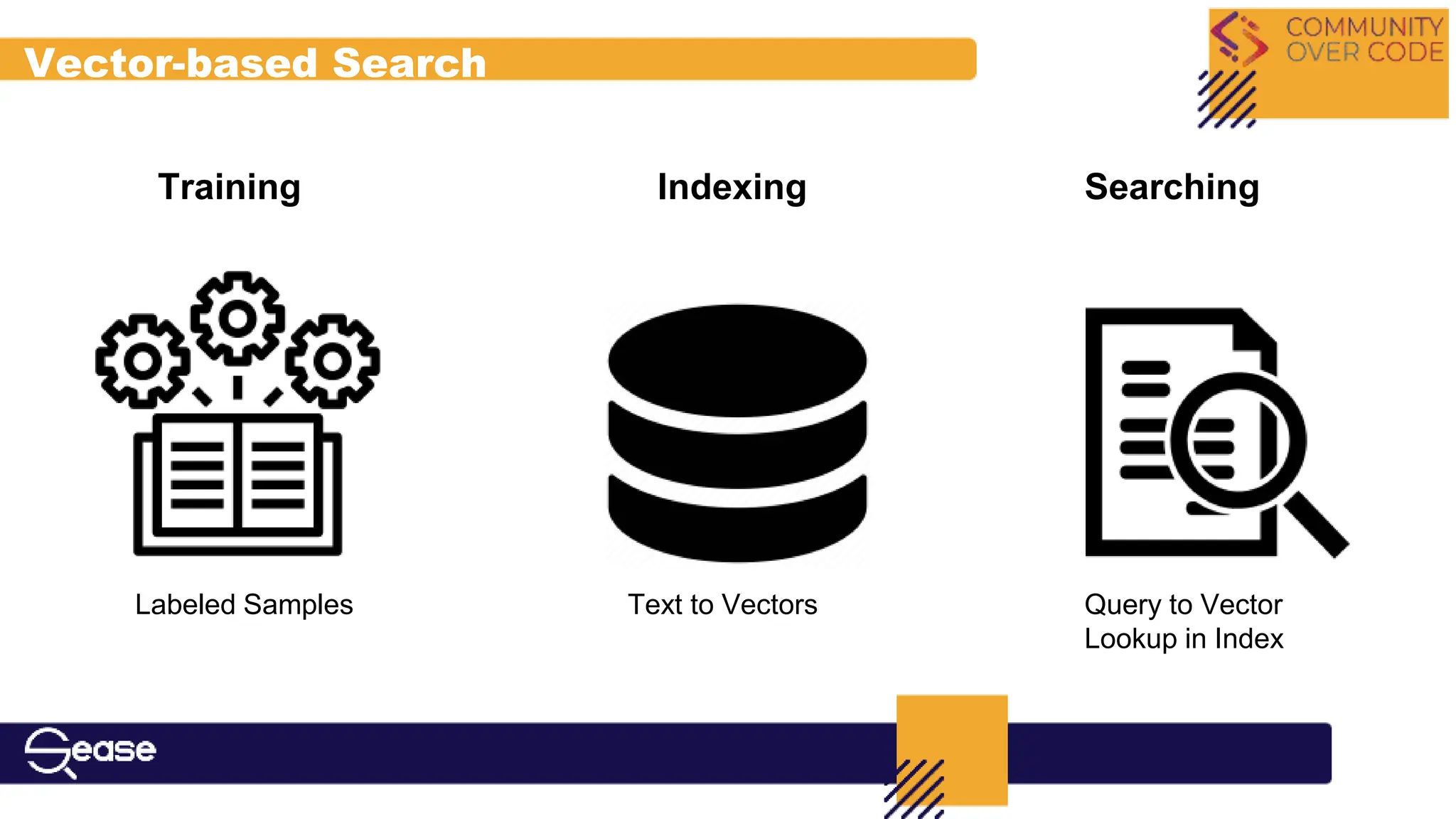
Introduction to hybrid search and speaker background, including expertise in Solr and NLP.
Details about SEArch Services, highlighting expertise in search technologies, trends such as Large Language Models and Vector-based Search.
Discusses limitations like explainability, low diversity, and issues in ranking and retrieval.
Discusses limitations like explainability, low diversity, and issues in ranking and retrieval.
Discusses limitations like explainability, low diversity, and issues in ranking and retrieval.
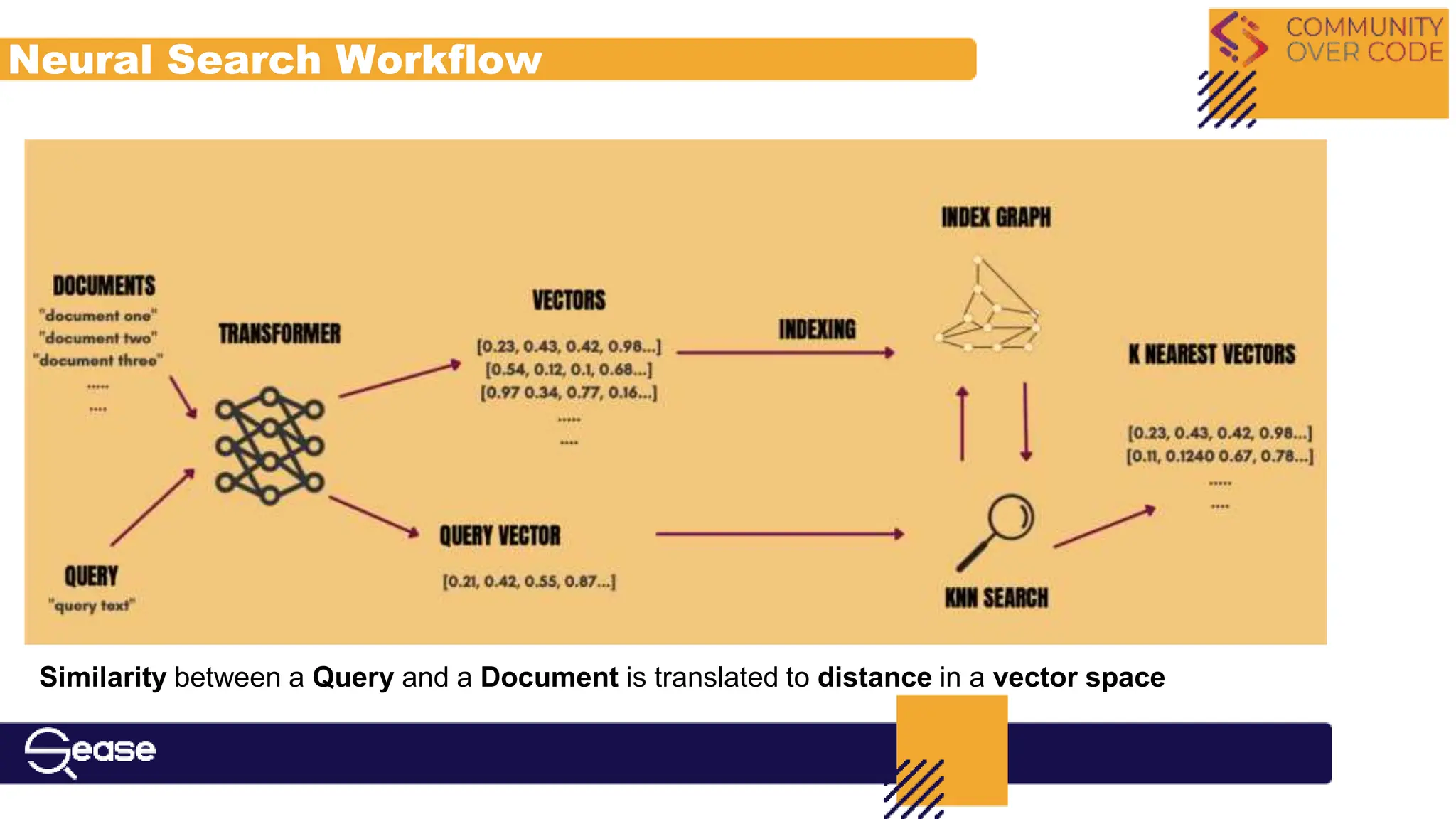
Explains hybrid search combining lexical and vector-based approaches, including retrieval and ranking processes.
Explains hybrid search combining lexical and vector-based approaches, including retrieval and ranking processes.
Discusses limitations like explainability, low diversity, and issues in ranking and retrieval.
Explains hybrid search combining lexical and vector-based approaches, including retrieval and ranking processes.
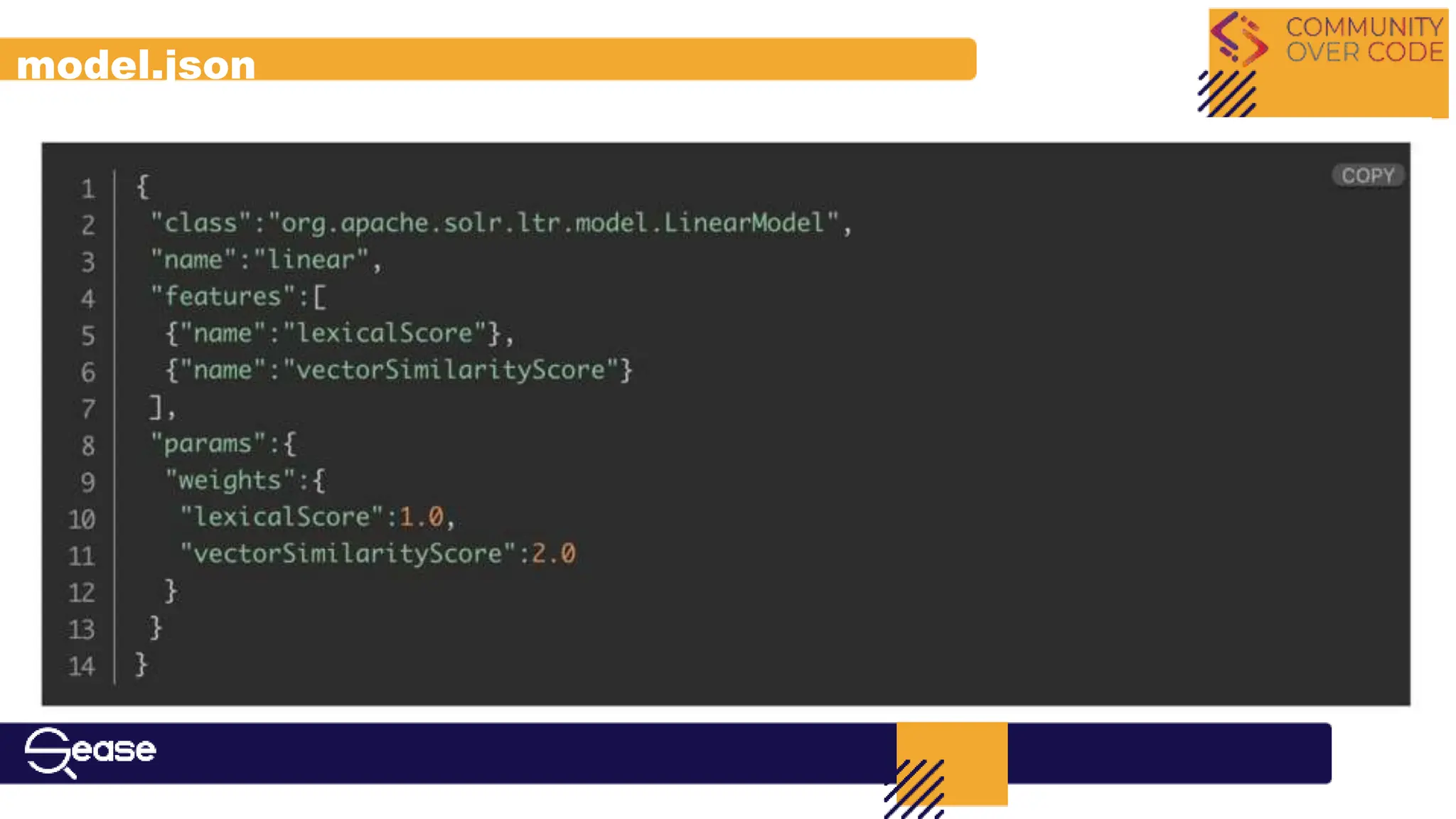
Outlines the use of machine learning for ranking documents effectively in hybrid search.
Discusses limitations like explainability, low diversity, and issues in ranking and retrieval.
Upcoming works on better scaling and methods in hybrid search, including reciprocal rank fusion.
Concludes with additional resources and thanks the audience.



































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














