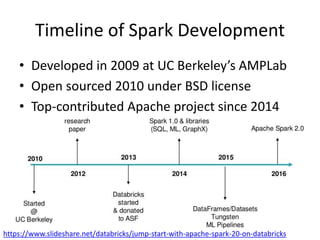
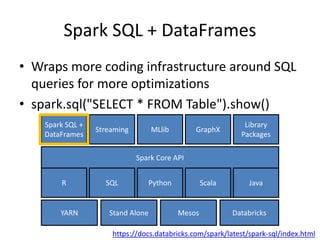
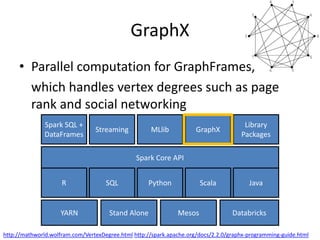
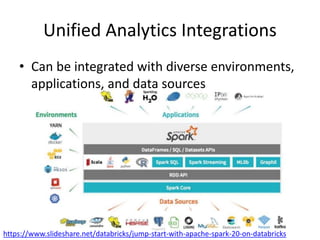
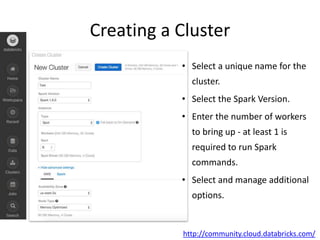
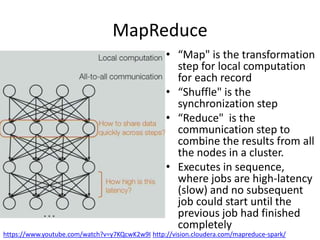
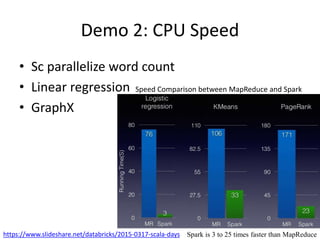
The document is a tutorial on Apache Spark 2.1, highlighting its development history, core functionalities, and various libraries for processing big data across different programming languages. It discusses features such as Spark SQL, structured streaming, machine learning libraries, and integration with cloud computing through Databricks. Additionally, it covers challenges in computational speed and data processing, emphasizing Spark's efficiency and adaptability for diverse applications.