Download to read offline





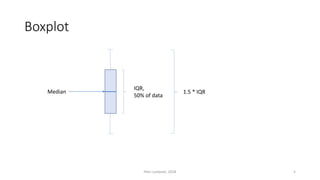


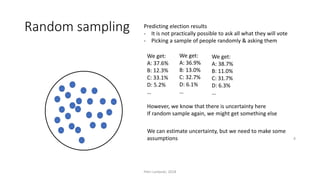
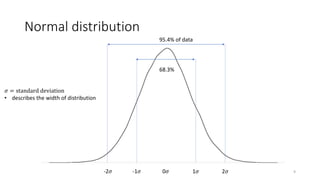
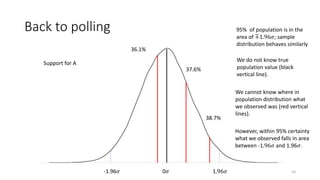
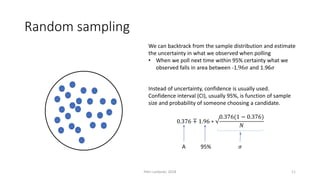
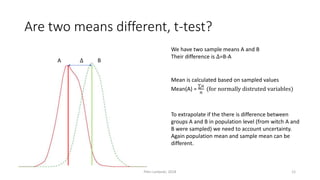
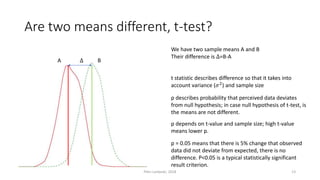

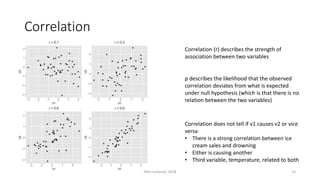

The document provides an overview of quantitative analysis techniques, including measures of central tendency (mean, median, mode) and graphical representations (line and bar charts). It discusses concepts such as hypothesis testing, confidence intervals, and correlation, emphasizing the importance of sampling and uncertainty in statistical estimations. Key statistical tests mentioned are t-tests and ANOVA, highlighting how to assess differences between means and the interpretation of statistical significance.






















































































