Download as PDF, PPTX













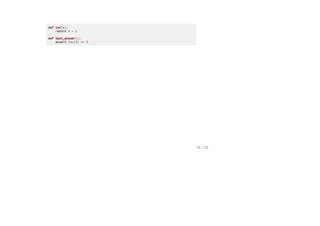
![import unittest
class TestStringMethods(unittest.TestCase):
def test_upper(self):
self.assertEqual('foo'.upper(), 'FOO')
def test_isupper(self):
self.assertTrue('FOO'.isupper())
self.assertFalse('Foo'.isupper())
def test_split(self):
s = 'hello world'
self.assertEqual(s.split(), ['hello', 'world'])
# check that s.split fails when the separator is not a string
with self.assertRaises(TypeError):
s.split(2)
if __name__ == '__main__':
unittest.main()
15 / 26](https://image.slidesharecdn.com/python-testing-frameworks-170218190939/85/Python-testing-frameworks-overview-15-320.jpg)
![$ python my_unittest.py
.F.
======================================================================
FAIL: test_split (__main__.TestStringMethods)
----------------------------------------------------------------------
Traceback (most recent call last):
File "neco.py", line 14, in test_split
self.assertEqual(s.split(), ['hellox', 'world'])
AssertionError: Lists differ: ['hello', 'world'] != ['hellox', 'world']
First differing element 0:
'hello'
'hellox'
- ['hello', 'world']
+ ['hellox', 'world']
? +
----------------------------------------------------------------------
Ran 3 tests in 0.001s
FAILED (failures=1)
16 / 26](https://image.slidesharecdn.com/python-testing-frameworks-170218190939/85/Python-testing-frameworks-overview-16-320.jpg)



![def unique_words(page):
''' Returns set of the unique words in list of lines of text
Example:
>>> from StringIO import StringIO
>>> fileText = """the cat sat on the mat
... the mat was ondur the cat
... one fish two fish red fish
... blue fish
... This fish has a yellow car
... This fish has a yellow star"""
>>> file = StringIO(fileText)
>>> page = file.readlines()
>>> words = unique_words(page)
>>> print sorted(list(words))
["This", "a", "blue", "car", "cat", "fish", "has", "mat",
"on", "ondur", "one", "red", "sat", "star", "the", "two",
"was", "yellow"]
>>>
'''
return set(word for line in page for word in line.split())
def _test():
import doctest
doctest.testmod()
if __name__ == "__main__":
_test()
21 / 26](https://image.slidesharecdn.com/python-testing-frameworks-170218190939/85/Python-testing-frameworks-overview-21-320.jpg)
![$ python2 my_doctest.py
**********************************************************************
File "neco.py", line 16, in __main__.unique_words
Failed example:
print sorted(list(words))
Expected:
["This", "a", "blue", "car", "cat", "fish", "has", "mat",
"on", "ondur", "one", "red", "sat", "star", "the", "two",
"was", "yellow"]
Got:
['This', 'a', 'blue', 'car', 'cat', 'fish', 'has', 'mat', 'on', 'ondur', 'one', 'red', 'sat', 'star', 'the', 'two', 'was', 'yellow']
**********************************************************************
1 items had failures:
1 of 6 in __main__.unique_words
***Test Failed*** 1 failures.
22 / 26](https://image.slidesharecdn.com/python-testing-frameworks-170218190939/85/Python-testing-frameworks-overview-22-320.jpg)





The document provides an overview of Python testing frameworks such as unittest, pytest, and doctest, highlighting their pros and cons. It also discusses the importance of testing in software development and the differences between various testing methods. Ultimately, it concludes that while doctests serve well for documentation purposes, pytest is seen as the leading testing framework for more comprehensive testing needs.

































































































