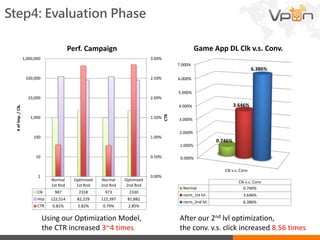
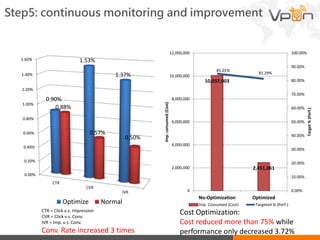
This document discusses Vpon's mobile advertising system and recommender model. It describes the basic concept, challenges, and infrastructure of Vpon's ad serving platform. It then focuses on the recommender system, outlining the design, implementation, and evaluation process. Key steps include calculating ad and user similarities, predicting user preferences, optimizing ad delivery, and continuously improving based on results. The recommender significantly increased click-through and conversion rates while reducing costs.















































![[SDX2016] 網站分析工作的領悟 / 鍾喬后 Isobar 安索帕 資料分析經理](https://cdn.slidesharecdn.com/ss_thumbnails/9-160331064815-thumbnail.jpg?width=640&height=640&fit=bounds)



![[SDX2016] 2016年 SEO 的關鍵在 UX / 連啓佑 將能數位行銷 執行長](https://cdn.slidesharecdn.com/ss_thumbnails/1-160331062451-thumbnail.jpg?width=640&height=640&fit=bounds)

































