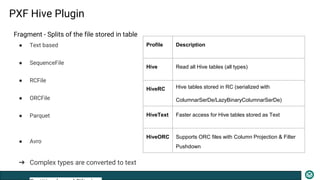
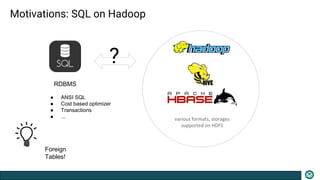
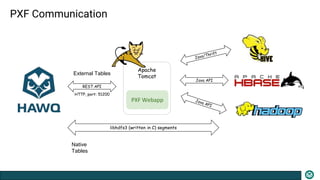
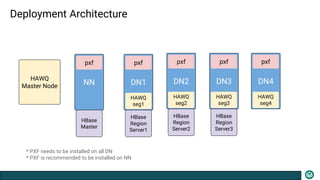
The document presents an overview of the PXF (Pivotal Extension Framework) designed for SQL access on Hadoop, detailing its architecture, components, and usage for accessing various data formats stored in HDFS. PXF facilitates a uniform tabular view to heterogeneous data sources, utilizing a pluggable framework to enable custom connectors and providing built-in connectors for popular data storage systems. Key processes such as data fragmenting, distribution, and reading are also outlined, along with references to code locations and plugins available for different data formats.












![PXF Usage
Built-in with Plugins
HDFS Hive
HBase GemfireXD
Community (https://bintray.com/big-data/maven/pxf-plugins/view )
Cassandra Accumulo
Solr
Redis Jdbc
CREATE [READABLE|WRITABLE] EXTERNAL TABLE table_name ( column_name data_type [, ...] )
LOCATION ('pxf://host[:port]/path-to-data?PROFILE=<profile-name> [&custom-option=value...]')
FORMAT '[TEXT | CSV | CUSTOM]'
(<formatting_properties>);](https://image.slidesharecdn.com/pxf-161129001637/85/PXF-HAWQ-Unmanaged-Data-16-320.jpg)