Downloaded 62 times







![10© 2015 Pivotal Software, Inc. All rights reserved.
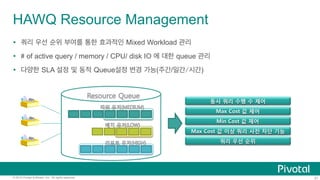
Basic
Architecture
Interconnect
Catalog
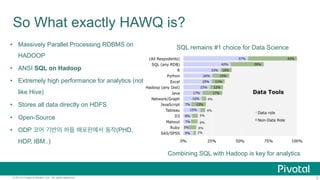
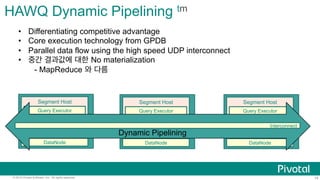
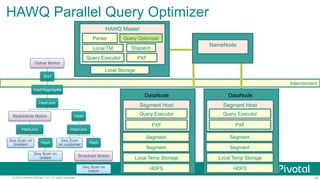
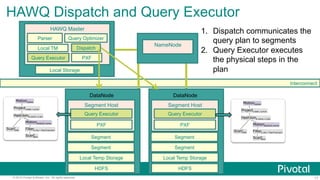
HAWQ
Master
Local
TM
Execu;on
Coordina;on
Parser
Query
Op;mizer
Dispatch
NameNode
Local
Temp
Storage
Segment
Host
Query
Executor
HDFS
PXF
Segment
[Segment
…]
DataNode
Local
Temp
Storage
Segment
Host
Query
Executor
HDFS
PXF
Segment
[Segment
…]
DataNode
HDFS
…
HAWQ
Standby
Master
Secondary
NameNode
HDFS
HAWQ](https://image.slidesharecdn.com/pivotalhawq201506-150625034640-lva1-app6891/85/Pivotal-HAWQ-10-320.jpg)
![12© 2015 Pivotal Software, Inc. All rights reserved.
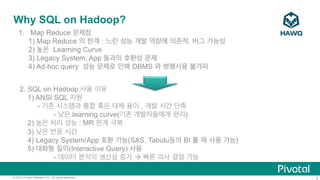
HAWQ
Segments
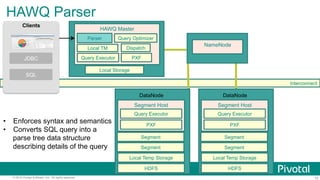
Ÿ A
HAWQ
segment
within
a
Segment
Host
is
an
HDFS
client
that
runs
on
a
DataNode
Ÿ 하나의 Segment
Host/DataNode 에 여러개의 Segment
Node
Ÿ Segment
=
a
basic
unit
of
parallelism
– Mul;ple
segments
work
together
to
form
a
single
parallel
query
processing
system
Ÿ Opera;ons
(scans,
joins,
aggrega;ons,
sorts,
etc.)
execute
in
parallel
across
all
segments
simultaneously
Ÿ Libhdfs3(Pivotal
rewri[en)
를 사용하여 더 빠른 HDFS
R/W속도
Local
Temp
Storage
Segment
Host
Query
Executor
HDFS
PXF
Segment
[Segment
…]
DataNode
HAWQ](https://image.slidesharecdn.com/pivotalhawq201506-150625034640-lva1-app6891/85/Pivotal-HAWQ-12-320.jpg)











![35© 2015 Pivotal Software, Inc. All rights reserved.
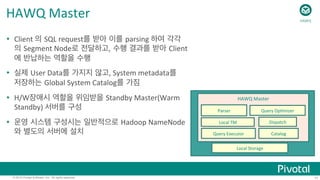
Calling
MADlib
Func;ons:
Fast
Training,
Scoring
SELECT
madlib.linregr_train(
'houses’,
'houses_linregr’,
'price’,
'ARRAY[1,
tax,
bath,
size]’);
MADlib
model
func;on
Table
containing
training
data
Table
in
which
to
save
results
Column
containing
dependent
variable
Features
included
in
the
model
Ÿ MADlib
allows
users
to
easily
and
create
models
without
moving
data
out
of
the
systems
– Model
genera;on
– Model
valida;on
– Scoring
(evalua;on
of)
new
data
Ÿ All
the
data
can
be
used
in
one
model
Ÿ Built-‐in
func;onality
to
create
of
mul;ple
smaller
models
(e.g.
classifica;on
grouped
by
feature)
Ÿ Open-‐source
lets
you
tweak
and
extend
methods,
or
build
your
own
HAWQ](https://image.slidesharecdn.com/pivotalhawq201506-150625034640-lva1-app6891/85/Pivotal-HAWQ-35-320.jpg)

![37© 2015 Pivotal Software, Inc. All rights reserved.
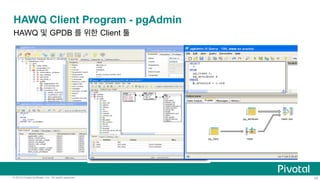
PivotalR: Bringing MADlib and HAWQ to a familiar
R interface
Ÿ Challenge
Want to harness the familiarity of R’s interface and the performance &
scalability benefits of in-DB analytics
Ÿ Simple solution:
Translate R code into SQL
d <- db.data.frame(”houses")
houses_linregr <- madlib.lm(price ~ tax
+ bath
+ size
, data=d)
Pivotal R
SELECT madlib.linregr_train( 'houses’,
'houses_linregr’,
'price’,
'ARRAY[1, tax, bath, size]’);
SQL Code
https://github.com/pivotalsoftware/PivotalR](https://image.slidesharecdn.com/pivotalhawq201506-150625034640-lva1-app6891/85/Pivotal-HAWQ-37-320.jpg)

















HAWQ is an enterprise platform that provides the fewest barriers, lowest risk, and fastest way to perform big data analytics on Hadoop. It combines SQL with Hadoop by providing ANSI SQL capabilities on Hadoop for high performance analytics. HAWQ stores all data directly on HDFS and runs on various Hadoop distributions like Pivotal HD, HDP and IBM BigInsights.















































![[2016 데이터 그랜드 컨퍼런스] 2 3(빅데이터). 엑셈 빅데이터 적용 사례 및 플랫폼 구현](https://cdn.slidesharecdn.com/ss_thumbnails/2-3-161125005014-thumbnail.jpg?width=640&height=640&fit=bounds)







































