Download to read offline
















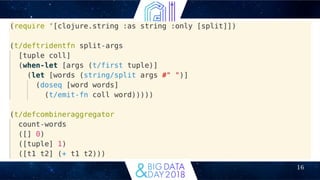


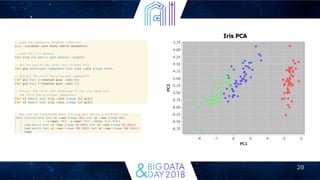





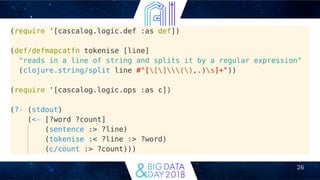
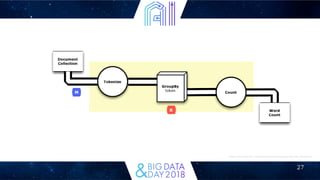





This document discusses how Clojure can be used for big data applications. It introduces Clojure and several Clojure libraries for distributed stream processing (Apache Storm) and batch processing (Apache Trident, Incanter, Cascalog). Storm is described as a distributed real-time computation system. Trident provides high-level abstractions for exactly-once processing on Storm. Incanter and Cascalog allow interactive analysis and querying of big data using a Clojure API. The document argues Clojure is well-suited for big data due to its focus on immutability, functions, and map-reduce approaches.
!["Smooth Operator" [Bay Area NewSQL meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/bayareanewsqlmeetuptidboperator-190222181157-thumbnail.jpg?width=640&height=640&fit=bounds)

![[WSO2Con USA 2018] Deploying Applications in K8S and Docker](https://cdn.slidesharecdn.com/ss_thumbnails/deployingapplicationsink8sanddocker-wso2conusa2018-180723073457-thumbnail.jpg?width=640&height=640&fit=bounds)






![Introducing TiDB Operator [Cologne, Germany]](https://cdn.slidesharecdn.com/ss_thumbnails/colognek8smeetupintroducingtidboperator-190222180135-thumbnail.jpg?width=640&height=640&fit=bounds)













































































