Download to read offline






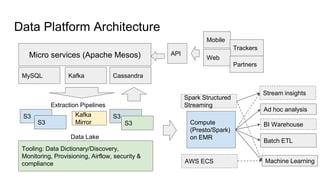
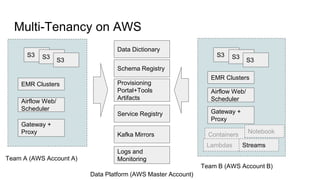



Cloud Native Data Platform at Fitbit - Fitbit collects 100 TB of user data daily from 30 million users across fitness trackers, smartwatches, and apps for internal teams like data science, research, and customer support as well as enterprise wellness programs. - The data platform includes MySQL, Kafka, Cassandra, S3, EMR, Presto/Spark and supports both batch and real-time workflows across multiple AWS accounts for compliance. - Key challenges included diverse user needs, multiple compliance requirements, and a lean team. The multi-tenant architecture in AWS with fine-grained S3 buckets and IAM roles helps address these challenges.





















![How does Riak compare to Cassandra? [Cassandra London User Group July 2011]](https://cdn.slidesharecdn.com/ss_thumbnails/cassandralondonugjuly2011-110720110309-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)










