Downloaded 15 times











![Techniques
Nicolas Bettenburg, Stephen W. Thomas, Ahmed E. Hassan: Using Fuzzy Code Search to Link Code
Fragments in Discussions to Source Code. CSMR 2012: 319-328
Using Fuzzy Code Search to Link Code Fragments
in Discussions to Source Code
Nicolas Bettenburg, Stephen W. Thomas, Ahmed E. Hassan
Software Analysis and Intelligence Lab (SAIL)
School of Computing, Queen’s University
Kingston, Ontario, Canada
Email: {nicbet, sthomas, ahmed}@cs.queensu.ca
Abstract—When discussing software, practitioners often ref-
erence parts of the project’s source code. Such references
have different motivations, such as mentoring and guiding less
experienced developers, pointing out code that needs changes,
or proposing possible strategies for the implementation of future
changes. The fact that particular parts of a source code are being
discussed makes these parts of the software special. Knowing
which code is being talked about the most can not only help
practitioners to guide important software engineering and main-
tenance activities, but also act as a high-level documentation of
development activities for managers. In this paper, we use clone-
detection as specific instance of a code search based approach
for establishing links between code fragments that are discussed
by developers and the actual source code of a project. Through
a case study on the Eclipse project we explore the traceability
links established through this approach, both quantitatively and
qualitatively, and compare fuzzy code search based traceability
linking to classical approaches, in particular change log analysis
and information retrieval. We demonstrate a sample application
of code search based traceability links by visualizing those parts
of the project that are most discussed in issue reports with
a Treemap visualization. The results of our case study show
that the traceability links established through fuzzy code search-
Past approaches to uncovering traceability links between doc-
umentation and source code are commonly based on in-
formation retrieval [2], [15], [18], [20], natural language
processing [1], [19] and lightweight textual analyses [5], [11],
[12]. Each approach, however, is tailored towards a specific
set of goals and use cases. For example, when linking code
changes to issue reports by analyzing transaction logs [28],
we observe only the associations between a bug report and
the final locations of the bug fix, but miss the bug fixing
history: all the locations that a developer had to investigate
and understand before he could find an appropriate way to fix
the error.
In this paper, we aim to find traceability links between
issue reports and source code. For this purpose, we propose
a new approach that uses token-based clone detection as an
implementation of fuzzy code search for discovering links
between code fragments mentioned in project discussions and
the location of these fragments in the source code body of a
software system. In a case study on the ECLIPSE project, we
Using Fuzzy Code Search to Link Code Fragments
in Discussions to Source Code
Nicolas Bettenburg, Stephen W. Thomas, Ahmed E. Hassan
Software Analysis and Intelligence Lab (SAIL)
School of Computing, Queen’s University
Kingston, Ontario, Canada
Email: {nicbet, sthomas, ahmed}@cs.queensu.ca
Abstract—When discussing software, practitioners often ref-Abstract—When discussing software, practitioners often ref-Abstract
erence parts of the project’s source code. Such references
have different motivations, such as mentoring and guiding less
experienced developers, pointing out code that needs changes,
or proposing possible strategies for the implementation of future
changes. The fact that particular parts of a source code are being
discussed makes these parts of the software special. Knowing
which code is being talked about the most can not only help
practitioners to guide important software engineering and main-
tenance activities, but also act as a high-level documentation of
Past approaches to uncovering traceability links between doc-
umentation and source code are commonly based on in-
formation retrieval [2], [15], [18], [20], natural language
processing [1], [19] and lightweight textual analyses [5], [11],
[12]. Each approach, however, is tailored towards a specific
set of goals and use cases. For example, when linking code
changes to issue reports by analyzing transaction logs [28],
we observe only the associations between a bug report and](https://image.slidesharecdn.com/mud-tutorial-150929085346-lva1-app6892/75/Put-Your-Hands-in-the-Mud-What-Technique-Why-and-How-14-2048.jpg)







![Not all reviews are equal
AR-Miner: Mining Informative Reviews for Developers from
Mobile App Marketplace
Ning Chen, Jialiu Lin†
, Steven C. H. Hoi, Xiaokui Xiao, Boshen Zhang
Nanyang Technological University, Singapore, †
Carnegie Mellon University, USA
{nchen1,chhoi,xkxiao,bszhang}@ntu.edu.sg, †
jialiul@cs.cmu.edu
ABSTRACT
With the popularity of smartphones and mobile devices, mo-
bile application (a.k.a. “app”) markets have been growing
exponentially in terms of number of users and download-
s. App developers spend considerable e↵ort on collecting
and exploiting user feedback to improve user satisfaction,
but su↵er from the absence of e↵ective user review ana-
lytics tools. To facilitate mobile app developers discover
the most “informative” user reviews from a large and rapid-
ly increasing pool of user reviews, we present “AR-Miner”
— a novel computational framework for App Review Min-
ing, which performs comprehensive analytics from raw user
reviews by (i) first extracting informative user reviews by
filtering noisy and irrelevant ones, (ii) then grouping the in-
formative reviews automatically using topic modeling, (iii)
further prioritizing the informative reviews by an e↵ective
review ranking scheme, (iv) and finally presenting the group-
s of most “informative” reviews via an intuitive visualization
approach. We conduct extensive experiments and case s-
tudies on four popular Android apps to evaluate AR-Miner,
intense, in order to seize the initiative, developers tend to
employ an iterative process to develop, test, and improve
apps [23]. Therefore, timely and constructive feedback from
users becomes extremely crucial for developers to fix bugs,
implement new features, and improve user experience ag-
ilely. One key challenge to many app developers is how to
obtain and digest user feedback in an e↵ective and e cient
manner, i.e., the “user feedback extraction” task. One way
to extract user feedback is to adopt typical channels used
in traditional software development, such as (i) bug/change
repositories (e.g., Bugzilla [3]), (ii) crash reporting systems
[19], (iii) online forums (e.g., SwiftKey feedback forum [6]),
and (iv) emails [10].
Unlike the traditional channels, modern app marketplaces,
such as Apple App Store and Google Play, o↵er a much eas-
ier way (i.e., the web-based market portal and the market
app) for users to rate and post app reviews. These reviews
present user feedback on various aspects of apps (such as
functionality, quality, performance, etc), and provide app
developers a new and critical channel to extract user feed-
AR-Miner: Mining Informative Reviews for Developers from
Mobile App Marketplace
Ning Chen, Jialiu Lin†
, Steven C. H. Hoi, Xiaokui Xiao, Boshen Zhang
Nanyang Technological University, Singapore, †
Carnegie Mellon University, USA
{nchen1,chhoi,xkxiao,bszhang}@ntu.edu.sg, †
jialiul@cs.cmu.edu
ABSTRACT
With the popularity of smartphones and mobile devices, mo-
bile application (a.k.a. “app”) markets have been growing
exponentially in terms of number of users and download-
s. App developers spend considerable e↵ort on collecting↵ort on collecting↵
and exploiting user feedback to improve user satisfaction,
but su↵er from the absence of e↵er from the absence of e↵ ↵ective user review ana-↵ective user review ana-↵
lytics tools. To facilitate mobile app developers discover
the most “informative” user reviews from a large and rapid-
ly increasing pool of user reviews, we present “AR-Miner”
intense, in order to seize the initiative, developers tend to
employ an iterative process to develop, test, and improve
apps [23]. Therefore, timely and constructive feedback from
users becomes extremely crucial for developers to fix bugs,
implement new features, and improve user experience ag-
ilely. One key challenge to many app developers is how to
obtain and digest user feedback in an e↵ective and e↵ective and e↵ cient
manner, i.e., the “user feedback extraction” task. One way
to extract user feedback is to adopt typical channels used
in traditional software development, such as (i) bug/change
repositories (e.g., Bugzilla [3]), (ii) crash reporting systems
Ning Chen, Jialiu Lin, Steven C. H. Hoi, Xiaokui Xiao, Boshen Zhang:AR-miner: mining
informative reviews for developers from mobile app marketplace. ICSE 2014: 767-778](https://image.slidesharecdn.com/mud-tutorial-150929085346-lva1-app6892/75/Put-Your-Hands-in-the-Mud-What-Technique-Why-and-How-23-2048.jpg)


![@ICSME 2015
Thurdsay, 13.50 - Mobile applications
User Reviews Matter! Tracking Crowdsourced
Reviews to Support Evolution of Successful Apps
Fabio Palomba⇤, Mario Linares-V´asquez§, Gabriele Bavota†, Rocco Oliveto‡,
Massimiliano Di Penta¶, Denys Poshyvanyk§, Andrea De Lucia⇤
⇤University of Salerno, Fisciano (SA), Italy – §The College of William and Mary, VA, USA
†Free University of Bozen-Bolzano, Bolzano (BZ), Italy – ‡University of Molise, Pesche (IS), Italy
¶University of Sannio, Benevento, Italy
Abstract—Nowadays software applications, and especially mo-
bile apps, undergo frequent release updates through app stores.
After installing/updating apps, users can post reviews and provide
ratings, expressing their level of satisfaction with apps, and
possibly pointing out bugs or desired features. In this paper
we show—by performing a study on 100 Android apps—how
applications addressing user reviews increase their success in
terms of rating. Specifically, we devise an approach, named
CRISTAL, for tracing informative crowd reviews onto source
code changes, and for monitoring the extent to which developers
accommodate crowd requests and follow-up user reactions as
reflected in their ratings. The results indicate that developers
implementing user reviews are rewarded in terms of ratings. This
poses the need for specialized recommendation systems aimed at
analyzing informative crowd reviews and prioritizing feedback
to be satisfied in order to increase the apps success.
systems, and network conditions that may not necessarily be
reproducible during development/testing activities.
Consequently, by reading reviews and analyzing the ratings,
development teams are encouraged to improve their apps, for
example, by fixing bugs or by adding commonly requested
features. According to a recent Gartner report’s recommenda-
tion [21], given the complexity of mobile testing “development
teams should monitor app store reviews to identify issues that
are difficult to catch during testing, and to clarify issues that
cause problems on the users’s side”. Moreover, useful app
reviews reflect crowd-based needs and are a valuable source
of comments, bug reports, feature requests, and informal user
experience feedback [7], [8], [14], [19], [22], [27], [29].
In this paper we investigate to what extent app development
User Reviews Matter! Tracking Crowdsourced
Reviews to Support Evolution of Successful Apps
Fabio Palomba⇤, Mario Linares-V´asquez§, Gabriele Bavota†, Rocco Oliveto‡,
Massimiliano Di Penta¶, Denys Poshyvanyk§, Andrea De Lucia⇤
⇤University of Salerno, Fisciano (SA), Italy – §The College of William and Mary, VA, USA
†Free University of Bozen-Bolzano, Bolzano (BZ), Italy – ‡University of Molise, Pesche (IS), Italy
¶University of Sannio, Benevento, Italy
Abstract—Nowadays software applications, and especially mo-Abstract—Nowadays software applications, and especially mo-Abstract
bile apps, undergo frequent release updates through app stores.
After installing/updating apps, users can post reviews and provide
ratings, expressing their level of satisfaction with apps, and
possibly pointing out bugs or desired features. In this paper
we show—by performing a study on 100 Android apps—how
applications addressing user reviews increase their success in
terms of rating. Specifically, we devise an approach, named
CRISTAL, for tracing informative crowd reviews onto source
code changes, and for monitoring the extent to which developers
accommodate crowd requests and follow-up user reactions as
systems, and network conditions that may not necessarily be
reproducible during development/testing activities.
Consequently, by reading reviews and analyzing the ratings,
development teams are encouraged to improve their apps, for
example, by fixing bugs or by adding commonly requested
features. According to a recent Gartner report’s recommenda-
tion [21], given the complexity of mobile testing “development
teams should monitor app store reviews to identify issues that
are difficult to catch during testing, and to clarify issues that
cause problems on the users’s side”. Moreover, useful app](https://image.slidesharecdn.com/mud-tutorial-150929085346-lva1-app6892/75/Put-Your-Hands-in-the-Mud-What-Technique-Why-and-How-26-2048.jpg)




















![Approach
Alberto Bacchelli, Tommaso Dal Sasso, Marco D'Ambros, Michele Lanza: Content classification of
development emails. ICSE 2012: 375-385
Content Classification of Development Emails
Alberto Bacchelli, Tommaso Dal Sasso, Marco D’Ambros, Michele Lanza
REVEAL @ Faculty of Informatics — University of Lugano, Switzerland
Abstract—Emails related to the development of a software
system contain information about design choices and issues
encountered during the development process. Exploiting the
knowledge embedded in emails with automatic tools is chal-
lenging, due to the unstructured, noisy and mixed language
nature of this communication medium. Natural language text
is often not well-formed and is interleaved with languages with
other syntaxes, such as code or stack traces.
We present an approach to classify email content at line
level. Our technique classifies email lines in five categories (i.e.,
text, junk, code, patch, and stack trace) to allow one to sub-
sequently apply ad hoc analysis techniques for each category.
We evaluated our approach on a statistically significant set
of emails gathered from mailing lists of four unrelated open
source systems.
Keywords-Empirical software engineering; Unstructured
Data Mining; Emails
I. Introduction
Software repositories supply information useful for sup-
porting software analysis and program comprehension [17].
Di↵erent repositories o↵er di↵erent perspectives on systems:
(e.g., IRC chat logs, mailing lists) require the most care, as
the documents leave complete freedom to the authors. For
example, Bettenburg et al. presented the risks of using email
data without a proper cleaning pre-processing phase [9].
NL documents are usually treated as bags of words–a
count of terms’ occurrences. This simplification is proven
to be e↵ective in the information retrieval (IR) field, where
techniques are tested on well-formed NL documents [25]. In
software engineering, although e↵ective for some tasks (e.g.,
traceability between documents and code [1]), this approach
reduces the quality, reliability, and comprehensibility of the
available information, as NL text is often not well-formed
and is interleaved with languages with di↵erent syntaxes:
code fragments, stack traces, patches, etc.
We present a work for advancing the analysis of the
contents of development emails. We argue that we should not
create a single bag with terms indiscriminately coming from
NL parts, code fragments, email signatures, patches, etc. and
treat them equally. We need to recognize every language in
an email to enable techniques exploiting the peculiarities of
Content Classification of Development Emails
Alberto Bacchelli, Tommaso Dal Sasso, Marco D’Ambros, Michele Lanza
REVEAL @ Faculty of Informatics — University of Lugano, Switzerland
Abstract—Emails related to the development of a softwareAbstract—Emails related to the development of a softwareAbstract
system contain information about design choices and issues
encountered during the development process. Exploiting the
knowledge embedded in emails with automatic tools is chal-
lenging, due to the unstructured, noisy and mixed language
nature of this communication medium. Natural language text
is often not well-formed and is interleaved with languages with
other syntaxes, such as code or stack traces.
We present an approach to classify email content at line
level. Our technique classifies email lines in five categories (i.e.,
text, junk, code, patch, and stack trace) to allow one to sub-
(e.g., IRC chat logs, mailing lists) require the most care, as
the documents leave complete freedom to the authors. For
example, Bettenburg et al. presented the risks of using email
data without a proper cleaning pre-processing phase [9].
NL documents are usually treated as bags of words–a
count of terms’ occurrences. This simplification is proven
to be e↵ective in the information retrieval (IR) field, where↵ective in the information retrieval (IR) field, where↵
techniques are tested on well-formed NL documents [25]. In
software engineering, although e↵ective for some tasks (↵ective for some tasks (↵ e.g.,](https://image.slidesharecdn.com/mud-tutorial-150929085346-lva1-app6892/75/Put-Your-Hands-in-the-Mud-What-Technique-Why-and-How-47-2048.jpg)
![Alternative approach
Lines/paragraphs belonging to different
elements contain different proportions of
keywords, special characters, etc.
Alberto Bacchelli, Marco D'Ambros, Michele Lanza: Extracting Source Code from E-Mails. ICPC 2010: 24-33
Extracting Source Code from E-Mails
Alberto Bacchelli, Marco D’Ambros, Michele Lanza
REVEAL@ Faculty of Informatics - University of Lugano, Switzerland
Abstract—E-mails, used by developers and system users to
communicate over a broad range of topics, offer a valuable
source of information. If archived, e-mails can be mined to
support program comprehension activities and to provide views
of a software system that are alternative and complementary
to those offered by the source code.
However, e-mails are written in natural language, and
therefore contain noise that makes it difficult to retrieve the
important data. Thus, before conducting an effective system
analysis and extracting data for program comprehension, it is
necessary to select the relevant messages, and to expose only
the meaningful information.
In this work we focus both on classifying e-mails that hold
fragments of the source code of a system, and on extracting the
source code pieces inside the e-mail. We devised and analyzed a
number of lightweight techniques to accomplish these tasks. To
assess the validity of our techniques, we manually inspected and
annotated a statistically significant number of e-mails from five
unrelated open source software systems written in Java. With
such a benchmark in place, we measured the effectiveness of
each technique in terms of precision and recall.
about a system. E-mails are used to discuss issues ranging
from low-level decisions (e.g., implementation strategies, bug
fixing) up to high-level considerations (e.g., design rationale,
future planning). Our goal is to use this kind of artifacts to
enhance program comprehension and analysis.
We already devised techniques to recover the traceability
links between source code entities and e-mails [4]. However,
such ties can only be retrieved by knowing the entities of
the system in advance, i.e., by having the model of the
system generated from the source code. In this paper we
tackle a different problem: We want to extract source code
fragments from e-mail messages. To do this, we first need
to select e-mails that contain source code fragments, and
then we extract such fragments from the content in which
they are enclosed. Separating source code from natural
language in e-mail messages brings several benefits: The
access to structured data (1) facilitates the reconstruction
Extracting Source Code from E-Mails
Alberto Bacchelli, Marco D’Ambros, Michele Lanza
REVEAL@ Faculty of Informatics - University of Lugano, Switzerland
Abstract—E-mails, used by developers and system users toAbstract—E-mails, used by developers and system users toAbstract
communicate over a broad range of topics, offer a valuable
source of information. If archived, e-mails can be mined to
support program comprehension activities and to provide views
of a software system that are alternative and complementary
to those offered by the source code.
However, e-mails are written in natural language, and
therefore contain noise that makes it difficult to retrieve the
important data. Thus, before conducting an effective system
analysis and extracting data for program comprehension, it is
necessary to select the relevant messages, and to expose only
the meaningful information.
In this work we focus both on classifying e-mails that hold
about a system. E-mails are used to discuss issues ranging
from low-level decisions (e.g., implementation strategies, bug
fixing) up to high-level considerations (e.g., design rationale,
future planning). Our goal is to use this kind of artifacts to
enhance program comprehension and analysis.
We already devised techniques to recover the traceability
links between source code entities and e-mails [4]. However,
such ties can only be retrieved by knowing the entities of
the system in advance, i.e., by having the model of the
system generated from the source code. In this paper we
tackle a different problem: We want to extract source code](https://image.slidesharecdn.com/mud-tutorial-150929085346-lva1-app6892/75/Put-Your-Hands-in-the-Mud-What-Technique-Why-and-How-48-2048.jpg)

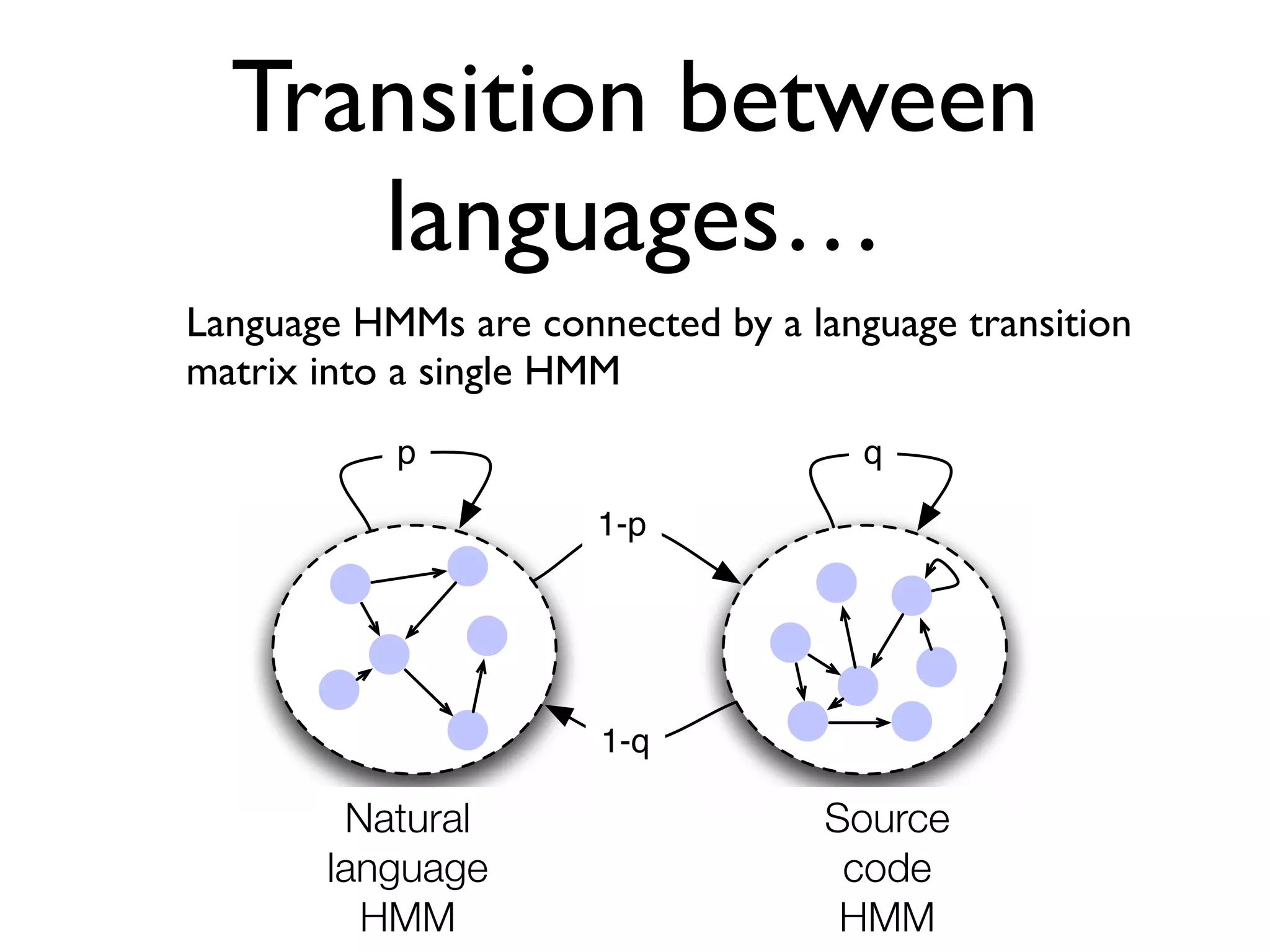
![Hidden Markov Models
A language category is modeled as an HMM where hidden
states are language tokens
0.28
0.23
0.6
0.49
0.36
0.36
0.38
0.52
0.430.25
0.31
0.31
0.77
0.34
0.51
0.47
0.52
0.26
0.38
0.71
0.27
0.47
0.65
0.34
0.4
0.4
0.65
0.54
0.41
0.22
0.39
0.21
0.32
0.37
0.9
0.43
0.27
0.3
0.9
0.62
0.38
0.6
0.22
0.25
0.31
0.4
0.97
0.41
0.36
0.36
0.21
0.93
0.91
]
=
~
!
'
`
NUM
(
[
#
<
-
:
,
{
)
NEWLN
KEY
$
}
+
.
*
;
&
/
^
|
%
"
?
@
WORD
UNDSC
>
Fig. 4. A source code HMM trained on PosgreSQL source code (transition
probabilities less than 0.2 are not shown).
syntaxes. For example, in development mailing list messages
usually there is no more than one source code fragment in
a text message. If this is the case, we can assume, a priori,
the transition probability from natural language text to source
code approximated to 1/N, where N is the number of tokens
in the message. It could happens that the transition between
two language syntaxes could never occur. This may be the case
of stack traces and patches. By observing developers’ emails,
it is usual to notice that, after a stack trace is provided, the
resolution patch is introduced with natural language phrases,
such as “Here is the change that we made to fix the problem”.
This leads to a null transition probability from stack trace
to patch code. Other heuristics could be adopted to refine
the estimation of transition probabilities that reflects specific
properties or styles adopted [23].
IV. EMPIRICAL EVALUATION PROCEDURE
To evaluate the effectiveness of our approach we adopt
the Precision and Recall metrics, known respectively also
as Positive Predictive Value (PPV) and Sensitivity [24]. In
particular, for each language syntax, i, we compute:
such as opening parenthesis. Formally, the HMM state space
is defined as:
Q = { T XT , SRC}
where T XT = {WORDT XT , KEYT XT , . . . }, and SRC
= {WORDSRC, KEYSRC, . . . }. Each state emits the corre-
sponding alphabet symbol without subscript label T XT or
SRC. For example, the KEY symbol can be emitted by
KEYT XT or KEYSRC with a probability equal to 1. If the
probability for staying in a natural language text is p and
the probability of staying in source code text is q, then the
transition from a state in T XT to a state in SRC is 1 p,
instead the inverse transition is 1 q. The above defined HMM
emits the sequence of symbols observed in a text by evolving
through a sequence of states { 1, 2, . . . , i, i+1, . . . } with
the transition probabilities tkl defined as:
tkl = P( i = l| i 1 = k) · p, if k, l ⇤ T XT
tkl = P( i = l| i 1 = k) · q, if k, l ⇤ SRC
tkl =
1 p
| |
, if k ⇤ T XT , l ⇤ SRC
tkl =
1 q
| |
, if k ⇤ SRC, l ⇤ T XT
and the emission probabilities defined as:
ekb = 1, if k = bT XT or k = bSRC, otherwise 0.
Fig. 2 shows the global HMM composed by two sub-HMM,
one modeling natural language text and another modeling
source code. Fig. 3 and Fig. 4 show their transition proba-
bilities, estimated on the Frankenstein novel and PostgreSQL
source code respectively. We detail in Section III-D how these
probabilities could be estimated.
It is interesting to observe how typical token sequences
are modeled by each HMM. For example, in the source code
of an arithmetic/logic expressions, array indexing, or function
argument enumeration.
Fig. 2. The source code – natural text island HMM.
0.33
0.67
0.78
0.86
0.82
0.78
0.65
0.12
0.68
0.64
0.87
0.7
0.71
0.9
0.81
0.71
0.5
0.54
1.0
1.0
1.0
1.0
0.11
0.11
0.21
0.14
0.15
0.14
0.73
0.2 0.45
0.21
1.0
0.17
0.120.12
0.14
0.29
0.33
]
WORD
KEY
!
"
@
'
?
(
*
.
NUM
:
NEWLN
$
)
[
UNDSC
-
/
;
%
,
Fig. 3. A natural text HMM trained on the Frankenstein novel (transition
probabilities less than 0.1 are not shown).
C. An extension of the basic model](https://image.slidesharecdn.com/mud-tutorial-150929085346-lva1-app6892/75/Put-Your-Hands-in-the-Mud-What-Technique-Why-and-How-50-2048.jpg)

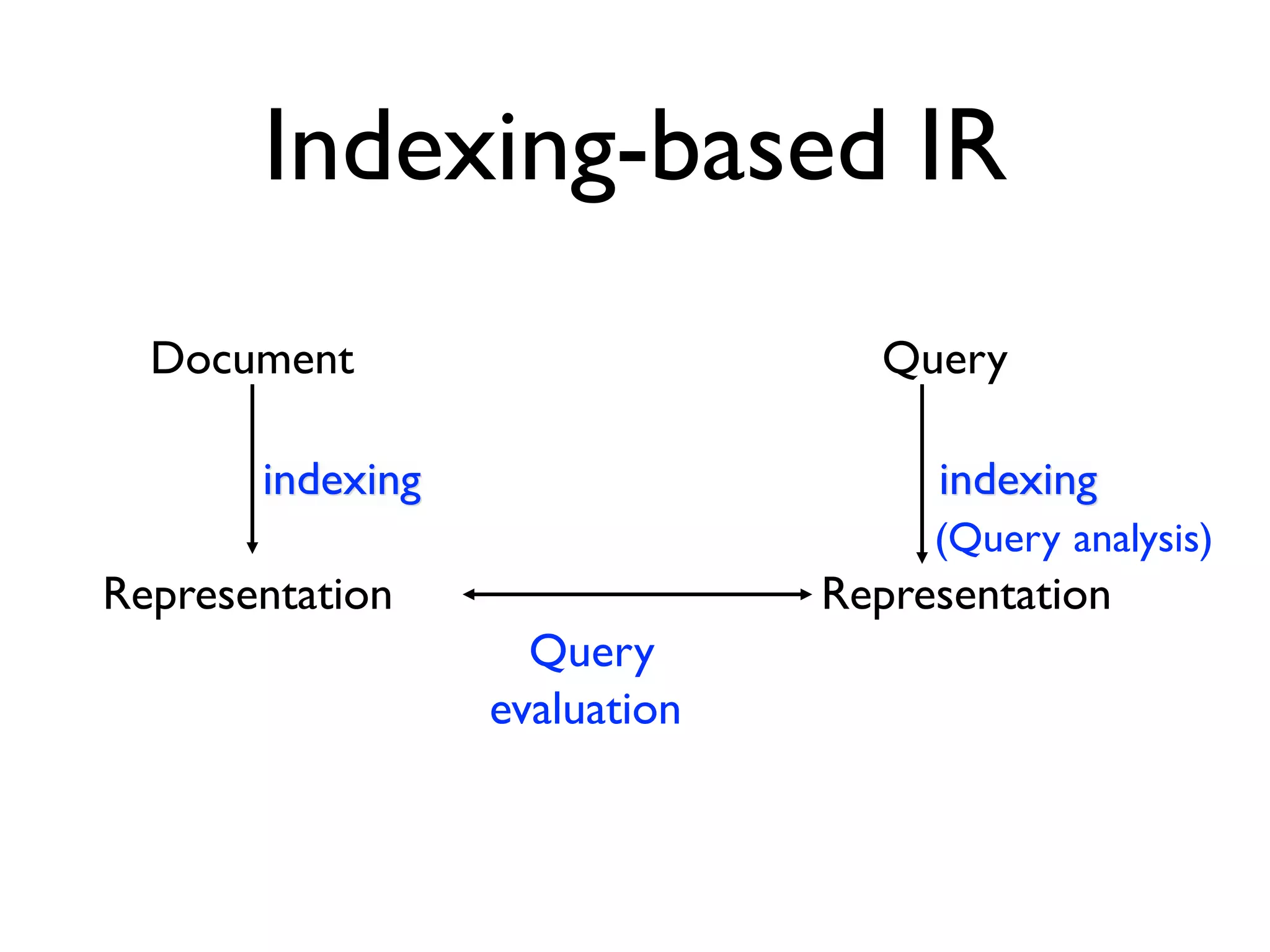






![Use of smoothing filters
Andrea De Lucia, Massimiliano Di Penta, Rocco Oliveto, Annibale Panichella, Sebastiano Panichella: Applying a
smoothing filter to improve IR-based traceability recovery processes: An empirical investigation. Information &
Software Technology 55(4): 741-754 (2013)
Applying a smoothing Ä lter to improve IR-based traceability recovery processes: An
empirical investigation q
Andrea De Lucia a
, Massimiliano Di Penta b,⇑
, Rocco Oliveto c
, Annibale Panichella a
, Sebastiano Panichella b
a
University of Salerno, Via Ponte don Melillo, 84084 Fisciano (SA), Italy
b
University of Sannio, Viale Traiano, 82100 Benevento, Italy
c
University of Molise, C.da Fonte Lappone, 86090 Pesche (IS), Italy
a r t i c l e i n f o
Article history:
Available online 24 August 2012
Keywords:
Software traceability
Information retrieval
Smoothing Ä lters
Empirical software engineering
a b s t r a c t
Context: Traceability relations among software artifacts often tend to be missing, outdated, or lost. For
this reason, various traceability recovery approachesˆ based on Information Retrieval (IR) techniquesˆ
have been proposed. The performances of such approaches are often inÅ uenced by ` ` noise' ' contained
in software artifacts (e.g., recurring words in document templates or other words that do not contribute
to the retrieval itself).
Aim: As a complement and alternative to stop word removal approaches, this paper proposes the use of a
smoothing Ä lter to remove ` ` noise' ' from the textual corpus of artifacts to be traced.
Method: We evaluate the effect of a smoothing Ä lter in traceability recovery tasks involving different
kinds of artifacts from Ä ve software projects, and applying three different IR methods, namely Vector
Space Models, Latent Semantic Indexing, and Jensenç Shannon similarity model.
Results: Our study indicates that, with the exception of some speciÄ c kinds of artifacts (i.e., tracing test
cases to source code) the proposed approach is able to signiÄ cantly improve the performances of trace-
ability recovery, and to remove ` ` noise' ' that simple stop word Ä lters cannot remove.
Conclusions: The obtained results not only help to develop traceability recovery approaches able to work
in presence of noisy artifacts, but also suggest that smoothing Ä lters can be used to improve perfor-
mances of other software engineering approaches based on textual analysis.
Ó 2012 Elsevier B.V. All rights reserved.
1. Introduction
In recent and past years, textual analysis has been successfully
applied to several kinds of software engineering tasks, for example
impact analysis [1], clone detection [2], feature location [3,4],
refactoring [5], deÄ nition of new cohesion and coupling metrics
[6,7], software quality assessment [8ç 11], and, last but not least,
traceability recovery [12ç 14].
Such a kind of analysis demonstrated to be effective and useful
for various reasons:
it is lightweight and to some extent independent on the pro-
gramming language, as it does not require a full source code
parsing, but only its tokenization and (for some applications)
lexical analysis;
it provides information (e.g., brought in comments and identiÄ -
ers) complementary to what structural or dynamic analysis can
provide [6,7];
it models software artifacts as textual documents, thus can be
applied to different kinds of artifacts (i.e., it is not limited to
the source code) and, above all, can be used to perform com-
bined analysis of different kinds of artifacts (e.g., requirements
and source code), as in the case of traceability recovery.
Textual analysis has also some weaknesses, and poses chal-
lenges for researchers. It strongly depends on the quality of the lex-
icon: a bad lexicon often means inaccurateˆ if not completely
wrongˆ results. There are two common problems in the textual
analysis of software artifacts. The Ä rst is represented by the pres-
ence of inconsistent terms in related documents (e.g., require-
q
This paper is an extension of the work ` ` Improving IR-based Traceability
Recovery Using Smoothing Filters' ' appeared in the Proceedings of the 19th IEEE
International Conference on Program Comprehension, Kingston, ON, Canada, pp. 21ç
Information and Software Technology 55 (2013) 741ç 754
Contents lists available at SciVerse ScienceDirect
Information and Software Technology
journal homepage: www.elsevier.com/locate/infsof
Applying a smoothing Ä lter to improve IR-based traceability recovery processes: An
empirical investigation q
Andrea De Lucia a
, Massimiliano Di Penta b,⇑
, Rocco Oliveto c
, Annibale Panichella a
, Sebastiano Panichella b
a
University of Salerno, Via Ponte don Melillo, 84084 Fisciano (SA), Italy
b
University of Sannio, Viale Traiano, 82100 Benevento, Italy
c
University of Molise, C.da Fonte Lappone, 86090 Pesche (IS), Italy
a r t i c l e i n f o
Article history:
Available online 24 August 2012
Keywords:
Software traceability
Information retrieval
Smoothing Ä lters
Empirical software engineering
a b s t r a c t
Context: Traceability relations among software artifacts often tend to be missing, outdated, or lost. For
this reason, various traceability recovery approachesˆ based on Information Retrieval (IR) techniquesˆ
have been proposed. The performances of such approaches are often inÅ uenced by ` ` noise' ' contained
in software artifacts (e.g., recurring words in document templates or other words that do not contribute
to the retrieval itself).
Aim: As a complement and alternative to stop word removal approaches, this paper proposes the use of a
smoothing Ä lter to remove ` ` noise' ' from the textual corpus of artifacts to be traced.
Method: We evaluate the effect of a smoothing Ä lter in traceability recovery tasks involving different
kinds of artifacts from Ä ve software projects, and applying three different IR methods, namely Vector
Space Models, Latent Semantic Indexing, and Jensenç Shannon similarity model.
Results: Our study indicates that, with the exception of some speciÄ c kinds of artifacts (i.e., tracing test
cases to source code) the proposed approach is able to signiÄ cantly improve the performances of trace-
ability recovery, and to remove ` ` noise' ' that simple stop word Ä lters cannot remove.
Conclusions: The obtained results not only help to develop traceability recovery approaches able to work
in presence of noisy artifacts, but also suggest that smoothing Ä lters can be used to improve perfor-
mances of other software engineering approaches based on textual analysis.
Ó 2012 Elsevier B.V. All rights reserved.
1. Introduction
In recent and past years, textual analysis has been successfully
applied to several kinds of software engineering tasks, for example
impact analysis [1], clone detection [2], feature location [3,4],
refactoring [5], deÄ nition of new cohesion and coupling metrics
parsing, but only its tokenization and (for some applications)
lexical analysis;
it provides information (e.g., brought in comments and identiÄ -
ers) complementary to what structural or dynamic analysis can
provide [6,7];
it models software artifacts as textual documents, thus can be](https://image.slidesharecdn.com/mud-tutorial-150929085346-lva1-app6892/75/Put-Your-Hands-in-the-Mud-What-Technique-Why-and-How-60-2048.jpg)












![Applications
Alessandra Gorla, Ilaria Tavecchia, Florian Gross, Andreas Zeller: Checking app behavior
against app descriptions. ICSE 2014: 1025-1035
Checking App Behavior Against App Descriptions
Alessandra Gorla · Ilaria Tavecchia⇤
· Florian Gross · Andreas Zeller
Saarland University
Saarbrücken, Germany
{gorla, tavecchia, fgross, zeller}@cs.uni-saarland.de
ABSTRACT
How do we know a program does what it claims to do? After clus-
tering Android apps by their description topics, we identify outliers
in each cluster with respect to their API usage. A “weather” app that
sends messages thus becomes an anomaly; likewise, a “messaging”
app would typically not be expected to access the current location.
Applied on a set of 22,500+ Android applications, our CHABADA
prototype identified several anomalies; additionally, it flagged 56%
of novel malware as such, without requiring any known malware
patterns.
Categories and Subject Descriptors
D.4.6 [Security and Protection]: Invasive software
General Terms
Security
Keywords
Android, malware detection, description analysis, clustering
1. INTRODUCTION
Checking whether a program does what it claims to do is a long-
standing problem for developers. Unfortunately, it now has become
a problem for computer users, too. Whenever we install a new app,
1. App collection 2. Topics
Weather,
Map…
Travel,
Map…
Theme
3. Clusters
Weather
+ Travel
Themes
Access-LocationInternet Access-LocationInternet Send-SMS
4. Used APIs 5. Outliers
Weather
+ Travel
Figure 1: Detecting applications with unadvertised behavior.
Starting from a collection of “good” apps (1), we identify their
description topics (2) to form clusters of related apps (3). For
each cluster, we identify the sentitive APIs used (4), and can
then identify outliers that use APIs that are uncommon for that
cluster (5).
• An app that sends a text message to a premium number to
raise money is suspicious? Maybe, but on Android, this is a
Checking App Behavior Against App Descriptions
Alessandra Gorla · Ilaria Tavecchia⇤
· Florian Gross · Andreas Zeller
Saarland University
Saarbrücken, Germany
{gorla, tavecchia, fgross, zeller}@cs.uni-saarland.de
ABSTRACT
How do we know a program does what it claims to do? After clus-
tering Android apps by their description topics, we identify outliers
in each cluster with respect to their API usage. A “weather” app that
sends messages thus becomes an anomaly; likewise, a “messaging”
app would typically not be expected to access the current location.
Applied on a set of 22,500+ Android applications, our CHABADA
prototype identified several anomalies; additionally, it flagged 56%
of novel malware as such, without requiring any known malware
patterns.
Categories and Subject Descriptors
D.4.6 [Security and Protection]: Invasive software
General Terms
Security
1. App collection 2. Topics
Weather,
Map…Map…
Travel,
Map…
Theme
3. Clusters
Weather
+ Travel+ Travel
ThemesThemes
Access-LocationInternet Access-LocationInternet Send-SMS
4. Used APIs 5. Outliers
Weather
+ Travel+ Travel](https://image.slidesharecdn.com/mud-tutorial-150929085346-lva1-app6892/75/Put-Your-Hands-in-the-Mud-What-Technique-Why-and-How-75-2048.jpg)


![Approaches (I)
Sugandha Lohar, Sorawit Amornborvornwong, Andrea Zisman, Jane Cleland-Huang: Improving trace
accuracy through data-driven configuration and composition of tracing features. ESEC/SIGSOFT FSE
2013: 378-388
Improving Trace Accuracy through Data-Driven
ConÆ guration and Composition of Tracing Features
Sugandha Lohar, Sorawit
Amornborvornwong
DePaul University
Chicago, IL, USA
sonul.123@gmail.com,
sorambww@hotmail.com
Andrea Zisman
Department of Computing
The Open University
Milton Keynes, MK7 6AA, UK
andrea.zisman@open.ac.uk
Jane Cleland-Huang
DePaul University
Systems and Requirements
Engineering Center
Chicago, IL, USA
jhuang@cs.depaul.edu
ABSTRACT
Software traceability is a sought-after, yet often elusive qual-
ity in large software-intensive systems primarily because the
cost and effort of tracing can be overwhelming. State-of-the
art solutions address this problem through utilizing trace re-
trieval techniques to automate the process of creating and
maintaining trace links. However, there is no simple one-
size- ts all solution to trace retrieval. As this paper will
show, nding the right combination of tracing techniques
can lead to signi cant improvements in the quality of gener-
ated links. We present a novel approach to trace retrieval in
which the underlying infrastructure is con gured at runtime
to optimize trace quality. We utilize a machine-learning ap-
proach to search for the best con guration given an initial
training set of validated trace links, a set of available tracing
techniques speci ed in a feature model, and an architecture
capable of instantiating all valid con gurations of features.
critical software-intensive systems [4]. It is used to capture
relationships between requirements, design, code, test-cases,
and other software engineering artifacts, and support crit-
ical activities such as impact analysis, compliance veri ca-
tion, test-regression selection, and safety-analysis. As such,
traceability is mandated in safety-critical domains includ-
ing the automotive, aeronautics, and medical device indus-
tries. Unfortunately, tracing costs can grow excessively high
if trace links have to be created and maintained manually
by human users, and as a result, practitioners often fail to
establish adequate traceability in a project [27].
To address these needs, numerous researchers have devel-
oped or adopted algorithms that semi-automate the process
of creating trace links. These algorithms include the Vec-
tor Space Model (VSM) [23], Probabilistic approaches [14],
Latent Semantic Indexing [2, 12], Latent Dirichlet Alloca-
tion (LDA) [13], rule-based approaches that identify rela-
tionships across project artifacts [35], and approaches that
Improving Trace Accuracy through Data-Driven
ConÆ guration and Composition of Tracing Features
Sugandha Lohar, Sorawit
Amornborvornwong
DePaul University
Chicago, IL, USA
sonul.123@gmail.com,
sorambww@hotmail.com
Andrea Zisman
Department of Computing
The Open University
Milton Keynes, MK7 6AA, UK
andrea.zisman@open.ac.uk
Jane Cleland-Huang
DePaul University
Systems and Requirements
Engineering Center
Chicago, IL, USA
jhuang@cs.depaul.edu
ABSTRACT
Software traceability is a sought-after, yet often elusive qual-
ity in large software-intensive systems primarily because the
cost and effort of tracing can be overwhelming. State-of-theffort of tracing can be overwhelming. State-of-theff
art solutions address this problem through utilizing trace re-
critical software-intensive systems [4]. It is used to capture
relationships between requirements, design, code, test-cases,
and other software engineering artifacts, and support crit-
ical activities such as impact analysis, compliance veri ca-
tion, test-regression selection, and safety-analysis. As such,
rint
ical activities such as impact analysis, compliance veri ca-rint
ical activities such as impact analysis, compliance veri ca-
tion, test-regression selection, and safety-analysis. As such,
rint
tion, test-regression selection, and safety-analysis. As such,](https://image.slidesharecdn.com/mud-tutorial-150929085346-lva1-app6892/75/Put-Your-Hands-in-the-Mud-What-Technique-Why-and-How-78-2048.jpg)

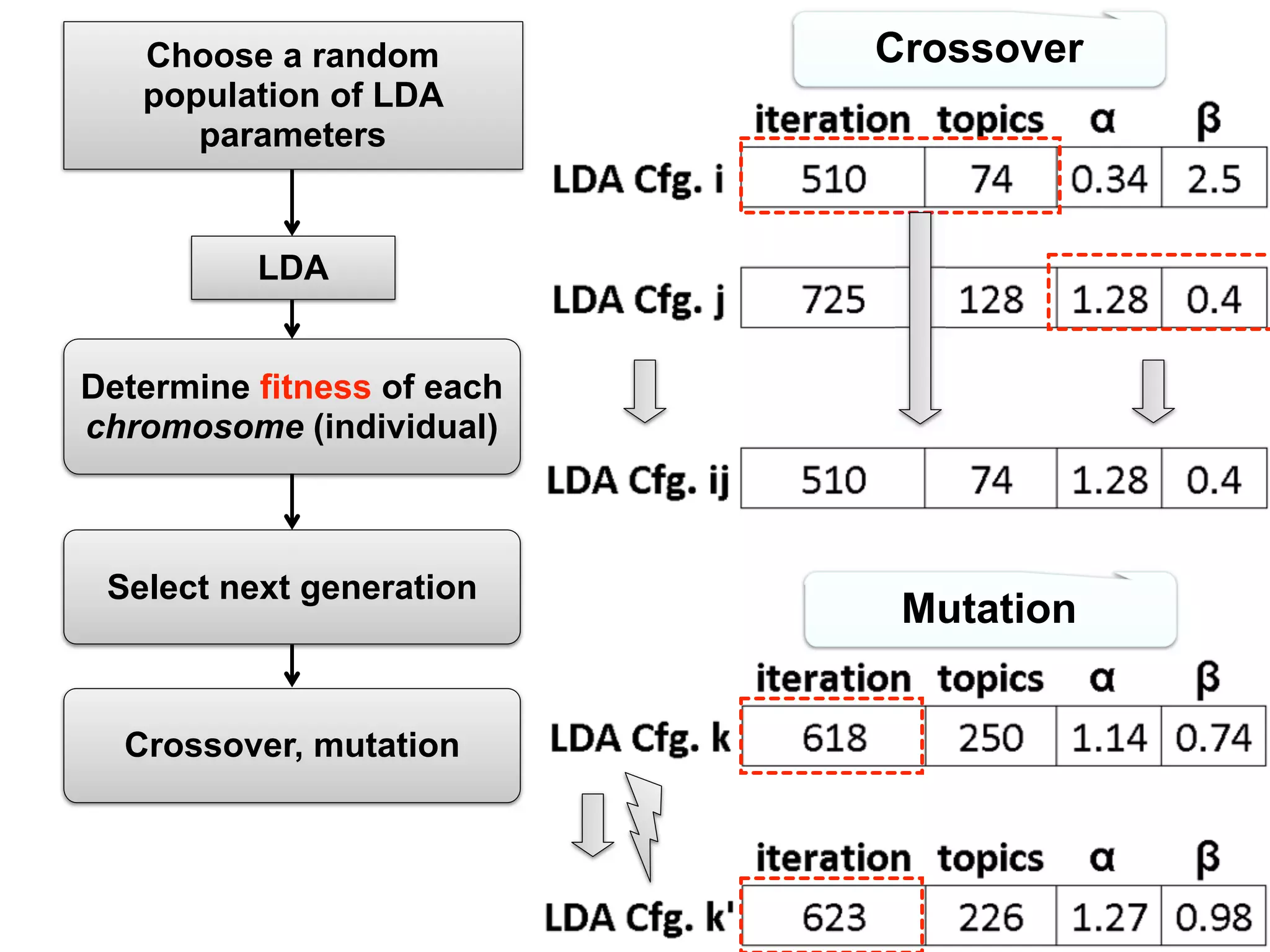
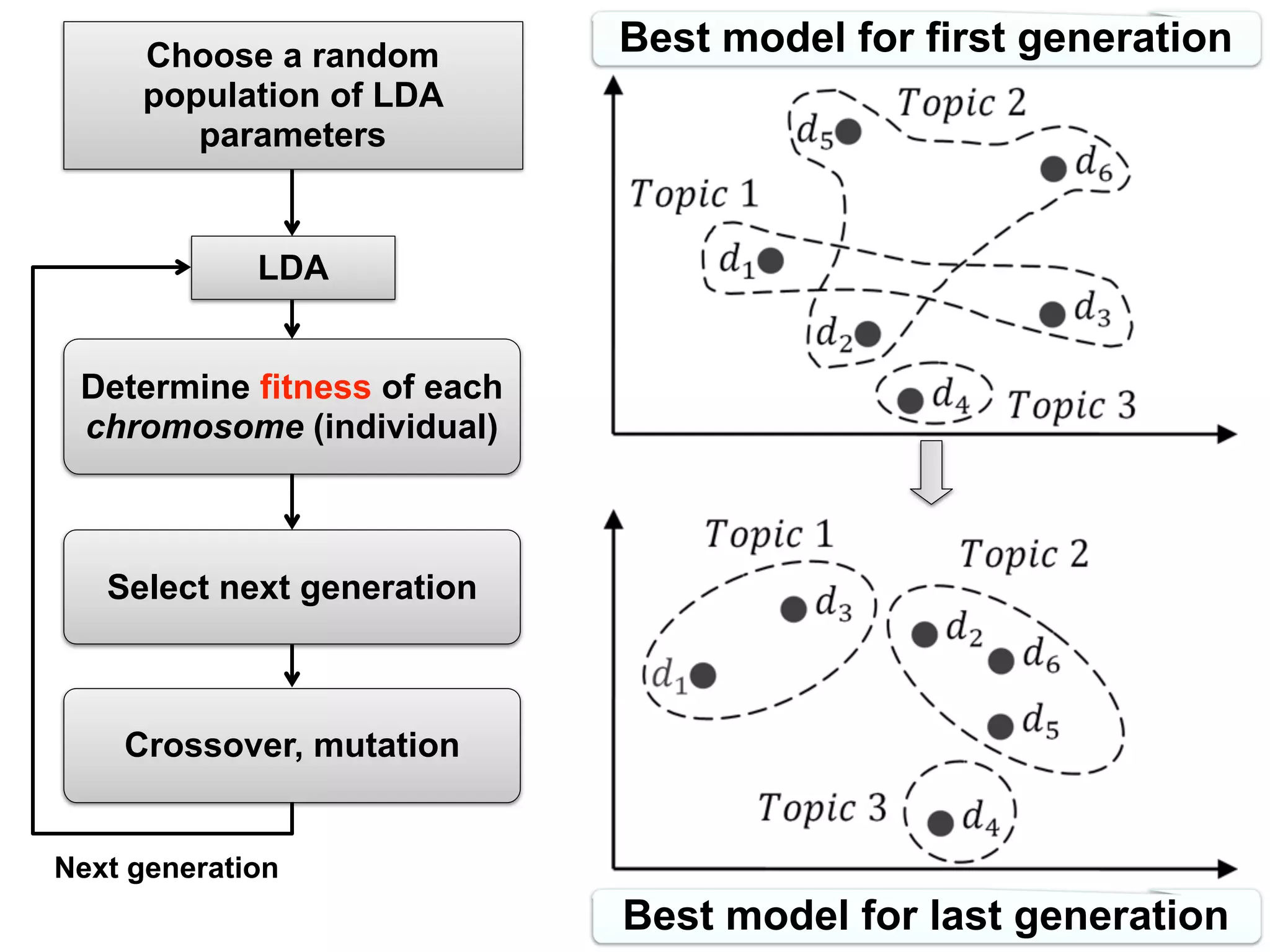
![Approaches (II)
Annibale Panichella, Bogdan Dit, Rocco Oliveto, Massimiliano Di Penta, Denys Poshyvanyk, Andrea
De Lucia: How to effectively use topic models for software engineering tasks? an approach based on
genetic algorithms. ICSE 2013: 522-531
How to Effectively Use Topic Models for
Software Engineering Tasks?
An Approach Based on Genetic Algorithms
Annibale Panichella1, Bogdan Dit2, Rocco Oliveto3,
Massimilano Di Penta4, Denys Poshynanyk2, Andrea De Lucia1
1
University of Salerno, Fisciano (SA), Italy
2
The College of William and Mary, Williamsburg, VA, USA
3
University of Molise, Pesche (IS), Italy
4
University of Sannio, Benevento, Italy
Abstractó Information Retrieval (IR) methods, and in partic-
ular topic models, have recently been used to support essential
software engineering (SE) tasks, by enabling software textual
retrieval and analysis. In all these approaches, topic models have
been used on software artifacts in a similar manner as they
were used on natural language documents (e.g., using the same
settings and parameters) because the underlying assumption was
that source code and natural language documents are similar.
However, applying topic models on software data using the same
settings as for natural language text did not always produce the
expected results.
Recent research investigated this assumption and showed that
source code is much more repetitive and predictable as compared
to the natural language text. Our paper builds on this new
fundamental nding and proposes a novel solution to adapt,
con gure and effectively use a topic modeling technique, namely
Latent Dirichlet Allocation (LDA), to achieve better (acceptable)
performance across various SE tasks. Our paper introduces a
novel solution called LDA-GA, which uses Genetic Algorithms
(GA) to determine a near-optimal con guration for LDA in
the context of three different SE tasks: (1) traceability link
recovery, (2) feature location, and (3) software artifact labeling.
The results of our empirical studies demonstrate that LDA-GA
is able to identify robust LDA con gurations, which lead to a
higher accuracy on all the datasets for these SE tasks as compared
proposed to support software engineering tasks: feature lo-
cation [4], change impact analysis [5], bug localization [6],
clone detection [7], traceability link recovery [8], [9], expert
developer recommendation [10], code measurement [11], [12],
artifact summarization [13], and many others [14], [15], [16].
In all these approaches, LDA and LSI have been used on
software artifacts in a similar manner as they were used on
natural language documents (i.e., using the same settings,
con gurations and parameters) because the underlying as-
sumption was that source code (or other software artifacts)
and natural language documents exhibit similar properties.
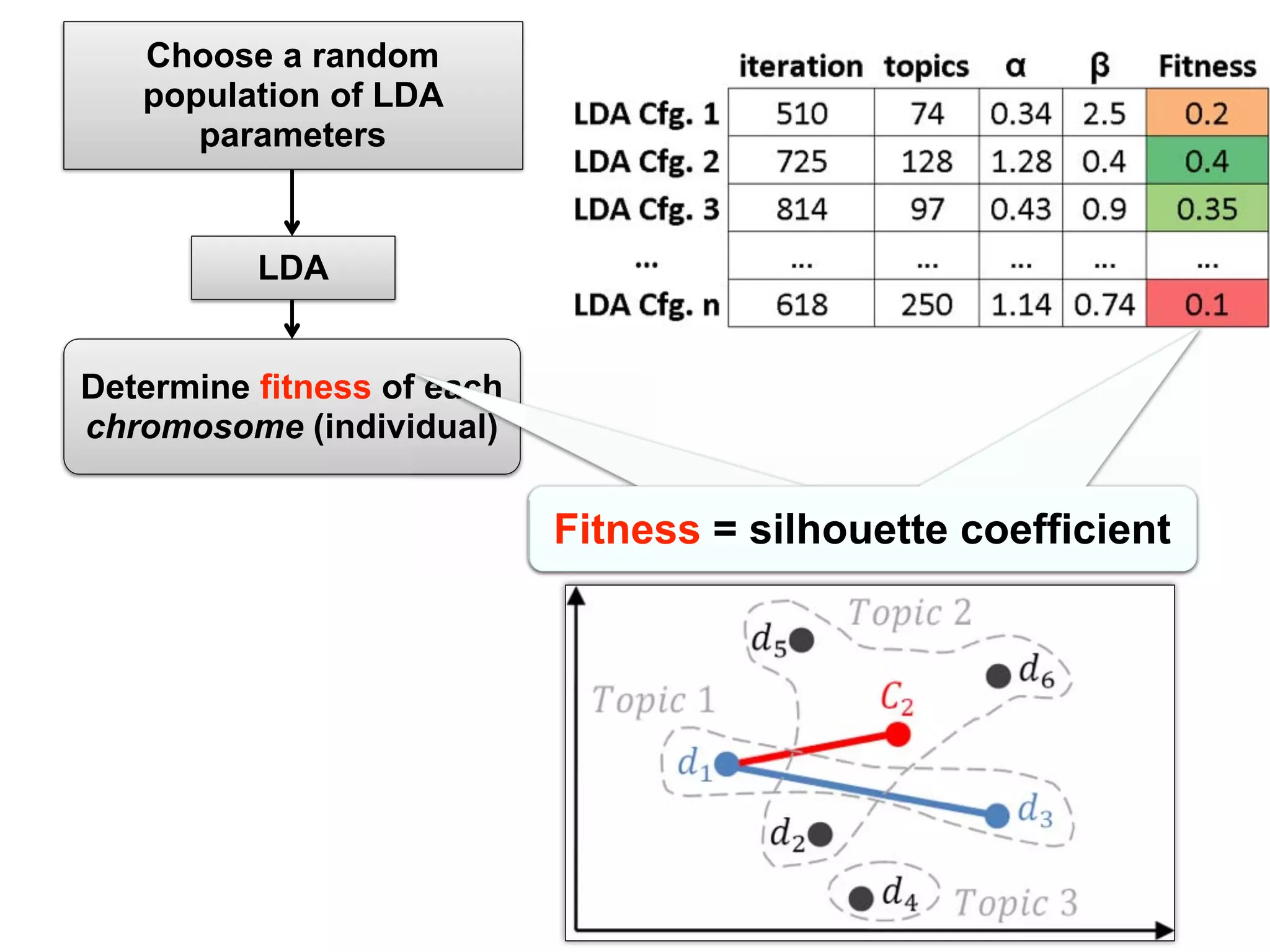
More speci cally, applying LDA requires setting the number
of topics and other parameters speci c to the particular LDA
implementation. For example, the fast collapsed Gibbs sam-
pling generative model for LDA requires setting the number
of iterations n and the Dirichlet distribution parameters α
and β [17]. Even though LDA was successfully used in the
IR and natural language analysis community, applying it on
software data, using the same parameter values used for natural
language text, did not always produce the expected results
[18]. As in the case of machine learning and optimization
How to Effectively Use Topic Models for
Software Engineering Tasks?
An Approach Based on Genetic Algorithms
Annibale Panichella1, Bogdan Dit2, Rocco Oliveto3,
Massimilano Di Penta4, Denys Poshynanyk2, Andrea De Lucia1
1
University of Salerno, Fisciano (SA), Italy
2
The College of William and Mary, Williamsburg, VA, USA
3
University of Molise, Pesche (IS), Italy
4
University of Sannio, Benevento, Italy
Abstractó Information Retrieval (IR) methods, and in partic-
ular topic models, have recently been used to support essential
software engineering (SE) tasks, by enabling software textual
retrieval and analysis. In all these approaches, topic models have
been used on software artifacts in a similar manner as they
were used on natural language documents (e.g., using the same
settings and parameters) because the underlying assumption was
that source code and natural language documents are similar.that source code and natural language documents are similar.that source code and natural language documents are similar
However, applying topic models on software data using the same
settings as for natural language text did not always produce the
proposed to support software engineering tasks: feature lo-
cation [4], change impact analysis [5], bug localization [6],
clone detection [7], traceability link recovery [8], [9], expert
developer recommendation [10], code measurement [11], [12],
artifact summarization [13], and many others [14], [15], [16].
In all these approaches, LDA and LSI have been used on
software artifacts in a similar manner as they were used on
natural language documents (i.e., using the same settings,
con gurations and parameters) because the underlying as-](https://image.slidesharecdn.com/mud-tutorial-150929085346-lva1-app6892/75/Put-Your-Hands-in-the-Mud-What-Technique-Why-and-How-80-2048.jpg)


















![Applications
Rahul Pandita, Xusheng Xiao, Hao Zhong, Tao Xie, Stephen Oney, Amit M. Paradkar:
Inferring method specifications from natural language API descriptions. ICSE 2012: 815-825
Inferring Method Specifications from Natural Language API Descriptions
Rahul Pandita⇤, Xusheng Xiao⇤, Hao Zhong†, Tao Xie⇤, Stephen Oney‡, and Amit Paradkar§
⇤Department of Computer Science, North Carolina State University, Raleigh, USA
†Laboratory for Internet Software Technologies, Institute of Software, Chinese Academy of Sciences, Beijing, China
‡Human-Computer Interaction Institute, Carnegie Mellon University, Pittsburgh, USA
§I.B.M. T. J. Watson Research Center, Hawthorne, NY, USA
{rpandit, xxiao2, txie}@ncsu.edu, zhonghao@itechs.iscas.ac.cn, soney@cs.cmu.edu, paradkar@us.ibm.com
Abstract—Application Programming Interface (API) docu-
ments are a typical way of describing legal usage of reusable
software libraries, thus facilitating software reuse. However,
even with such documents, developers often overlook some
documents and build software systems that are inconsistent
with the legal usage of those libraries. Existing software
verification tools require formal specifications (such as code
contracts), and therefore cannot directly verify the legal usage
described in natural language text in API documents against
code using that library. However, in practice, most libraries
do not come with formal specifications, thus hindering tool-
based verification. To address this issue, we propose a novel
approach to infer formal specifications from natural language
text of API documents. Our evaluation results show that our
approach achieves an average of 92% precision and 93%
recall in identifying sentences that describe code contracts from
more than 2500 sentences of API documents. Furthermore, our
results show that our approach has an average 83% accuracy
in inferring specifications from over 1600 sentences describing
code contracts.
I. INTRODUCTION
Programming Interface (API) documents. Typically, such
documents are provided to client-code developers through
online access, or are shipped with the API code. For exam-
ple, J2EE’s API documentation3
is one of the most popular
API documents.
Even with such documents, client-code developers often
overlook some API documents and use methods in API
libraries incorrectly [22]. Since these documents are written
in natural language, existing tools cannot verify legal usage
described in a library’s API documents against the client
code of that library. One possible solution is to manually
write code contracts based on the specifications described
in API documents. However, due to a large number of
sentences in API documents, manually hunting for contract
sentences and writing code contracts for the API library
is prohibitively time consuming and labor intensive. For
instance, the File class of the C# .NET Framework has
around 800 sentences. Moreover, not all of these sentences
Inferring Method Specifications from Natural Language API Descriptions
Rahul Pandita⇤, Xusheng Xiao⇤, Hao Zhong†, Tao Xie⇤, Stephen Oney‡, and Amit Paradkar§
⇤Department of Computer Science, North Carolina State University, Raleigh, USA
†Laboratory for Internet Software Technologies, Institute of Software, Chinese Academy of Sciences, Beijing, China
‡
Laboratory for Internet Software Technologies, Institute of Software, Chinese Academy of Sciences, Beijing, China
‡
Laboratory for Internet Software Technologies, Institute of Software, Chinese Academy of Sciences, Beijing, China
Human-Computer Interaction Institute, Carnegie Mellon University, Pittsburgh, USA
§
Human-Computer Interaction Institute, Carnegie Mellon University, Pittsburgh, USA
§
Human-Computer Interaction Institute, Carnegie Mellon University, Pittsburgh, USA
I.B.M. T. J. Watson Research Center, Hawthorne, NY, USA
{rpandit, xxiao2, txie}@ncsu.edu, zhonghao@itechs.iscas.ac.cn, soney@cs.cmu.edu, paradkar@us.ibm.com
Abstract—Application Programming Interface (API) docu-Abstract—Application Programming Interface (API) docu-Abstract
ments are a typical way of describing legal usage of reusable
software libraries, thus facilitating software reuse. However,
even with such documents, developers often overlook some
documents and build software systems that are inconsistent
with the legal usage of those libraries. Existing software
verification tools require formal specifications (such as code
contracts), and therefore cannot directly verify the legal usage
described in natural language text in API documents against
code using that library. However, in practice, most libraries
do not come with formal specifications, thus hindering tool-
based verification. To address this issue, we propose a novel
Programming Interface (API) documents. Typically, such
documents are provided to client-code developers through
online access, or are shipped with the API code. For exam-
ple, J2EE’s API documentation3
is one of the most popular
API documents.
Even with such documents, client-code developers often
overlook some API documents and use methods in API
libraries incorrectly [22]. Since these documents are written
in natural language, existing tools cannot verify legal usage
described in a library’s API documents against the client](https://image.slidesharecdn.com/mud-tutorial-150929085346-lva1-app6892/75/Put-Your-Hands-in-the-Mud-What-Technique-Why-and-How-102-2048.jpg)
![Applications
How Can I Improve My App? Classifying User
Reviews for Software Maintenance and Evolution
S. Panichella⇤, A. Di Sorbo†, E. Guzman‡, C. A.Visaggio†, G. Canfora† and H. C. Gall⇤
⇤University of Zurich, Switzerland
†University of Sannio, Benevento, Italy
‡Technische Universit¨at M¨unchen, Garching, Germany
panichella@ifi.uzh.ch, disorbo@unisannio.it, emitza.guzman@mytum.de, {visaggio,canfora}@unisannio.it, gall@ifi.uzh.ch
Abstract—App Stores, such as Google Play or the Apple Store,
allow users to provide feedback on apps by posting review
comments and giving star ratings. These platforms constitute a
useful electronic mean in which application developers and users
can productively exchange information about apps. Previous
research showed that users feedback contains usage scenarios,
bug reports and feature requests, that can help app developers to
accomplish software maintenance and evolution tasks. However,
in the case of the most popular apps, the large amount of received
feedback, its unstructured nature and varying quality can make
the identification of useful user feedback a very challenging task.
In this paper we present a taxonomy to classify app reviews
into categories relevant to software maintenance and evolution,
as well as an approach that merges three techniques: (1)
Natural Language Processing, (2) Text Analysis and (3) Sentiment
Analysis to automatically classify app reviews into the proposed
categories. We show that the combined use of these techniques
allows to achieve better results (a precision of 75% and a recall
of 74%) than results obtained using each technique individually
(precision of 70% and a recall of 67%).
Index Terms—User Reviews, Mobile Applications, Natural
Language Processing, Sentiment Analysis, Text classification
form of unstructured text that is difficult to parse and analyze.
Thus, developers and analysts have to read a large amount
of textual data to become aware of the comments and needs
of their users [10]. In addition, the quality of reviews varies
greatly, from useful reviews providing ideas for improvement
or describing specific issues to generic praises and complaints
(e.g. “You have to be stupid to program this app”, “I love
it!”, “this app is useless”).
To handle this problem Chen et al. [10] proposed AR-
Miner, an approach to help app developers discover the most
informative user reviews. Specifically, the authors use: (i) text
analysis and machine learning to filter out non-informative
reviews and (ii) topic analysis to recognize topics treated
in the reviews classified as informative. In this paper, we
argue that text content represents just one of the possible
dimensions that can be explored to detect informative reviews
from a software maintenance and evolution perspective. In
particular, topic analysis techniques are useful to discover
How Can I Improve My App? Classifying User
Reviews for Software Maintenance and Evolution
S. Panichella⇤, A. Di Sorbo†, E. Guzman‡, C. A.Visaggio†, G. Canfora† and H. C. Gall⇤
⇤University of Zurich, Switzerland
†University of Sannio, Benevento, Italy
‡Technische Universitat M¨at M¨ unchen, Garching, Germany¨unchen, Garching, Germany¨
panichella@ifi.uzh.ch, disorbo@unisannio.it, emitza.guzman@mytum.de, {visaggio,canfora}@unisannio.it, gall@ifi.uzh.ch
Abstract—App Stores, such as Google Play or the Apple Store,Abstract—App Stores, such as Google Play or the Apple Store,Abstract
allow users to provide feedback on apps by posting review
comments and giving star ratings. These platforms constitute a
useful electronic mean in which application developers and users
can productively exchange information about apps. Previous
research showed that users feedback contains usage scenarios,
bug reports and feature requests, that can help app developers to
accomplish software maintenance and evolution tasks. However,
in the case of the most popular apps, the large amount of received
feedback, its unstructured nature and varying quality can make
the identification of useful user feedback a very challenging task.
In this paper we present a taxonomy to classify app reviews
into categories relevant to software maintenance and evolution,
as well as an approach that merges three techniques: (1)
Natural Language Processing, (2) Text Analysis and (3) Sentiment
Analysis to automatically classify app reviews into the proposed
categories. We show that the combined use of these techniques
allows to achieve better results (a precision of 75% and a recall
of 74%) than results obtained using each technique individually
(precision of 70% and a recall of 67%).
form of unstructured text that is difficult to parse and analyze.
Thus, developers and analysts have to read a large amount
of textual data to become aware of the comments and needs
of their users [10]. In addition, the quality of reviews varies
greatly, from useful reviews providing ideas for improvement
or describing specific issues to generic praises and complaints
(e.g. “You have to be stupid to program this app”, “I love
it!”, “this app is useless”).
To handle this problem Chen et al. [10] proposed AR-
Miner, an approach to help app developers discover the most
informative user reviews. Specifically, the authors use: (i) text
analysis and machine learning to filter out non-informative
reviews and (ii) topic analysis to recognize topics treated
in the reviews classified as informative. In this paper, we
argue that text content represents just one of the possible
dimensions that can be explored to detect informative reviews
from a software maintenance and evolution perspective. In
@ICSME 2015 - Thurdsay, 13.50 - Mobile applications](https://image.slidesharecdn.com/mud-tutorial-150929085346-lva1-app6892/75/Put-Your-Hands-in-the-Mud-What-Technique-Why-and-How-103-2048.jpg)











The document discusses techniques for analyzing unstructured text data from software repositories. It describes using textual analysis on code identifiers, comments, commit messages, issue trackers, emails, and forums to perform tasks like traceability link recovery, feature location, clone detection, and bug prediction. Different techniques are discussed, including pattern matching, island parsers, information retrieval methods, and natural language parsing. Choosing the right technique depends on the type of unstructured data and needs of the analysis.























































































