









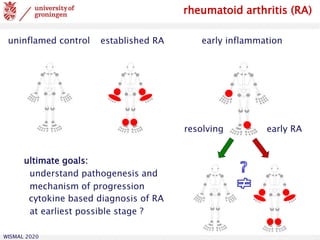
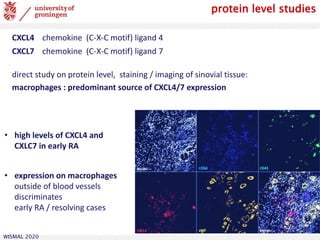
![WISMAL 2020
Neural Gas (NG)
introduce rank-based neighborhood cooperativeness:
upon presentation of xμ :
• determine the rank of the prototypes
• update all prototypes:
with neighborhood function
and rank-based range λ
• potential annealing of λ from large to smaller values
[Martinetz, Berkovich, Schulten, IEEE Trans. Neural Netw. 1993]
many prototypes (gas) to represent the density of observed data](https://image.slidesharecdn.com/biehl-wismal-2020-200705102248/85/January-2020-Prototype-based-systems-in-machine-learning-14-320.jpg)

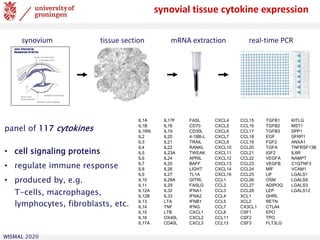
![WISMAL 2020 17
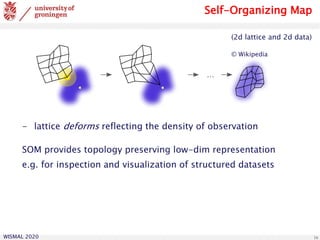
Self-Organizing Map
illustrative example: Iris flower data set [Fisher, 1936]:
4 num. features representing Iris flowers from 3 different species
SOM (4x6 prototypes in a 2-dim. grid)
training on 150 samples (without class label information)
component planes: 4 arrays representing the prototype values](https://image.slidesharecdn.com/biehl-wismal-2020-200705102248/85/January-2020-Prototype-based-systems-in-machine-learning-17-320.jpg)
![WISMAL 2020 19
Remarks:
- presentation of approaches not in historical order
- many extensions of the basic concept, e.g.
cost-function based SOM [Heskes, 1999]
Generative Topographic Map (GTM), statistical modelling
formulation of the mapping to low-dim. lattice
[Bishop, Svensen, Williams, 1998]
SOM and NG for specific types of data
- time series
- “non-vectorial” relational data
- graphs and trees
Vector Quantization/SOM](https://image.slidesharecdn.com/biehl-wismal-2020-200705102248/85/January-2020-Prototype-based-systems-in-machine-learning-19-320.jpg)



![WISMAL 2020
prototype based classification
a prototype based classifier [Kohonen 1990, 1997]
- represent the data by one or
several prototypes per class
- classify a query according to the
label of the nearest prototype
(or alternative schemes)
- local decision boundaries according
to (e.g.) Euclidean distances
- piece-wise linear class borders
parameterized by prototypes
feature space
?
+ less sensitive to outliers, lower storage needs, little computational
effort in the working phase
- training phase required in order to place prototypes,
model selection problem: number of prototypes per class, etc.](https://image.slidesharecdn.com/biehl-wismal-2020-200705102248/85/January-2020-Prototype-based-systems-in-machine-learning-23-320.jpg)

![WISMAL 2020
∙ identification of prototype vectors from labeled example data
∙ distance based classification (e.g. Euclidean)
Learning Vector Quantization
N-dimensional data, feature vectors
• initialize prototype vectors
for different classes
heuristic scheme: LVQ1 [Kohonen, 1990, 1997]
• identify the winner
(closest prototype)
• present a single example
• move the winner
- closer towards the data (same class)
- away from the data (different class)](https://image.slidesharecdn.com/biehl-wismal-2020-200705102248/85/January-2020-Prototype-based-systems-in-machine-learning-25-320.jpg)
![WISMAL 2020
∙ identification of prototype vectors from labeled example data
∙ distance based classification (e.g. Euclidean)
Learning Vector Quantization
N-dimensional data, feature vectors
∙ tesselation of feature space
[piece-wise linear]
∙ distance-based classification
[here: Euclidean distances]
∙ generalization ability
correct classification of new data
∙ aim: discrimination of classes
( ≠ vector quantization
or density estimation )
](https://image.slidesharecdn.com/biehl-wismal-2020-200705102248/85/January-2020-Prototype-based-systems-in-machine-learning-26-320.jpg)
![WISMAL 2020
sequential presentation of labelled examples
… the winner takes it all:
learning rate
many heuristic variants/modifications: [Kohonen, 1990,1997]
- learning rate schedules ηw (t)
- update more than one prototype per step
iterative training procedure:
randomized initial , e.g. close to the class-conditional means
LVQ1
LVQ1 update step:](https://image.slidesharecdn.com/biehl-wismal-2020-200705102248/85/January-2020-Prototype-based-systems-in-machine-learning-27-320.jpg)

![WISMAL 2020
Generalized LVQ
one example of cost function based training: GLVQ [Sato & Yamada, 1995]
sigmoidal (linear for small arguments), e.g.
E approximates number of misclassifications
linear
E favors large margin separation of classes, e.g.
two winning prototypes:
minimize](https://image.slidesharecdn.com/biehl-wismal-2020-200705102248/85/January-2020-Prototype-based-systems-in-machine-learning-29-320.jpg)





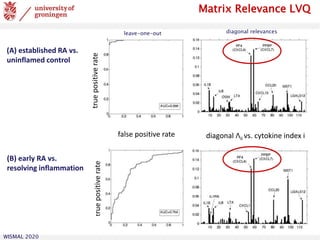
![WISMAL 2020
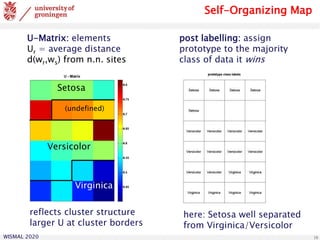
Relevance Matrix LVQ
generalized quadratic distance in LVQ:
variants:
one global, several local, class-wise relevance matrices
→ piecewise quadratic decision boundaries
rectangular discriminative low-dim. representation
e.g. for visualization [Bunte et al., 2012]
possible constraints: rank-control, sparsity, …
normalization:
diagonal matrices: single feature weights [Bojer et al., 2001]
[Hammer et al., 2002]
[Schneider et al., 2009]](https://image.slidesharecdn.com/biehl-wismal-2020-200705102248/85/January-2020-Prototype-based-systems-in-machine-learning-35-320.jpg)


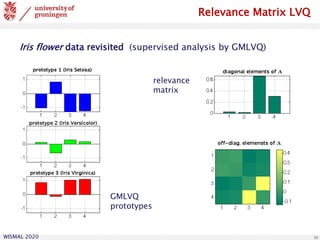
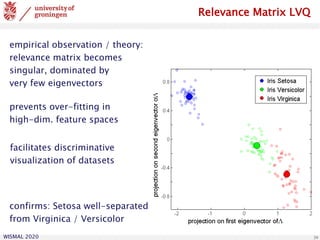
![WISMAL 2020
projection on first eigenvector
projectiononsecondeigenvector a multi-class example
classification of coffee samples
based on hyperspectral data
(256-dim. feature vectors)
[U. Seiffert et al., IFF Magdeburg]
prototypes](https://image.slidesharecdn.com/biehl-wismal-2020-200705102248/85/January-2020-Prototype-based-systems-in-machine-learning-40-320.jpg)

![WISMAL 2020
related schemes
Relevance LVQ variants
local, rectangular, structured, restricted... relevance matrices
for visualization, functional data, texture recognition, etc.
relevance learning in Robust Soft LVQ, Supervised NG, etc.
combination of distances for mixed data ...
Relevance Learning related schemes in supervised learning ...
RBF Networks [Backhaus et al., 2012]
Neighborhood Component Analysis [Goldberger et al., 2005]
Large Margin Nearest Neighbor [Weinberger et al., 2006, 2010]
and many more!
Linear Discriminant Analysis (LDA)
~ one prototype per class + global matrix,
different objective function!](https://image.slidesharecdn.com/biehl-wismal-2020-200705102248/85/January-2020-Prototype-based-systems-in-machine-learning-42-320.jpg)



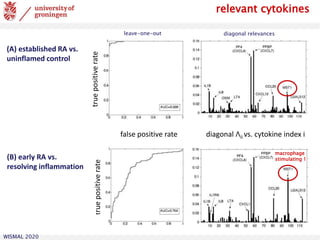



The document reviews prototype-based models in machine learning, focusing on both supervised and unsupervised learning techniques such as vector quantization and self-organizing maps. It discusses various methodologies, their applications, and challenges related to performance, including classification, regression, and dimensionality reduction. An application example highlights the use of these techniques for early diagnosis of rheumatoid arthritis based on cytokine expression analysis.















































































