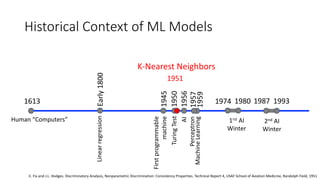
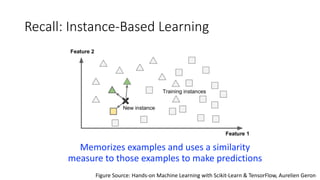
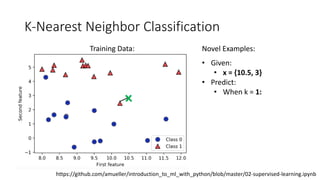
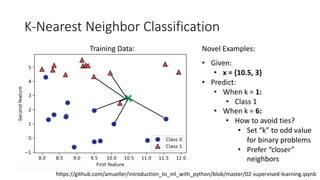
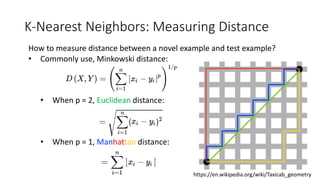
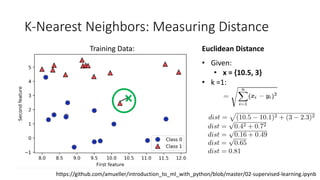
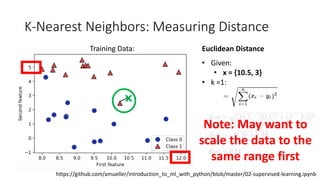
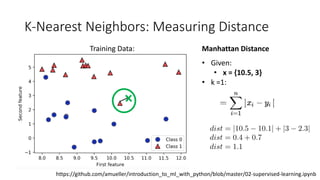
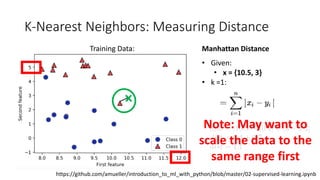
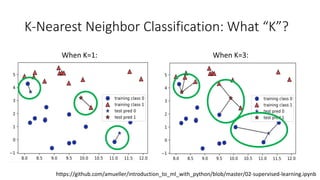
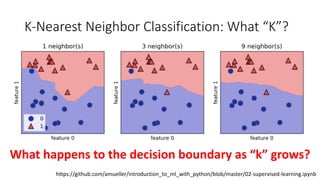
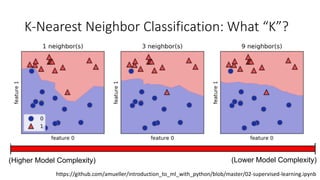
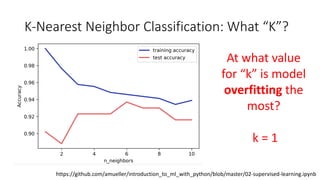
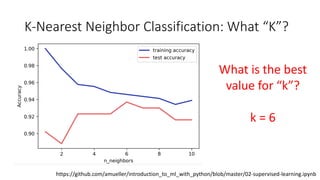
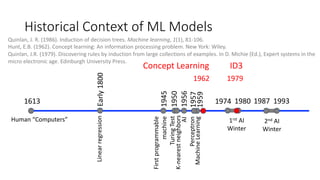
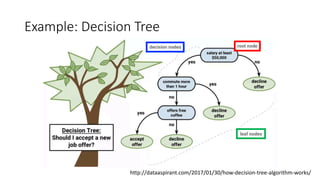
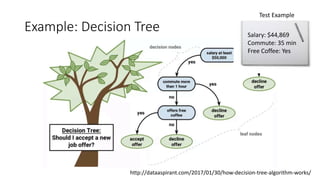
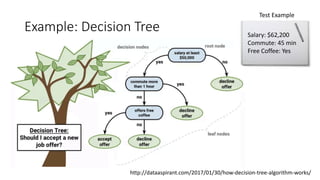
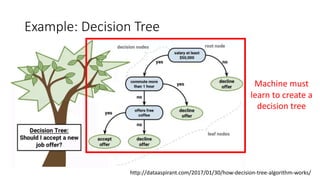
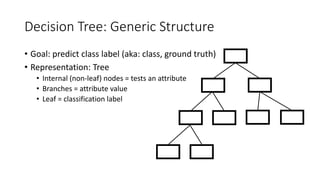
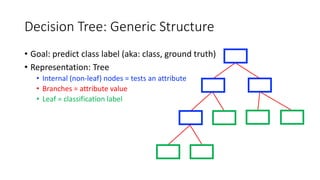
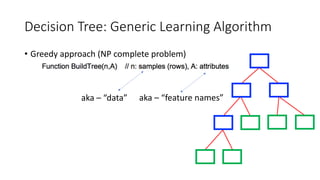
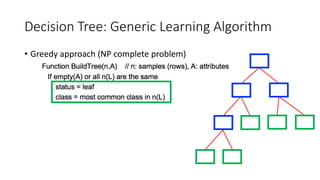
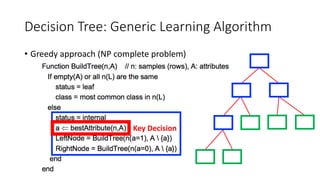
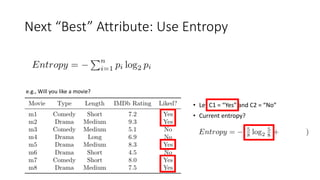
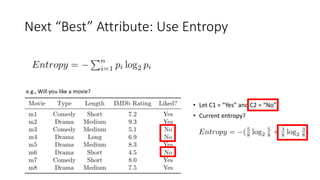
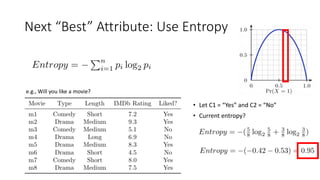
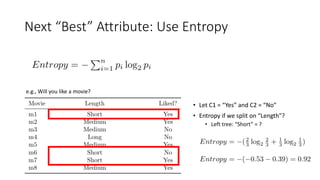
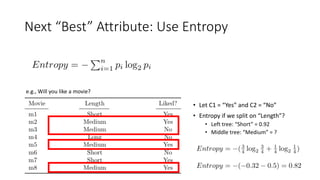
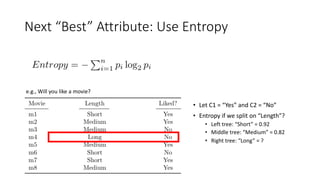
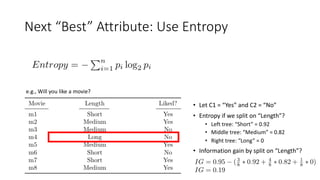
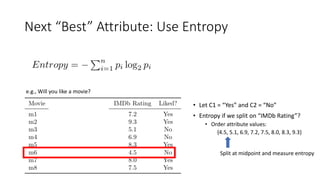
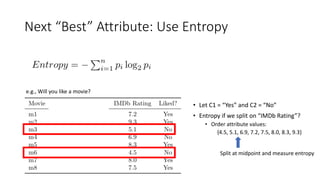
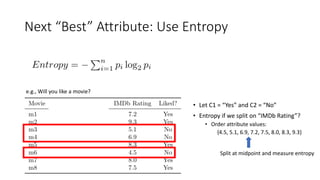
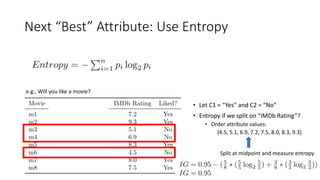
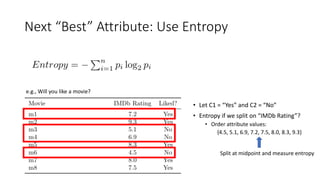
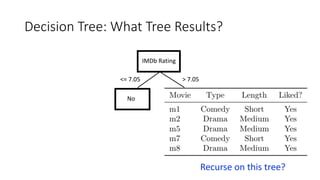
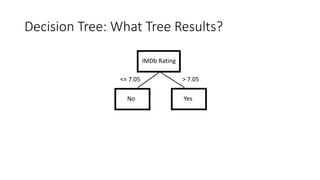
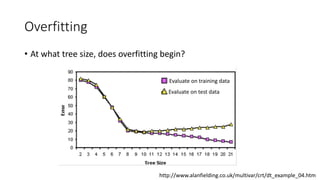
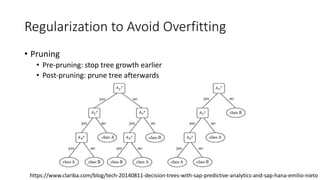
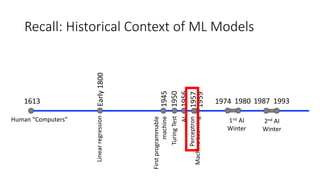
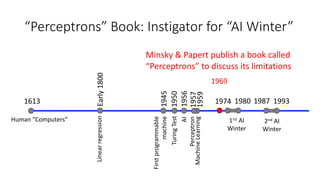
The document covers topics in machine learning, specifically focusing on multiclass classification, nearest neighbor classification, and decision tree classification. It discusses the evolution and historical context of machine learning models, including challenges like the XOR problem and the need for non-linear models. The document also elaborates on evaluation methods, training data organization, and the strengths and weaknesses of k-nearest neighbors (KNN) methods.



















![Recall: Vision for Perceptron
Frank Rosenblatt
(Psychologist)
“[The perceptron is] the embryo of an
electronic computer that [the Navy] expects
will be able to walk, talk, see, write,
reproduce itself and be conscious of its
existence…. [It] is expected to be finished in
about a year at a cost of $100,000.”
1958 New York Times article: https://www.nytimes.com/1958/07/08/archives/new-
navy-device-learns-by-doing-psychologist-shows-embryo-of.html
https://en.wikipedia.org/wiki/Frank_Rosenblatt](https://image.slidesharecdn.com/04-nearestneighboranddecisiontree-240507205857-6b635a46/85/Nearest-Neighbor-And-Decision-Tree-NN-DT-21-320.jpg)







![Perceptron Limitation: XOR Problem
Frank Rosenblatt
(Psychologist)
“[The perceptron is] the embryo of an
electronic computer that [the Navy] expects
will be able to walk, talk, see, write,
reproduce itself and be conscious of its
existence…. [It] is expected to be finished in
about a year at a cost of $100,000.”
1958 New York Times article: https://www.nytimes.com/1958/07/08/archives/new-
navy-device-learns-by-doing-psychologist-shows-embryo-of.html
How can a machine be “conscious”
when it can’t solve the XOR problem?](https://image.slidesharecdn.com/04-nearestneighboranddecisiontree-240507205857-6b635a46/85/Nearest-Neighbor-And-Decision-Tree-NN-DT-30-320.jpg)