Download as PDF, PPTX







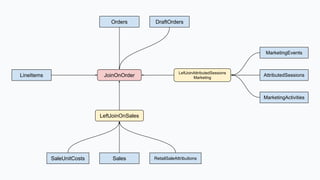



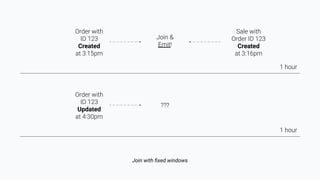
![[Arbitrarily] Late-Arriving Updates
● Order edits
● Order imports
● Order deletions
● Refunds
● Session attribution](https://image.slidesharecdn.com/storingstateforeverwhyitcanbegoodforyouranalytics-211031032330/85/Storing-State-Forever-Why-It-Can-Be-Good-For-Your-Analytics-14-320.jpg)

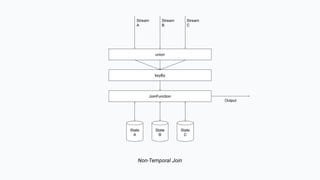
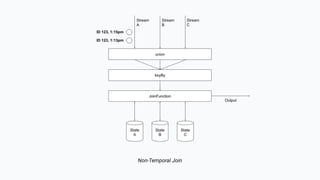

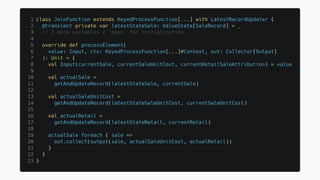

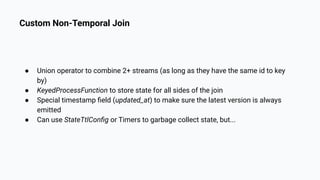



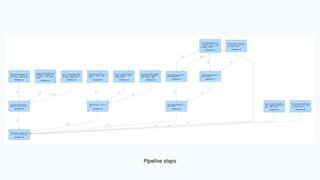
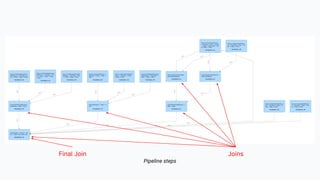
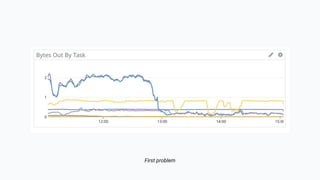
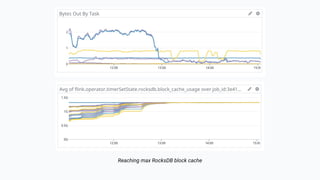

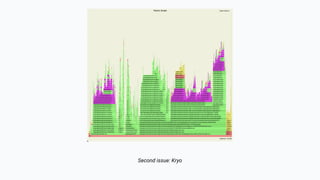








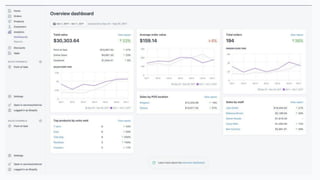
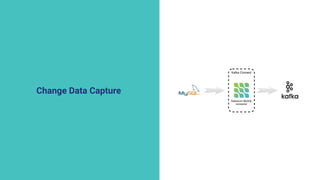
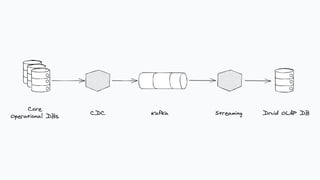
The document discusses the implementation of a complex analytics model at Shopify that processes large amounts of sales data using a streaming sales model with low latency and the ability to handle late-arriving updates. It details the architecture, challenges, and performance outcomes of maintaining extensive state in a Flink pipeline without garbage collection, achieving accurate backfill and recovery results. Key next steps include optimizing state management and introducing time-to-live (TTL) for certain states to improve efficiency.




















































































