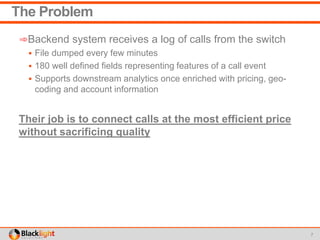
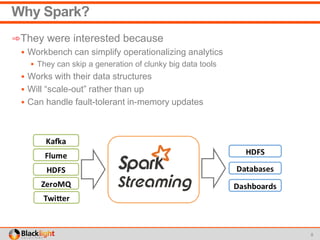
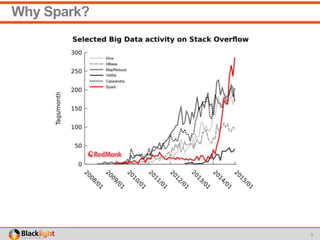
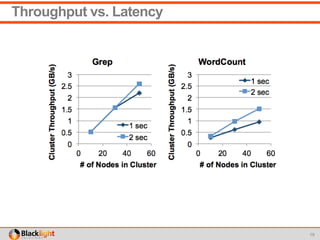
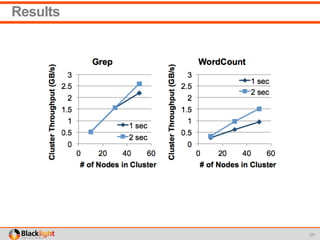
This document summarizes a proof-of-concept project using Spark Streaming to enable new analytics for a telecommunications company processing 90 million calls per day. The company wanted to test Spark Streaming's ability to scale analytics and prove it could enable techniques like incident detection. The project showed Spark Streaming could handle 5 minutes of call data sub-second, successfully detected incidents using a univariate technique, and proved relatively easy deployment to AWS. While the company's team remained skeptical of big data technologies, the project proved Spark Streaming's capabilities.






![Anatomy of a Spark Streaming Program
val sparkConf = new SparkConf().setAppName(“QueueStream”)
val ssc = new StreamingContext(sparkConf, Seconds(1))
val rddQueue = new SynchronizedQueue[RDD[Int]]()
val inputStream = ssc.queueStream(rddQueue)
val mappedStream = inputStream.map(x => (x % 10, 1))
val reducedStream = mappedStream.reduceByKey(_ + _)
reducedStream.print()
ssc.start()
for(i 1 to 30) {
rddQueue += ssc.sparkContext.makeRDD(1 to 1000, 10)
Thread.sleep(1000)
}
ssc.stop()
20
Utilities also available for
Twitter
Kafka
Flume
Filestream](https://image.slidesharecdn.com/sparktelcousecase-150629192740-lva1-app6891/85/Spark-Streaming-Early-Warning-Use-Case-20-320.jpg)
![Streaming Call Analysis with Windows
val path = "/Users/chance/Documents/cdrdrop”
val conf = new SparkConf()
.setMaster("local[12]")
.setAppName("CDRIncidentDetection")
.set("spark.executor.memory","8g")
val ssc = new StreamingContext(conf,Seconds(iteration))
val callStream = ssc.textFileStream(path)
val cdr = callStream.window(Seconds(window),Seconds(slide)).map(_.split(";"))
val cdrArr = cdr.filter(c => c.length>136)
.map(c => extractCallDetailRecord(c))
val result = detectIncidents(cdrArr)
result.foreach(rdd => rdd.take(10)
.foreach{case(x,(d,high,low,res)) =>
println(x + "," + high + "," + d + "," + low + "," + res) })
ssc.start()
ssc.awaitTermination()
22](https://image.slidesharecdn.com/sparktelcousecase-150629192740-lva1-app6891/85/Spark-Streaming-Early-Warning-Use-Case-22-320.jpg)
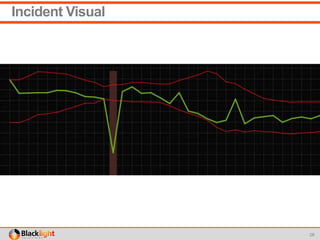
![Can we enable new analytics?
23
➾Incident detection
Chose a univariate technique[1] to detect behavior out of profile
from recent events
Technique identifies
out of profile events
dramatic shifts in the profile
Easy to understand
Recent
Window](https://image.slidesharecdn.com/sparktelcousecase-150629192740-lva1-app6891/85/Spark-Streaming-Early-Warning-Use-Case-23-320.jpg)


![References
➾[1] Zaharia et al : Discretized Streams
➾[2] Zaharia et al: Discretized Streams: Fault-Tolerant
Streaming
➾[3] Das : Spark Streaming – Real-time Big-Data Processing
➾[4] Spark Streaming Programming Guide
➾[5] Running Spark on EC2
➾[6] Spark on EMR
➾[7] Ahelegby: Time Series Outliers
29](https://image.slidesharecdn.com/sparktelcousecase-150629192740-lva1-app6891/85/Spark-Streaming-Early-Warning-Use-Case-29-320.jpg)
















































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Mikhail Rozhkov - AI Product Canvas: From Business Goals to T...](https://cdn.slidesharecdn.com/ss_thumbnails/d53doddtpgfqivmzqel6-mikhail-rozhkov-ai-product-canvas-v1-260121115910-9dd517a7-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)


