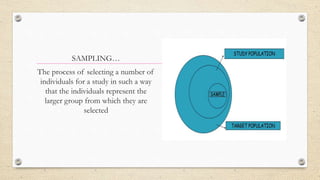
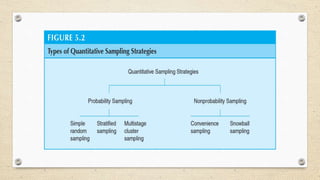
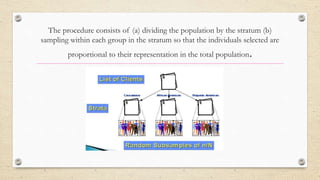
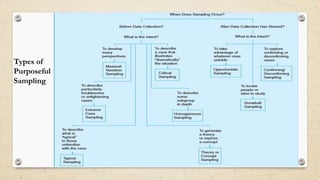
The document provides an overview of sampling methods in quantitative and qualitative research, distinguishing between probabilistic and non-probabilistic sampling techniques. It details various sampling strategies such as random, systematic, stratified, cluster, convenience, and snowball sampling, highlighting their advantages and disadvantages. Additionally, it explains purposeful sampling methods for qualitative research that focus on obtaining rich, detailed insights from representative individuals.