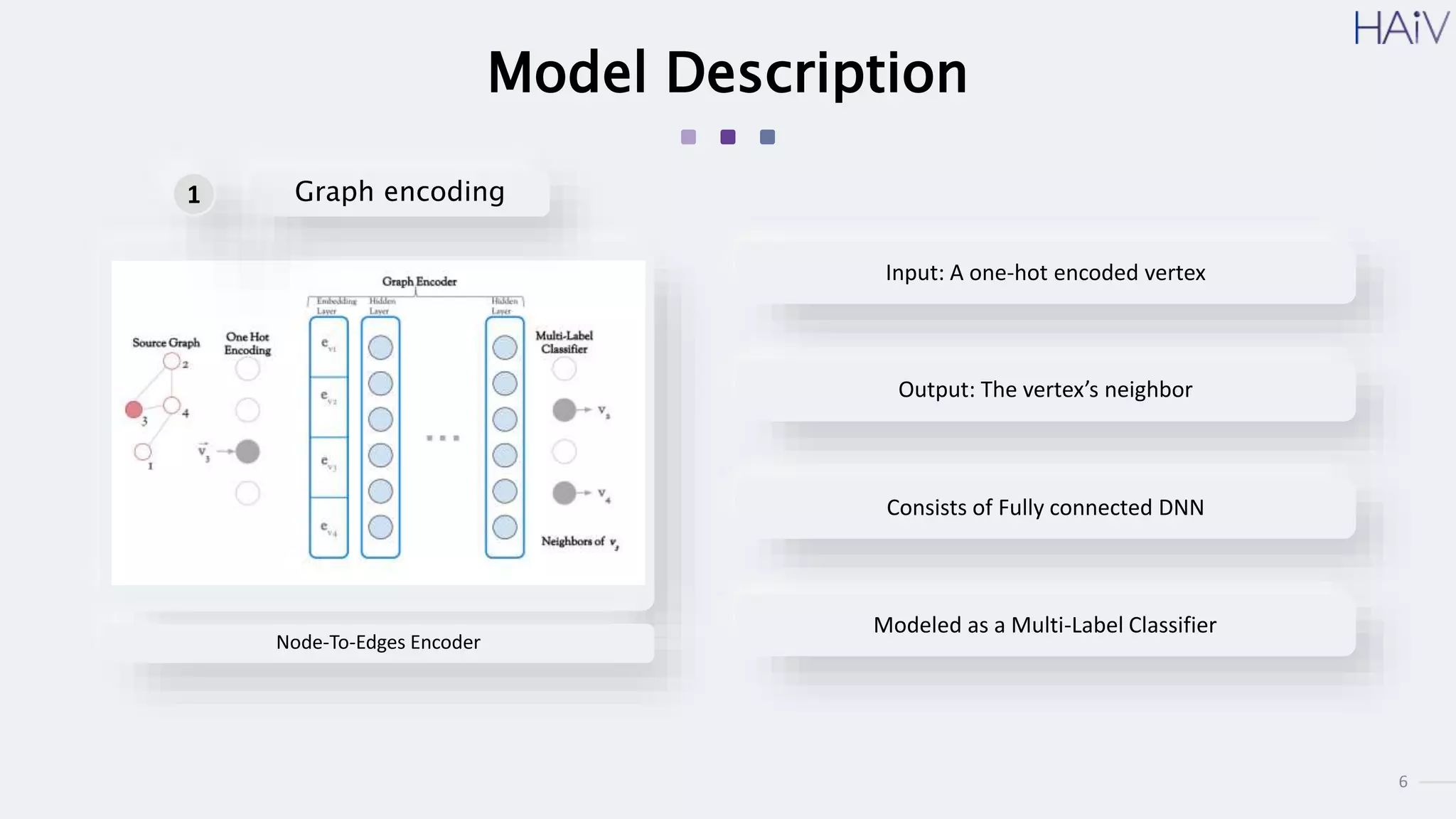
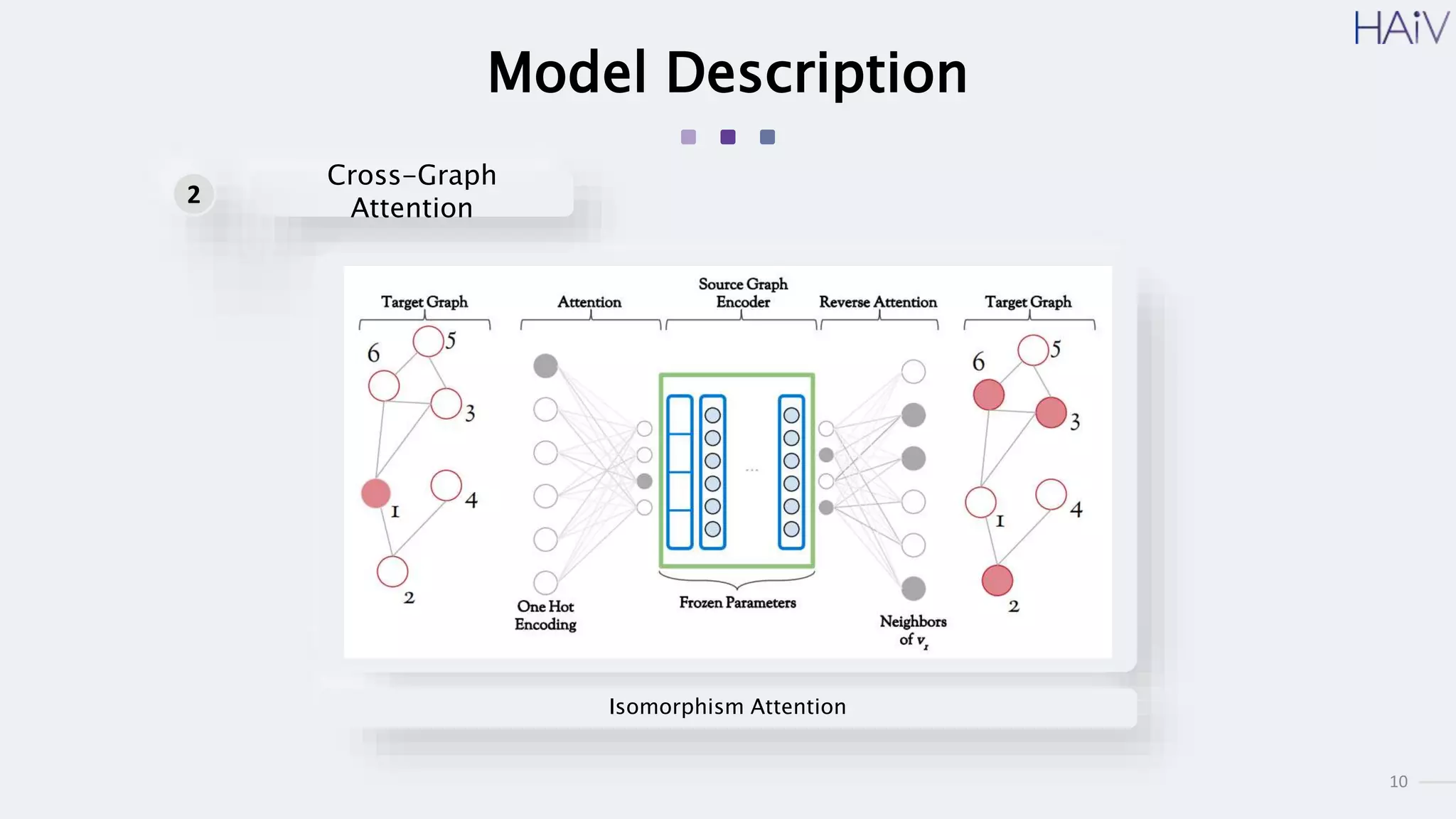
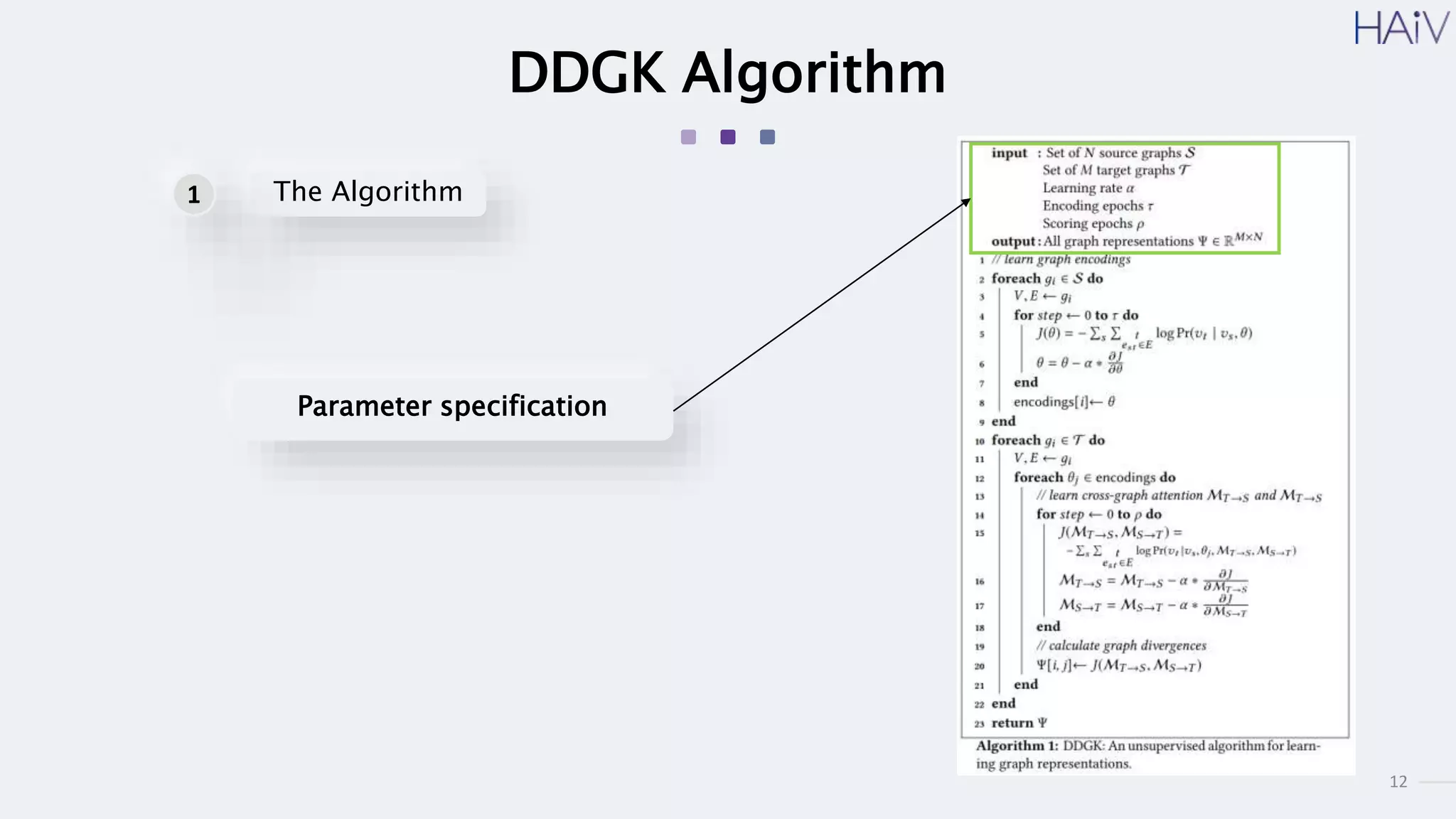
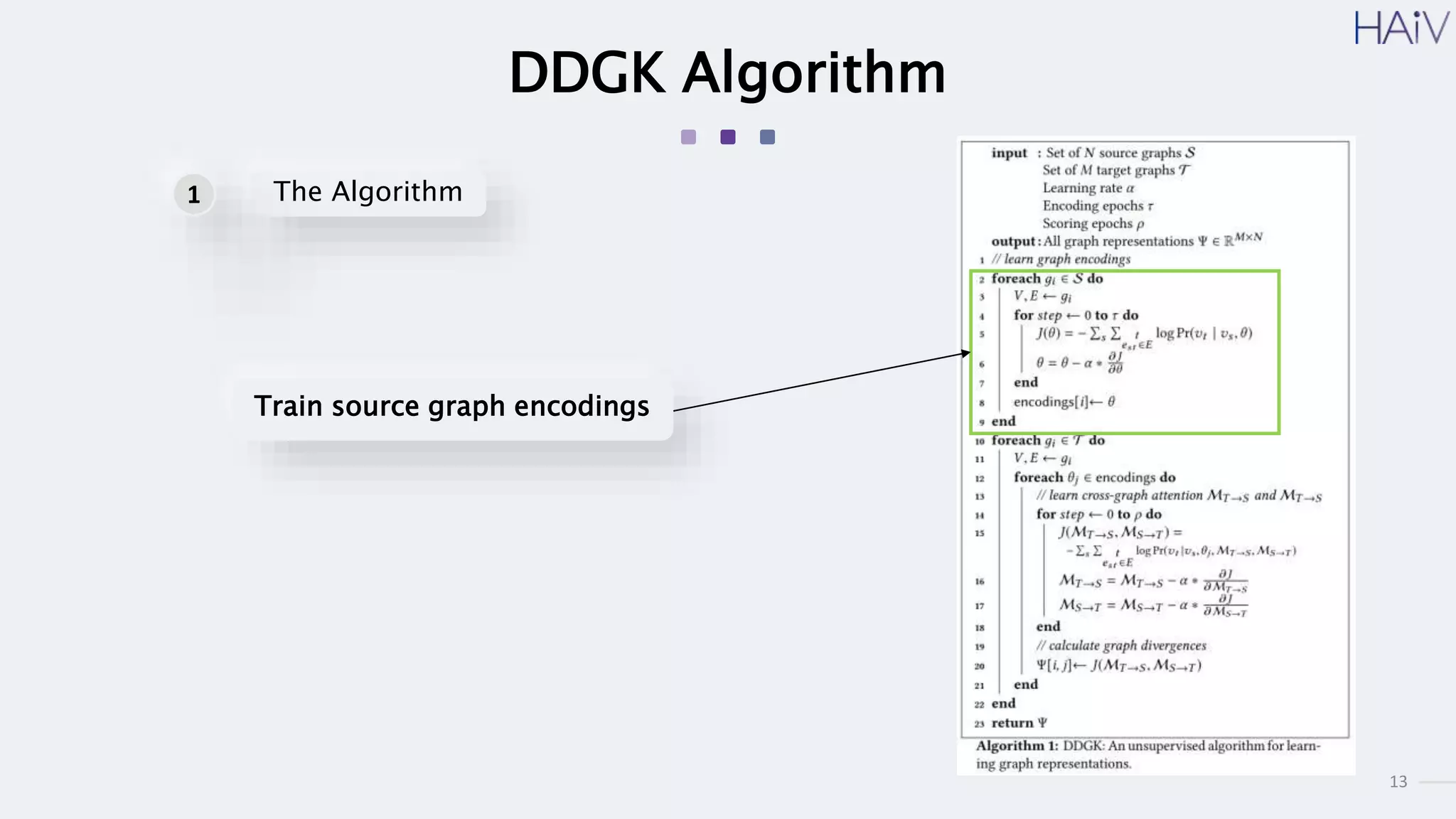
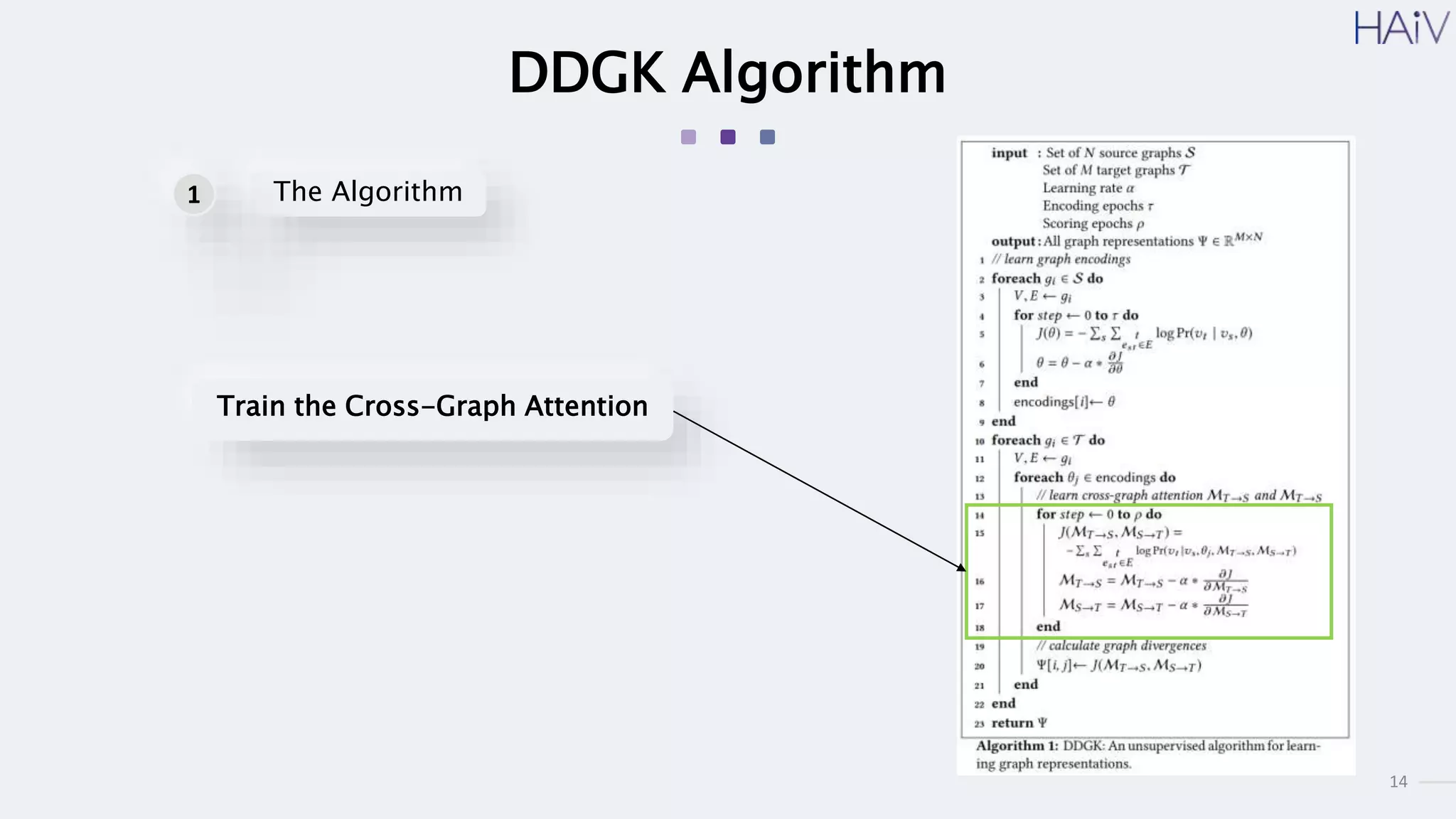
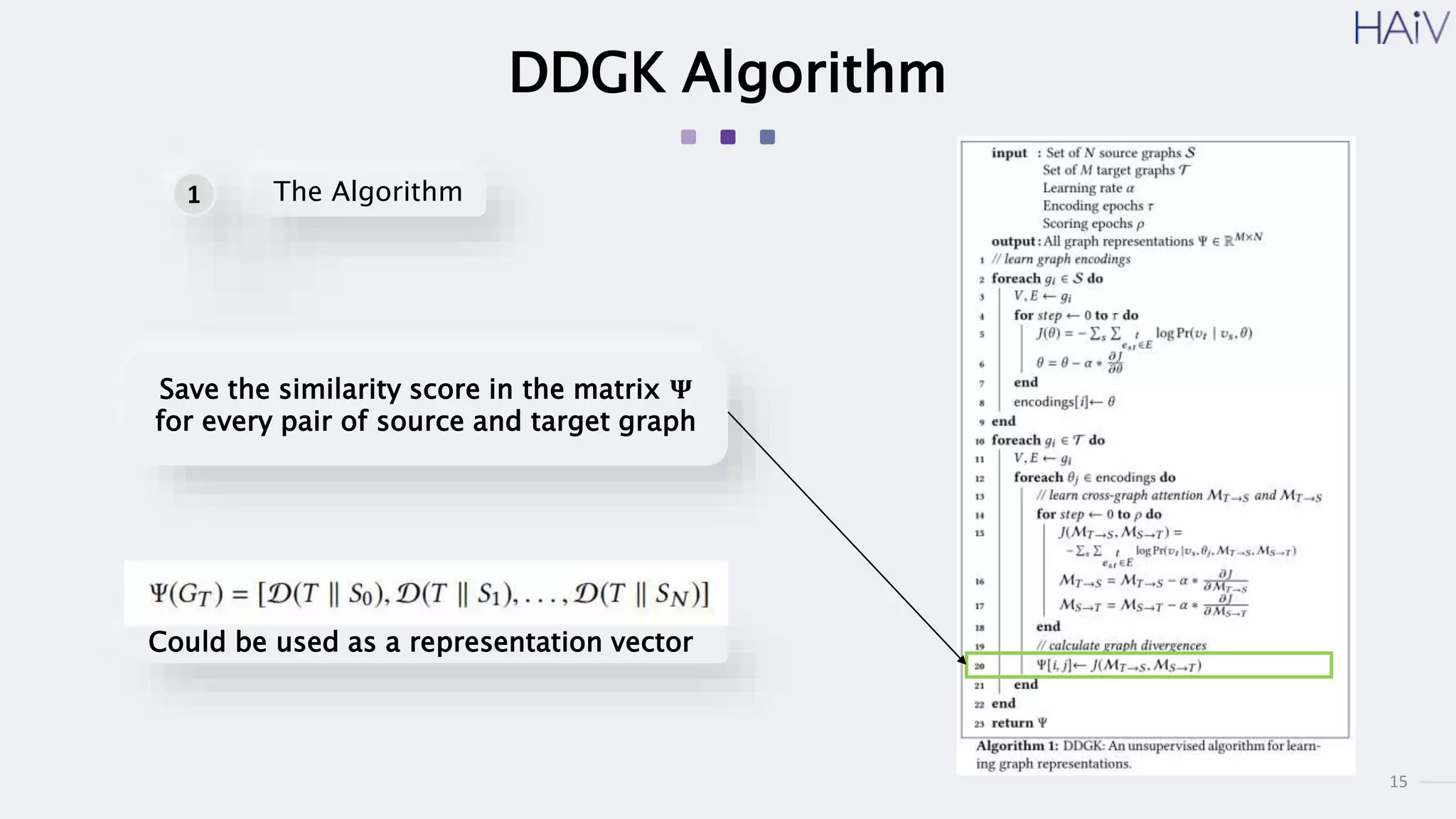
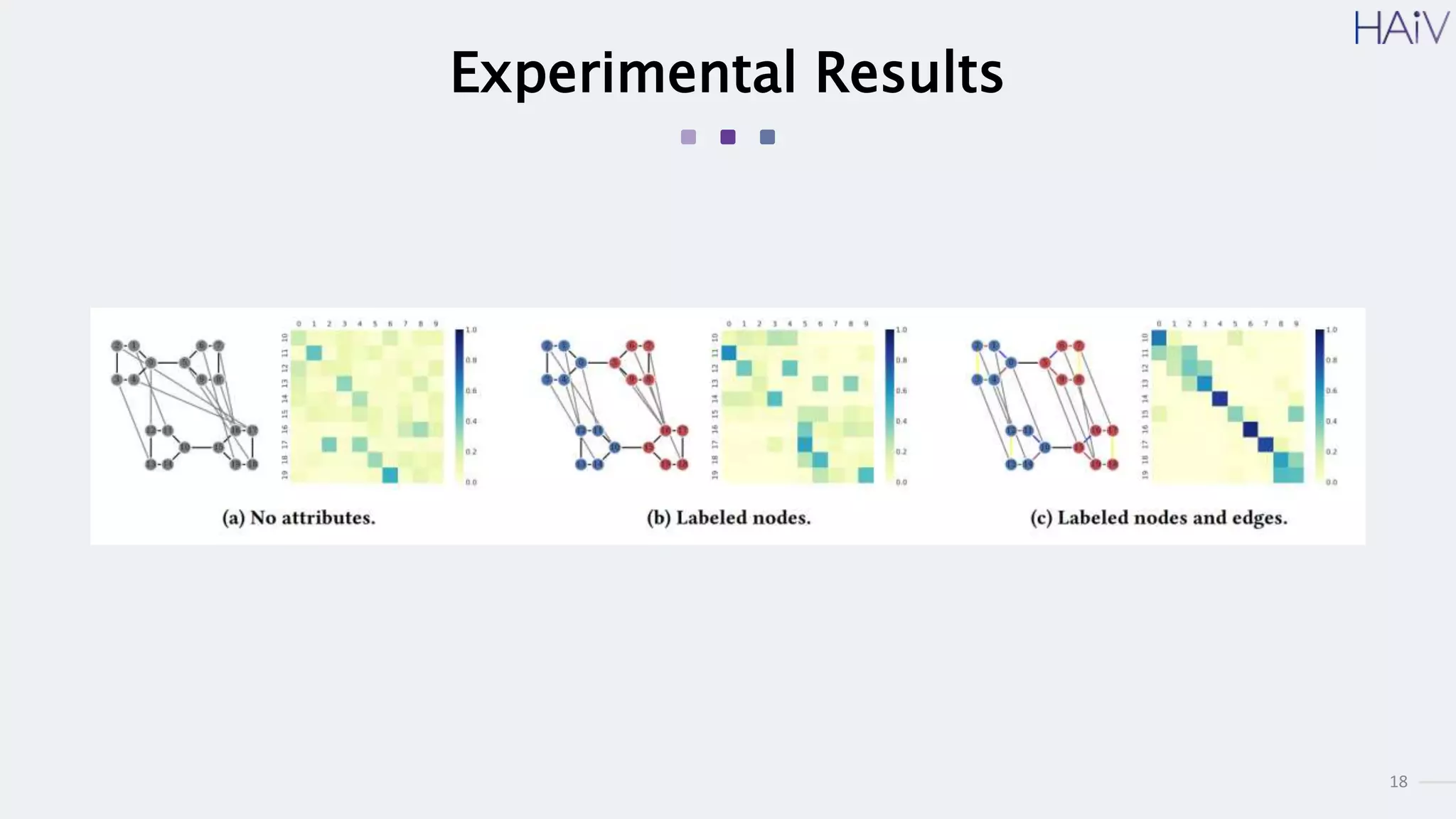
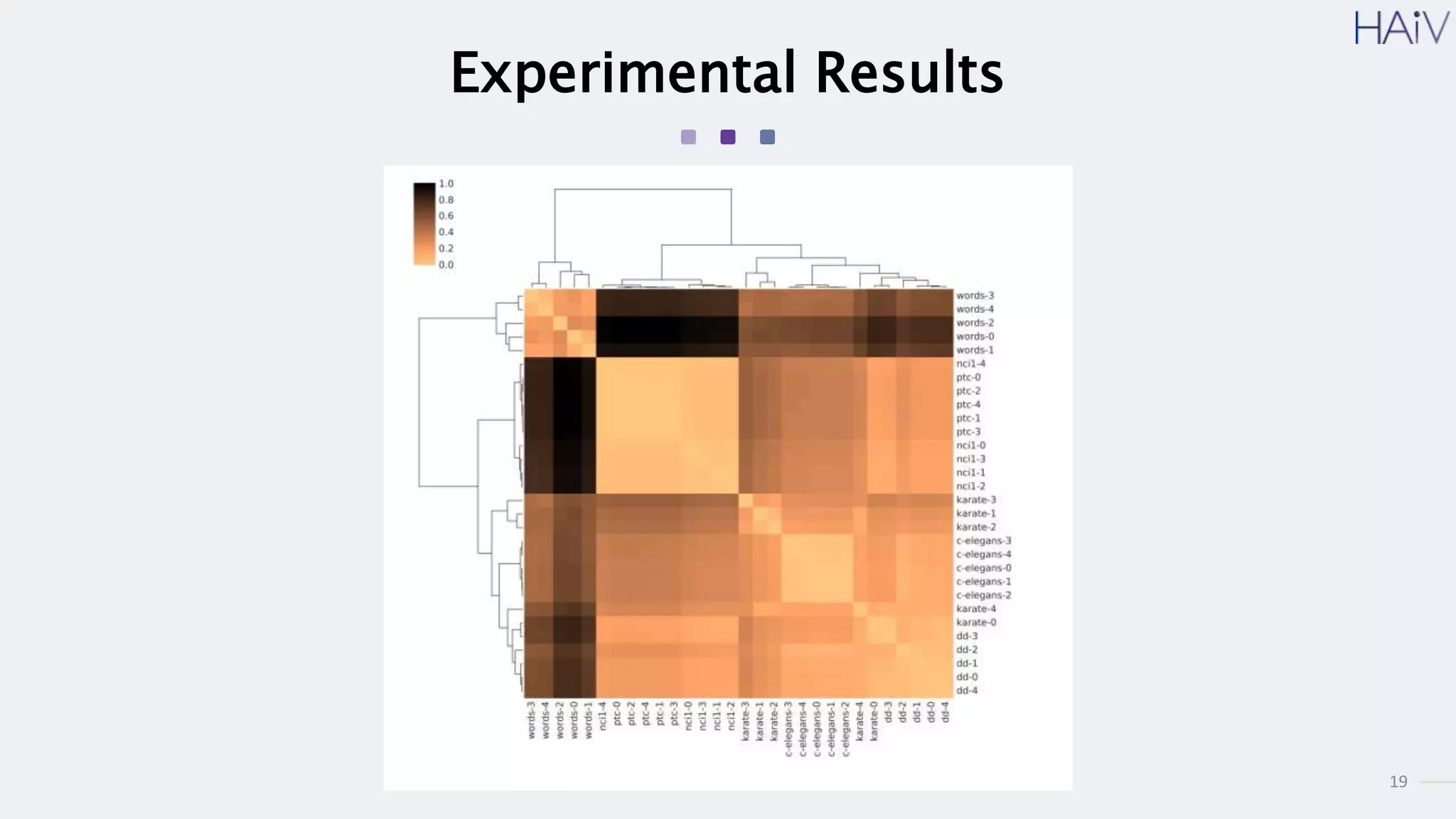
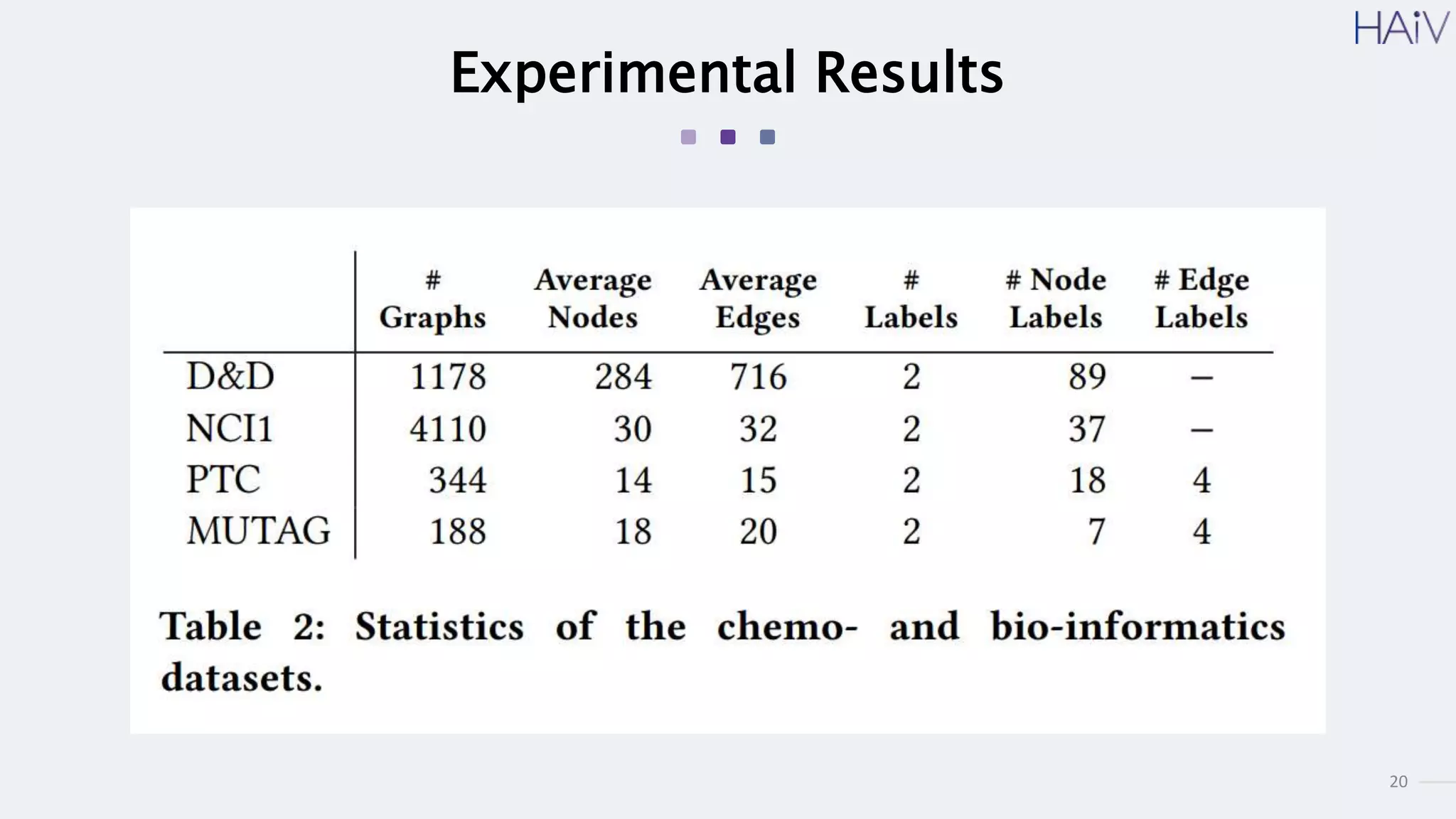
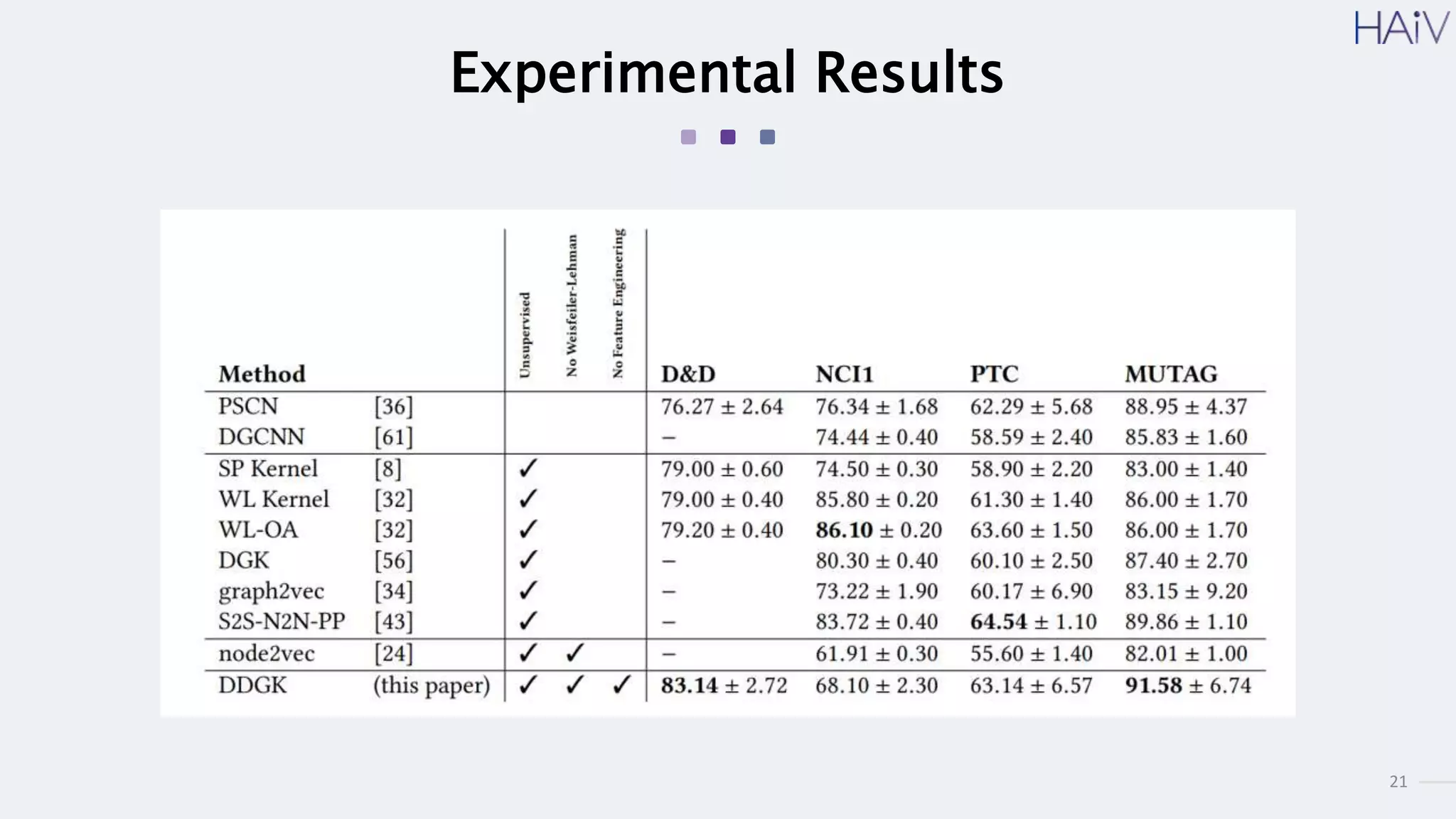
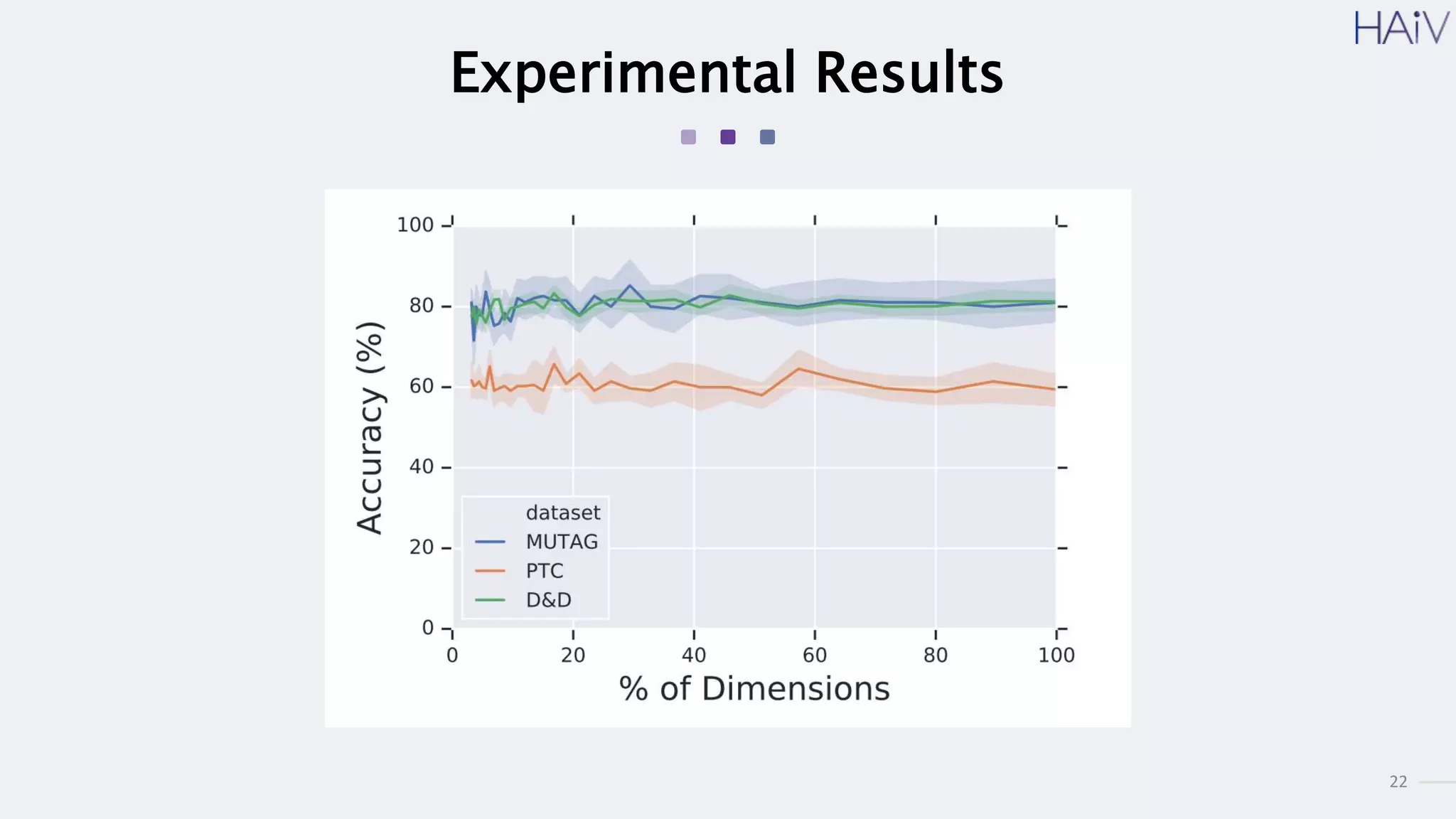
This document summarizes a research paper on learning graph representations for deep divergence graph kernels (DDGK). DDGK learns graph representations without supervision or domain knowledge by using a node-to-edges encoder and isomorphism attention. The isomorphism attention provides a bidirectional mapping between nodes in two graphs. DDGK then calculates a divergence score between the source and target graphs as a measure of their (dis)similarity. Experimental results showed DDGK produces representations competitive with other graph kernel baselines. The paper proposes several extensions, including different graph encoders and attention mechanisms, as well as improved regularization and scalability.






























![[論文紹介] Convolutional Neural Network(CNN)による超解像](https://cdn.slidesharecdn.com/ss_thumbnails/cnn-presen-161218113749-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[NS][Lab_Seminar_240619]A Simple Baseline for Weakly-Supervised Scene Graph G...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240619ws-sgg-240628124826-477bbe86-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)








