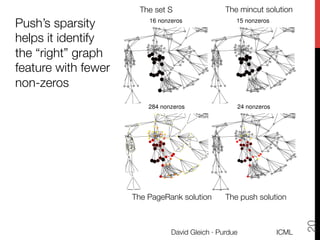
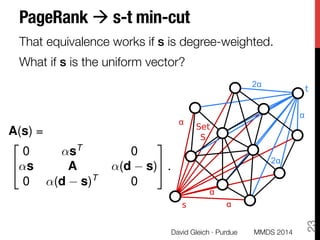
This document discusses algorithmic anti-differentiation and examines the relationship between heuristic methods, optimization problems, and their underlying objectives. It highlights applications such as the pagerank vector derivation, spectral clustering, and community detection while providing insights into the push method for efficient approximations. Additionally, it outlines open issues and potential improvements for directed graphs and semi-supervised learning algorithms.









![The PageRank problem
The PageRank random surfer
1. With probability beta, follow a
random-walk step
2. With probability (1-beta), jump
randomly ~ dist. v.
Goal find the stationary dist. x!
!
Sym. adjacency matrix
Diagonal degree matrix
Solution
Jump-vector
(I AD 1
)x = (1 )v
ICML
David Gleich · Purdue
10
[↵D + L]z = ↵v
where
= 1/(1 + ↵)
and x = Dz
Equivalent to
Combinatorial "
Laplacian](https://image.slidesharecdn.com/gleich-icml-140627065600-phpapp01/85/Anti-differentiating-approximation-algorithms-A-case-study-with-min-cuts-spectral-and-flow-10-320.jpg)