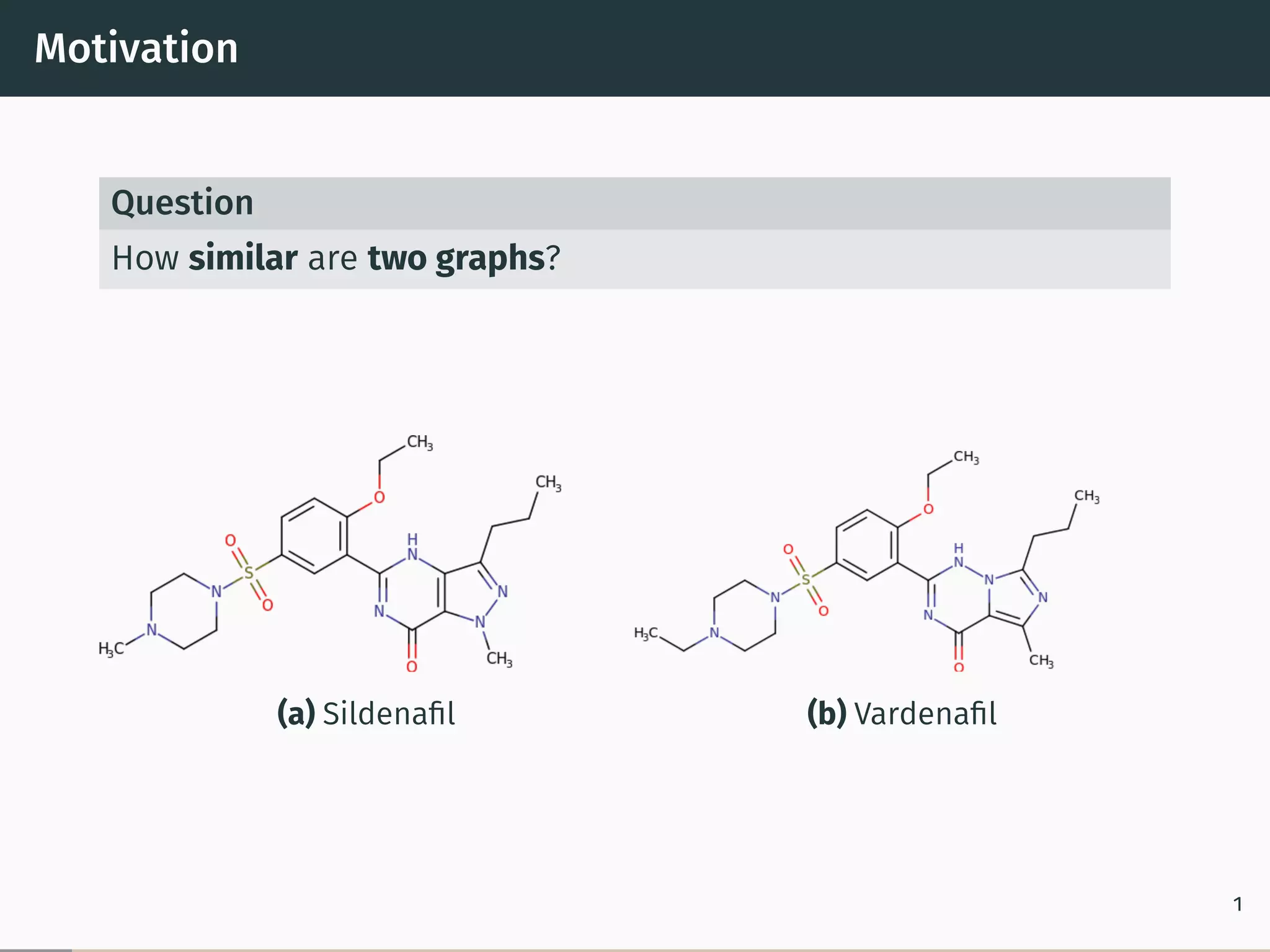
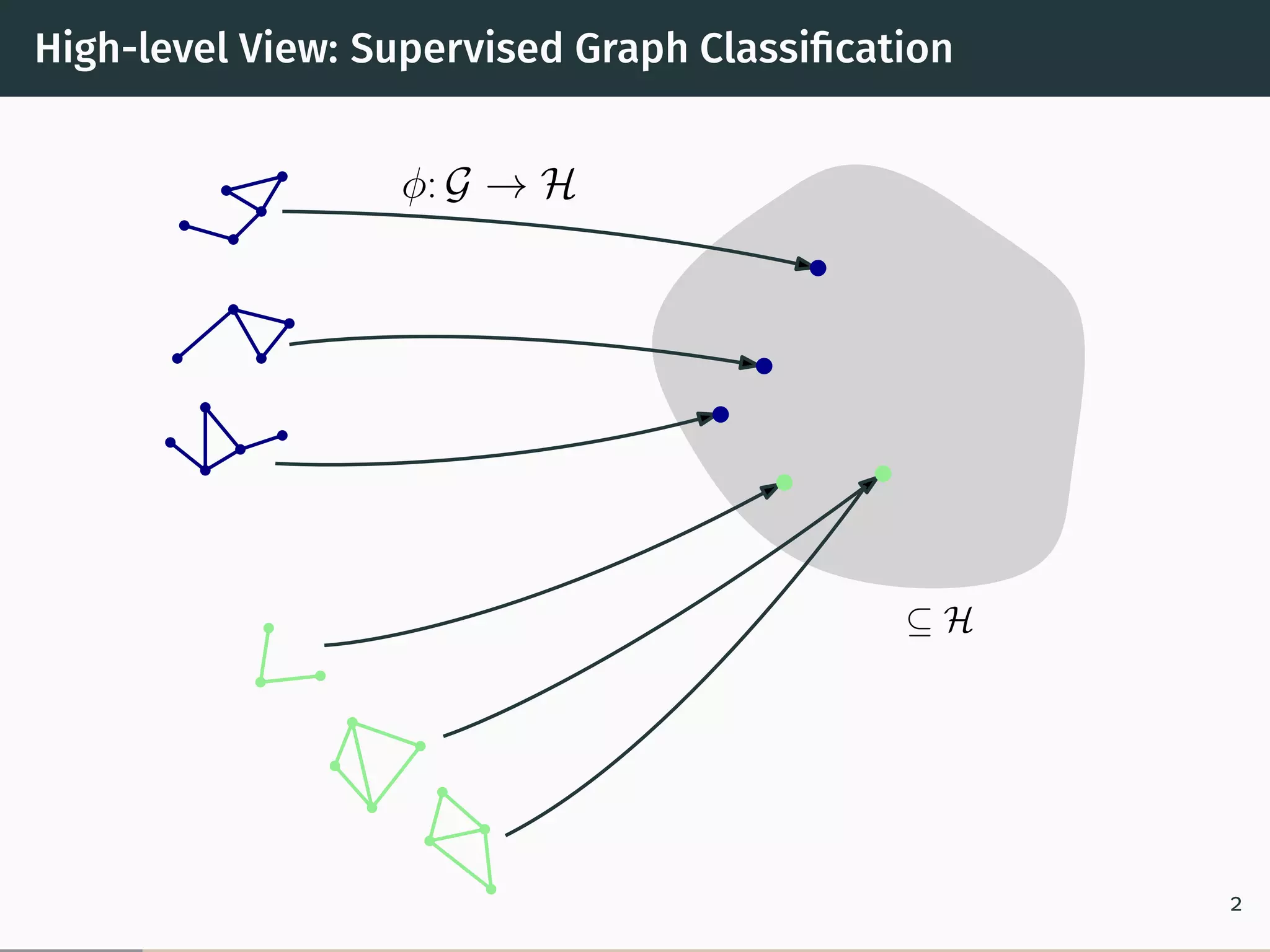
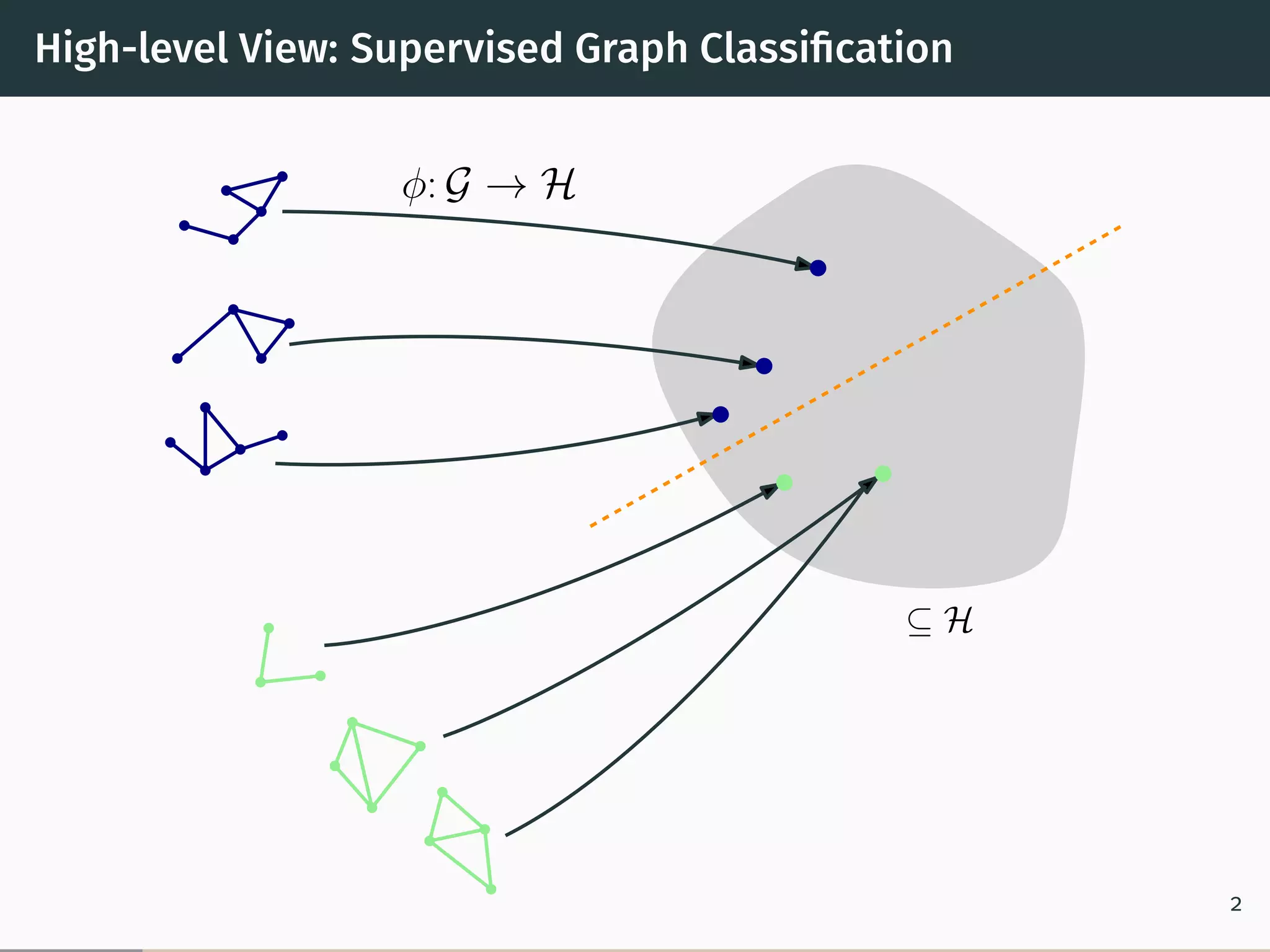
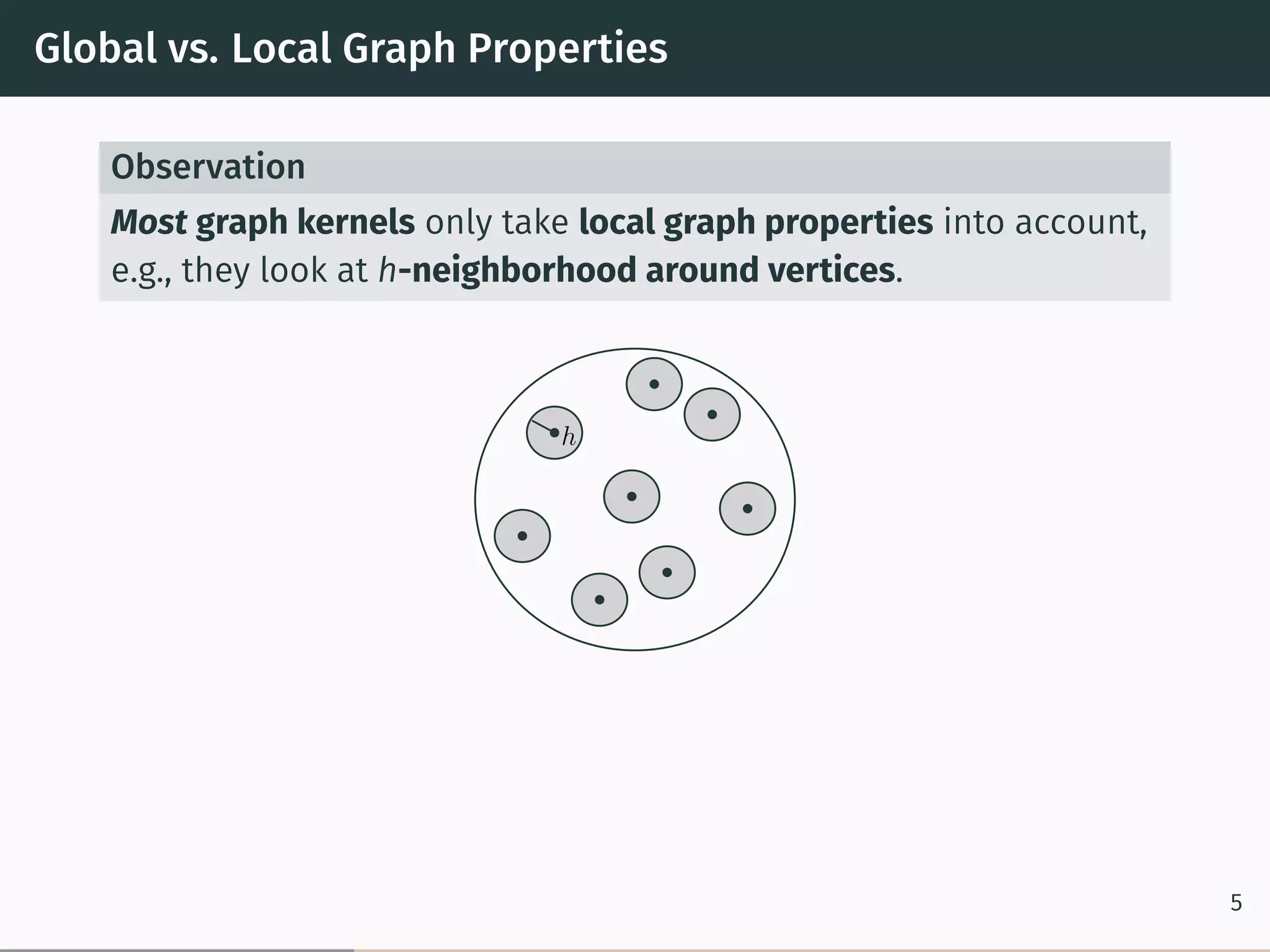
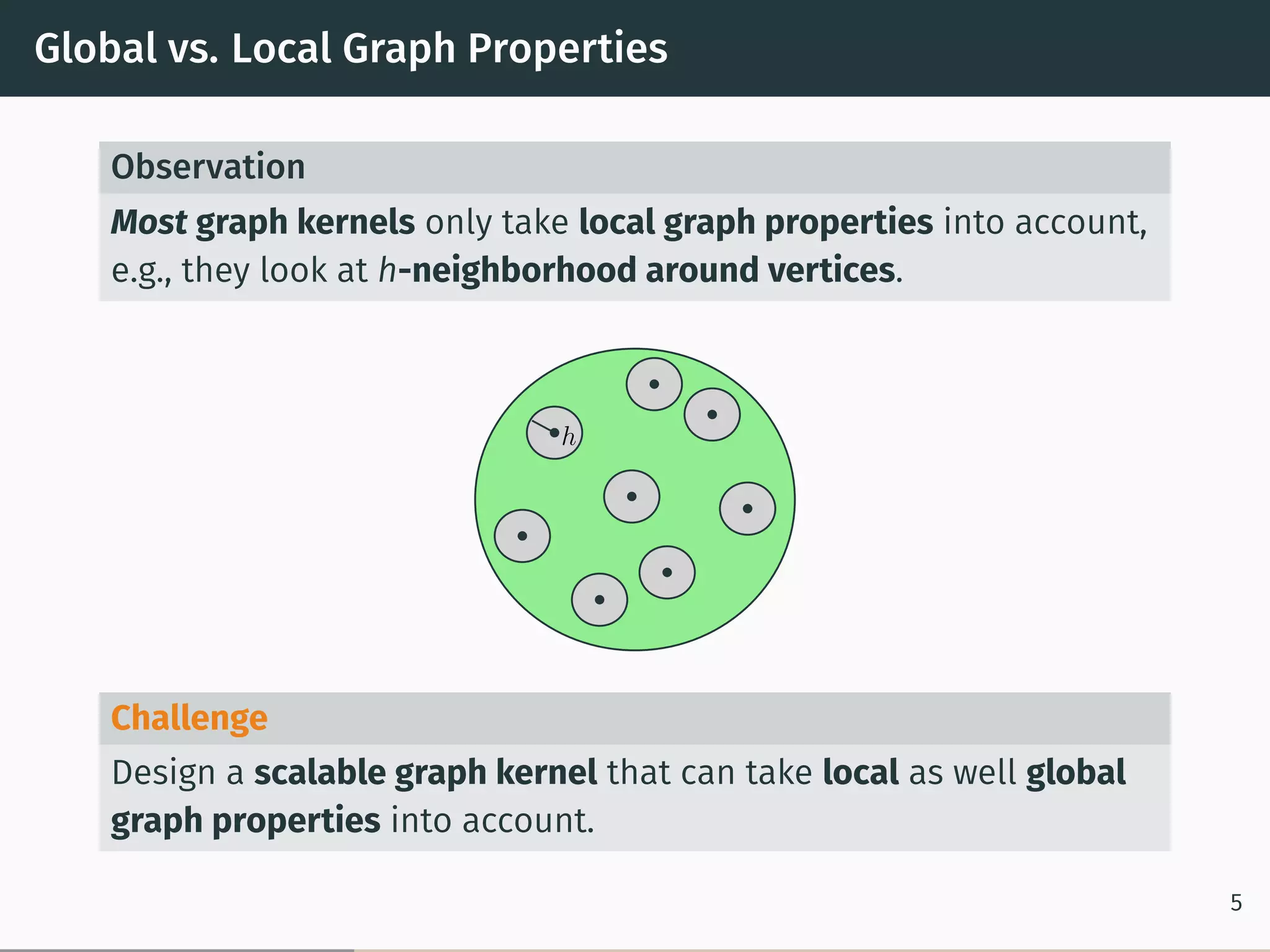
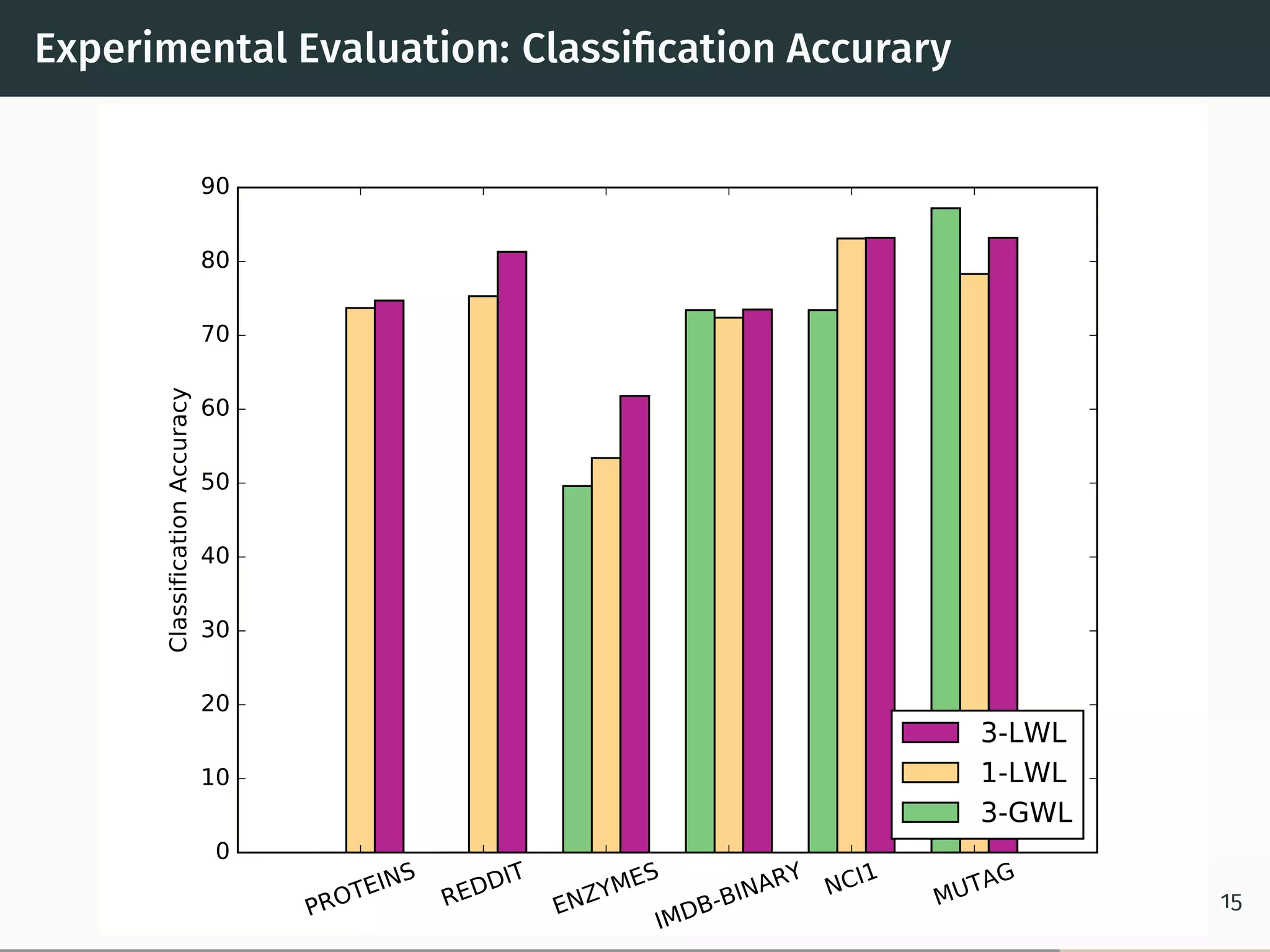
This document proposes a new graph kernel called the glocalized Weisfeiler-Lehman graph kernel. It extends the classic Weisfeiler-Lehman graph kernel to consider both local and global graph properties. The kernel maps graphs to feature vectors based on the k-dimensional Weisfeiler-Lehman algorithm. Approximation algorithms using adaptive sampling are introduced to make the kernel scalable to large graphs. Experimental results on graph classification benchmarks demonstrate the kernel achieves high accuracy while having fast running times.




![k-Dimensional Weisfeiler-Lehman
k-dimensional Weisfeiler-Lehman
• Colors vertex tuples from Vk
• Two tuples v, w are i-neighbors if vj = wj for all j ̸= i
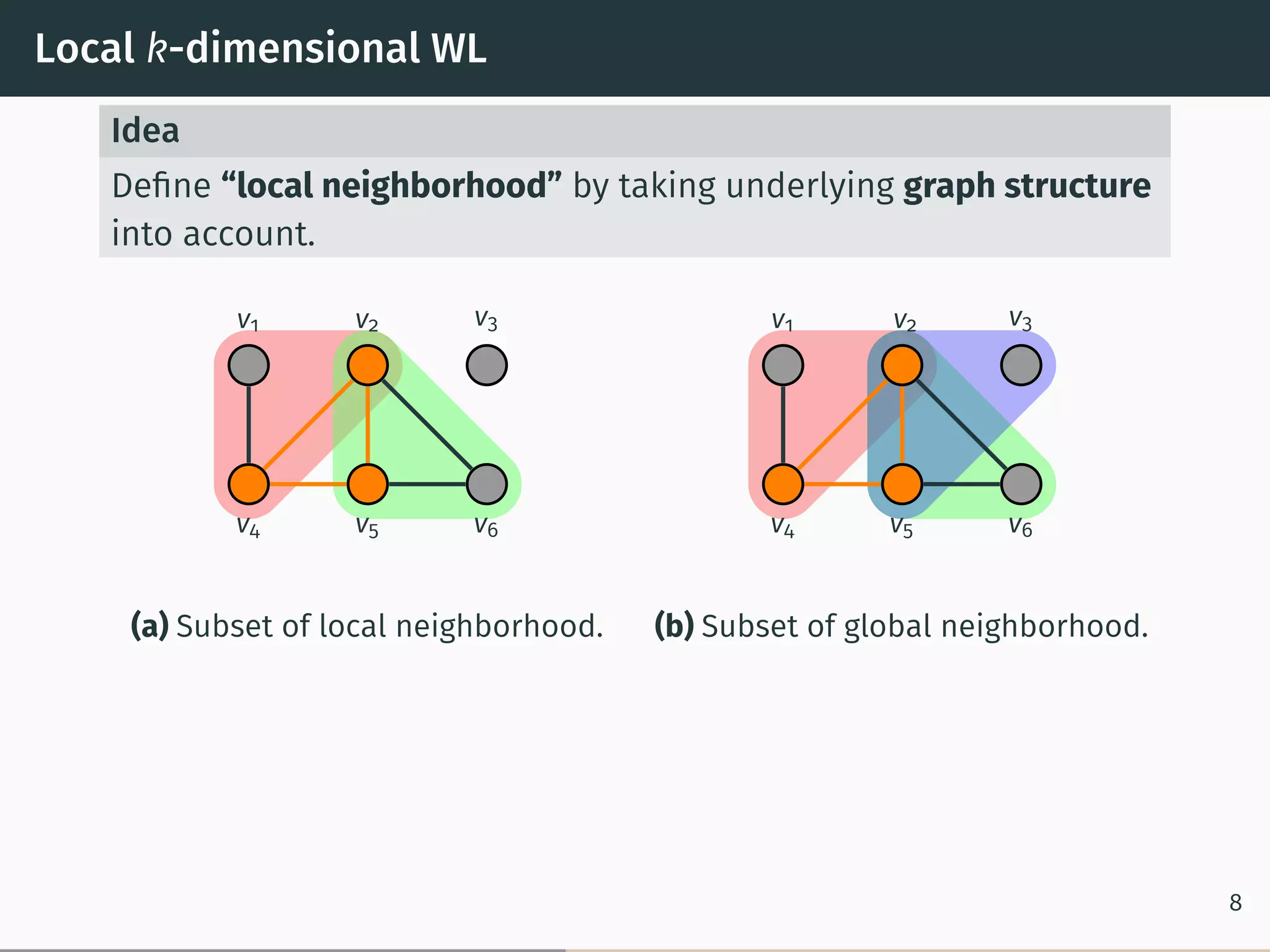
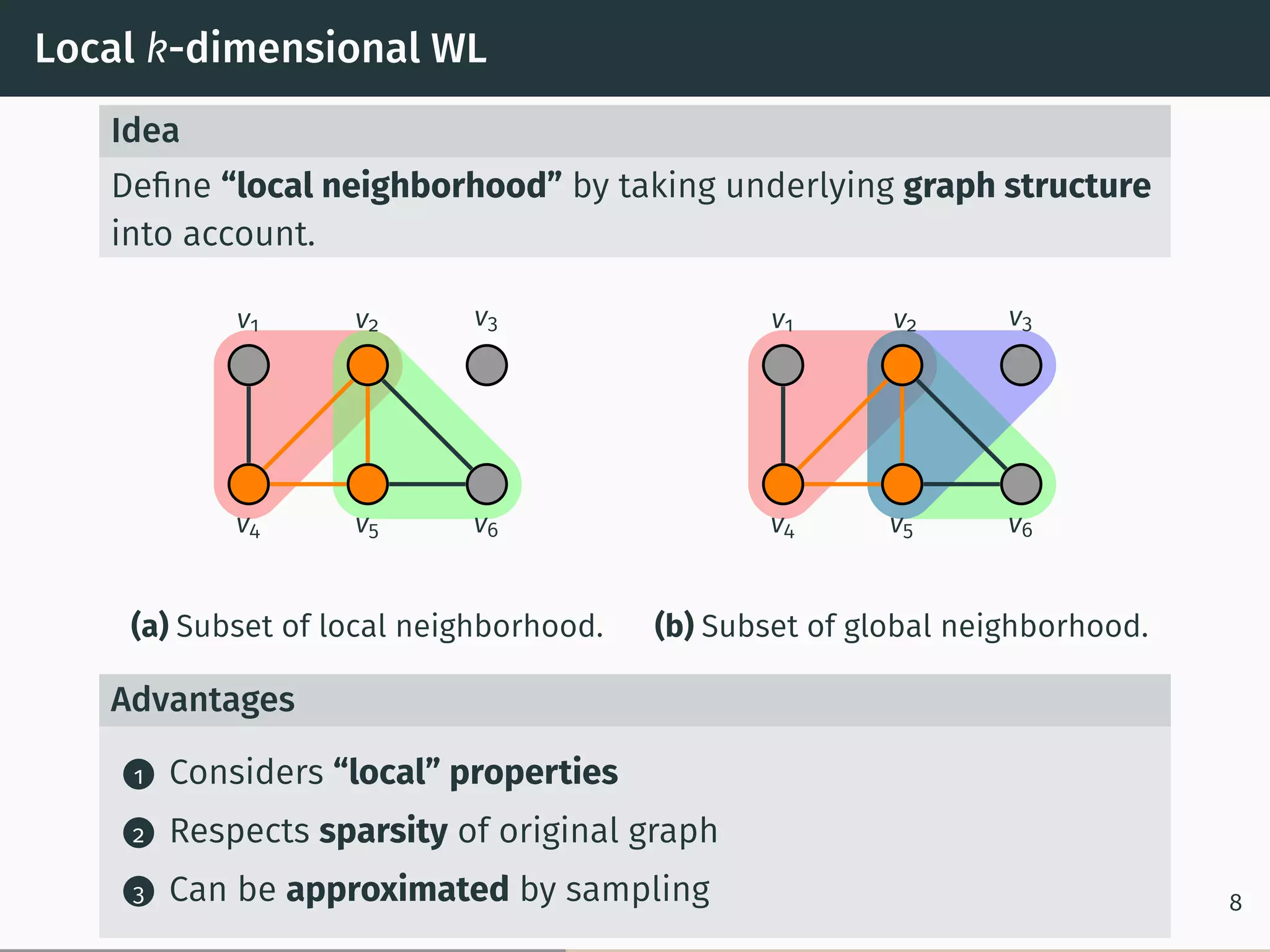
Idea of the Algorithm
Initially Initially two k-tuples v, w get the same color if vi ↦→ wi
induces a (graph) isomorphism between G[v] and G[w]
Iteration Two tuples with the same color get different colors if
there exists a color c and 1 ≤ i ≤ k such that v and w
have different i-neighbors of color c 7](https://image.slidesharecdn.com/main-171116123942/75/Glocalized-Weisfeiler-Lehman-Graph-Kernels-Global-Local-Feature-Maps-of-Graphs-15-2048.jpg)











![Experimental Evaluation: Running Times
3-LWL-SP(0.1)
3-LWL-S(0.1)
3-LWL-SP(0.05)
3-LWL-S(0.05)
3-LWL-L
3-LWL-P
3-LWL
Algorithm
0
1000
2000
3000
4000
5000
6000
7000
8000
RunningTimes[s]
PROTEINS
16](https://image.slidesharecdn.com/main-171116123942/75/Glocalized-Weisfeiler-Lehman-Graph-Kernels-Global-Local-Feature-Maps-of-Graphs-31-2048.jpg)






































![240325_JW_labseminar[node2vec: Scalable Feature Learning for Networks].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240325jwlabseminarnode2vec-240409103308-b669e744-thumbnail.jpg?width=640&height=640&fit=bounds)





























