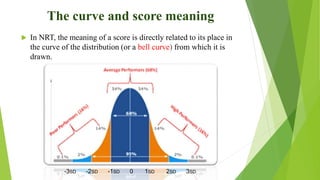
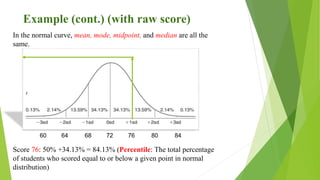
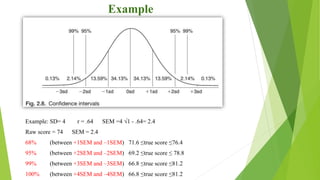
This document discusses key concepts in language testing and standardized tests. It covers two testing paradigms: norm-referenced testing which compares test takers to a group, and criterion-referenced testing which evaluates if a criterion is met. The document also defines standardized tests, explores why testing is viewed as a science, and examines concepts like central tendency, dispersion, reliability, and ways to calculate reliability such as using correlations and item analysis.