Downloaded 41 times




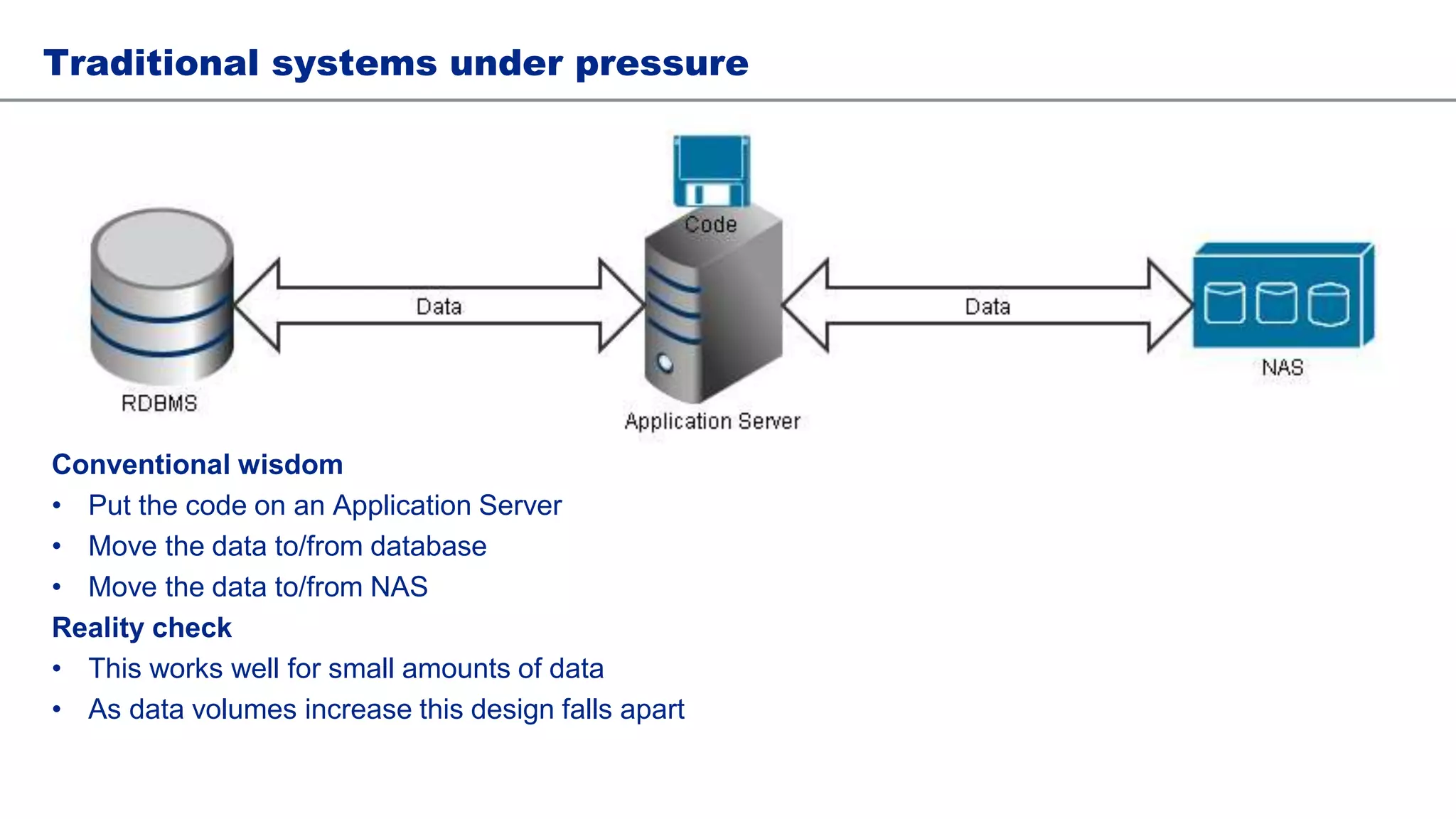















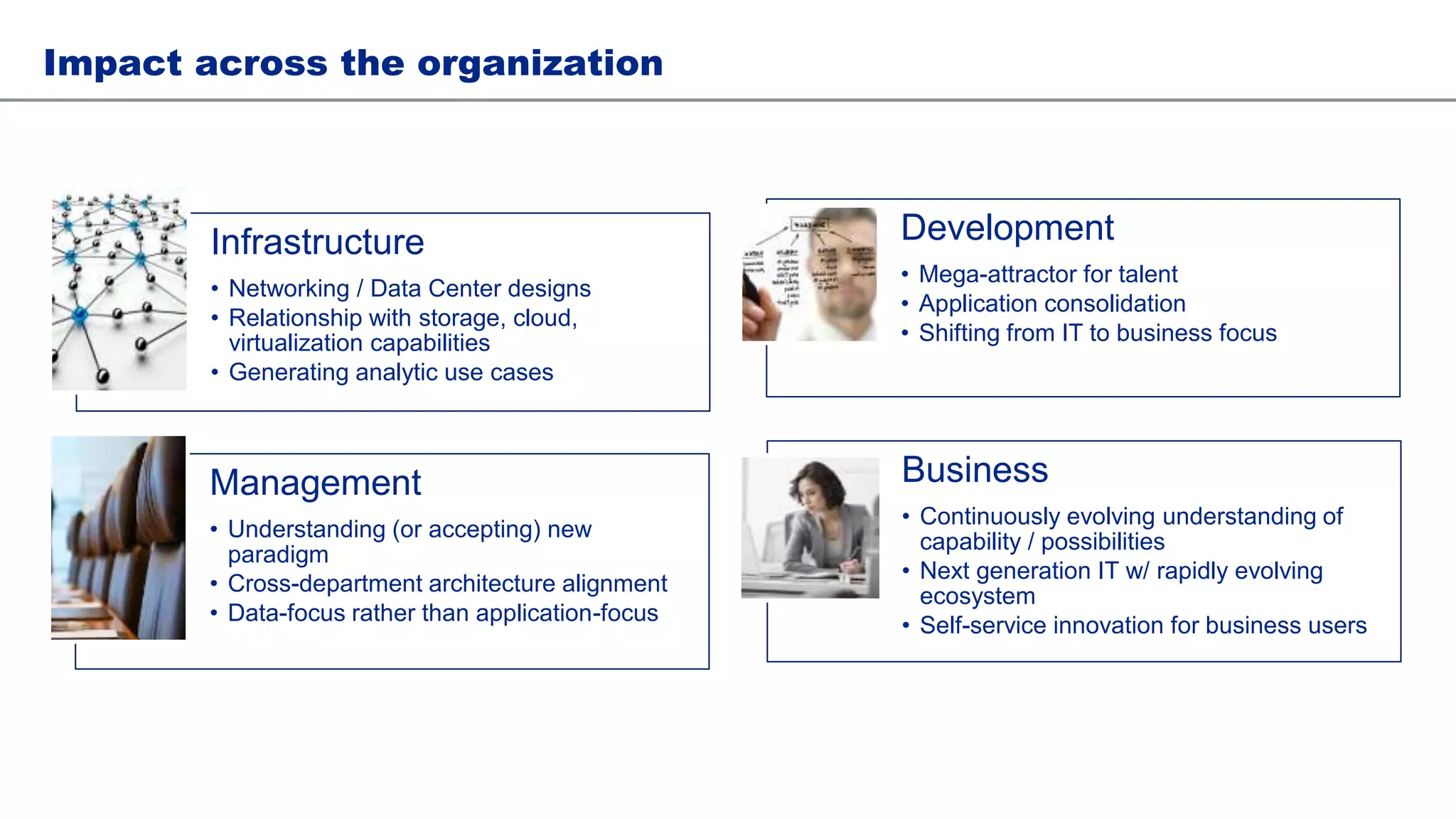






This document discusses architecting Hadoop for adoption and data applications. It begins by explaining how traditional systems struggle as data volumes increase and how Hadoop can help address this issue. Potential Hadoop use cases are presented such as file archiving, data analytics, and ETL offloading. Total cost of ownership (TCO) is discussed for each use case. The document then covers important considerations for deploying Hadoop such as hardware selection, team structure, and impact across the organization. Lastly, it discusses lessons learned and the need for self-service tools going forward.











































































































