Download to read offline



























![mysqlsh -u root --sql
Enter password: ****
mysql-py> db.createCollection("flags")
<Collection:flags>
mysql-py> db.getCollections()
[
<Collection:CountryInfo>,
<Collection:flags>
]
mysql-py> db.CountryInfo.find("GNP > 500000")
...[output removed]
10 documents in set (0.00 sec)](https://image.slidesharecdn.com/polyglotdatabase-stokes-160819194807/75/Polyglot-Database-Linuxcon-North-America-2016-30-2048.jpg)










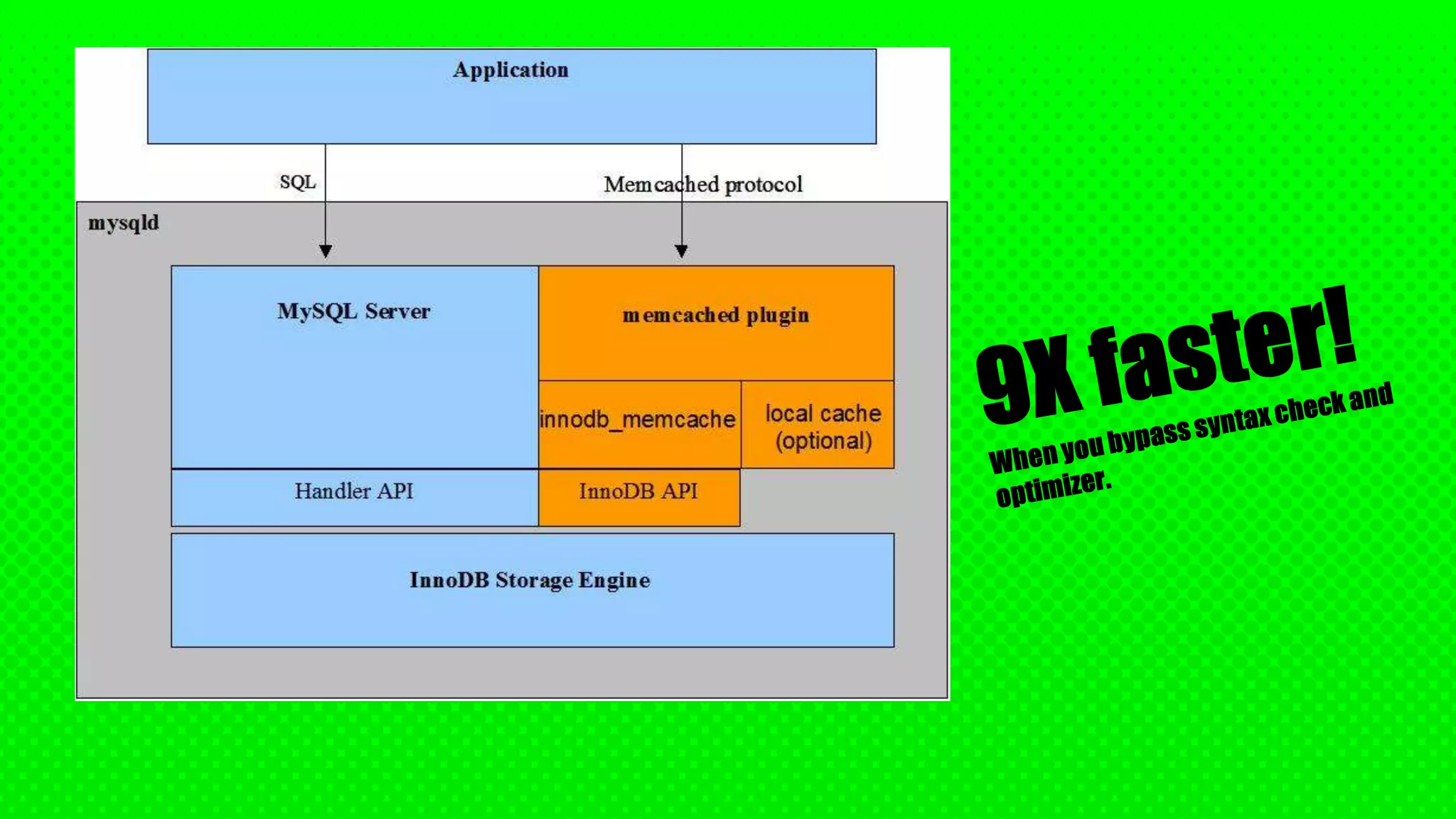
The document outlines Oracle's direction regarding polyglot databases, particularly developments related to MySQL 8, which introduces new features like a real-time data dictionary and a native JSON data type. It discusses the evolution of relational databases to accommodate NoSQL features, enabling schema-less document storage while highlighting the ease of CRUD operations through the new X DevAPI. Additionally, various connectors for programming languages are mentioned, emphasizing MySQL's adaptability and modernized approach to database management.


























![[db tech showcase Tokyo 2017] C34: Replacing Oracle Database at DBS Bank ~Ora...](https://cdn.slidesharecdn.com/ss_thumbnails/replacingoracledatabaseatdbsbankdbtechshowcasetokyosept2017-170911075631-thumbnail.jpg?width=640&height=640&fit=bounds)






































![[OSC 2020 Online/Nagoya] MySQLドキュメントストア](https://cdn.slidesharecdn.com/ss_thumbnails/20200530oscngodocstorejp-200729120854-thumbnail.jpg?width=640&height=640&fit=bounds)











![MySQL Without The SQL -- Oh My! PHP[Tek] June 2018](https://cdn.slidesharecdn.com/ss_thumbnails/mysqlohmy-180601154804-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)
