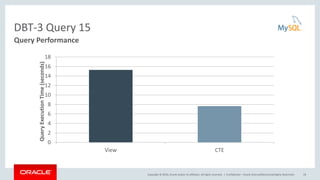
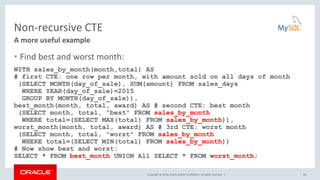
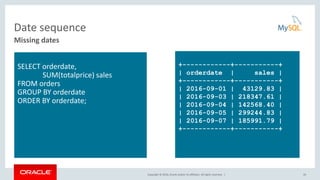
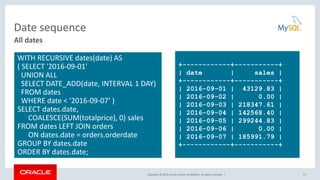
This document discusses common table expressions (CTEs) in MySQL 8.0. It begins with an introduction to CTEs, explaining how they provide an alternative to derived tables. The document then covers non-recursive and recursive CTEs. For non-recursive CTEs, it provides examples of finding the best and worst month of sales. For recursive CTEs, it demonstrates examples such as generating a sequence of numbers and traversing a employee hierarchy. The key benefits of CTEs over derived tables are also summarized, such as improved readability, ability to reference a CTE multiple times, and potential performance improvements from avoiding multiple materializations.





![Copyright © 2016, Oracle and/or its affiliates. All rights reserved. |
CTE
WITH cte_name [( <list of column names> )] AS
(
SELECT ... # Definition
)
[, <any number of other CTE definitions> ]
<SELECT/UPDATE/DELETE statement>
5
Syntax](https://image.slidesharecdn.com/cte-plams2016-161021085204/85/MySQL-8-0-Common-Table-Expressions-5-320.jpg)


















![Copyright © 2016, Oracle and/or its affiliates. All rights reserved. |
Recursive CTE
• WITH RECURSIVE cte_name [list of column names ] AS
(
SELECT ... <-- specifies initial set
UNION ALL
SELECT ... <-- specifies initial set
UNION ALL
...
SELECT ... <-- specifies how to derive new rows
UNION ALL
SELECT ... <-- specifies how to derive new rows
...
)
[, any number of other CTE definitions ]
32
Complete syntax](https://image.slidesharecdn.com/cte-plams2016-161021085204/85/MySQL-8-0-Common-Table-Expressions-32-320.jpg)



































































![[APJ] Common Table Expressions (CTEs) in SQL](https://cdn.slidesharecdn.com/ss_thumbnails/cte-employer-191211130137-thumbnail.jpg?width=640&height=640&fit=bounds)




![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

















