Download as PDF, PPTX








![Copyright © 2014, Oracle and/or its affiliates. 9 All rights reserved.
EXPLAIN
{ "query_block": {
"select_id": 1,
"ordering_operation": {
"using_filesort": false,
"grouping_operation": {
"using_temporary_table": true,
"using_filesort": true,
"table": {
"table_name": "lineitem“,
"access_type": "ALL“,
"possible_keys": [
"i_l_shipdate”
],
"rows": 2829575,
"filtered": 50,
"attached_condition":
"(`dbt3`.`lineitem`.`l_shipDATE` <=
<cache>(('1998-12-01' - interval '118' day)))”
} /* table */
} /* grouping_operation */
} /*ordering_operation */
} /*query_block */ }
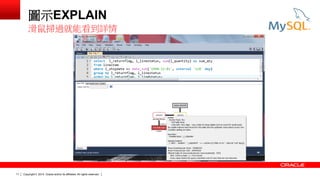
結構化 EXPLAIN
EXPLAIN FORMAT=JSON
SELECT l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty
FROM lineitem
WHERE l_shipdate <=
DATE_SUB('1998-12-01',
INTERVAL '118' DAY)
GROUP BY l_returnflag, l_linestatus
ORDER BY l_returnflag, l_linestatus;
MySQL 5.6的新功能](https://image.slidesharecdn.com/explain-taipei-zt-140909020842-phpapp02/85/MySQL-EXPLAIN-Explained-Norvald-H-Ryeng-9-320.jpg)










![Copyright © 2014, Oracle and/or its affiliates. 22 All rights reserved.
使用加了索引欄位
結構化的 EXPLAIN
EXPLAIN
{ "query_block": {
"select_id": 1,
"table": {
"table_name": "orders",
"access_type": "range",
"possible_keys": [
"i_o_orderdate",
"i_o_clerk_status_date"
],
"key": "i_o_clerk_status_date",
"used_key_parts": [
"o_clerk"
],
"key_length": "16",
"rows": 1504,
"filtered": 100,
"index_condition": "((`dbt3`.`orders`.`o_orderDATE` between
'1997-05-01' and '1997-05-31') and (`dbt3`.`orders`.`o_clerk` like
'Clerk#000001866'))"
} } }
EXPLAIN
{ "query_block": {
"select_id": 1,
"table": {
"table_name": "orders",
"access_type": "range",
"possible_keys": [
"i_o_orderdate",
"i_o_clerk_status_date",
"i_o_clerk_date_status"
],
"key": "i_o_clerk_date_status",
"used_key_parts": [
"o_clerk",
"o_orderDATE"
],
"key_length": "20",
"rows": 15,
"filtered": 100,
"index_condition": "((`dbt3`.`orders`.`o_orderDATE` between
'1997-05-01' and '1997-05-31') and (`dbt3`.`orders`.`o_clerk` like
'Clerk#000001866'))"
} } }](https://image.slidesharecdn.com/explain-taipei-zt-140909020842-phpapp02/85/MySQL-EXPLAIN-Explained-Norvald-H-Ryeng-22-320.jpg)



![Copyright © 2014, Oracle and/or its affiliates. 26 All rights reserved.
EXPLAIN
{
"query_block": {
"select_id": 1,
"nested_loop": [
{
"table": {
"table_name": "customer“,
"access_type": "ALL“,
"possible_keys": [
"PRIMARY”
],
"rows": 147973,
"filtered": 100,
"attached_condition":
"(`dbt3`.`customer`.`c_acctbal` < <cache>(-(1000)))”
} /* table */
},
{
"table": {
"table_name": "orders“,
"access_type": "ref“,
"possible_keys": [
"i_o_custkey”
],
"key": "i_o_custkey“,
"used_key_parts": [
"o_custkey”
],
"key_length": "5“,
"ref": [
"dbt3.customer.c_custkey
],
"rows": 7,
"filtered": 100
} /* table */
}
] /* nested_loop */
} /* query_block */
}
結構化EXPLAIN: Join 查詢](https://image.slidesharecdn.com/explain-taipei-zt-140909020842-phpapp02/85/MySQL-EXPLAIN-Explained-Norvald-H-Ryeng-26-320.jpg)











![Copyright © 2014, Oracle and/or its affiliates. 38 All rights reserved.
EXPLAIN
"query_block": {
"select_id": 1,
"table": {
"update": true,
"table_name": "t1",
"access_type": "range",
"possible_keys": [ "a", "a_2" ],
"key": "a", "key_length": "5",
"rows": 2, "filtered": 100,
"using_temporary_table": "for update",
"attached_condition": "(`test`.`t1`.`a` < 10)"
} /* table */
} /* query_block */
EXPLAINing非Select查詢
EXPLAIN FORMAT=JSON
UPDATE t1
SET a = 10
WHERE a < 10;
結構化的EXPLAIN](https://image.slidesharecdn.com/explain-taipei-zt-140909020842-phpapp02/85/MySQL-EXPLAIN-Explained-Norvald-H-Ryeng-38-320.jpg)


![Copyright © 2014, Oracle and/or its affiliates. 41 All rights reserved.
優化器Trace:範例
mysql> SET optimizer_trace= “enabled=on“,
end_markers_in_json=on;
mysql> SELECT * FROM t1,t2 WHERE f1=1 AND f1=f2 AND f2>0;
mysql> SELECT trace FROM
information_schema.OPTIMIZER_TRACE;
mysql> SET optimizer_trace="enabled=off";
QUERY SELECT * FROM t1,t2 WHERE f1=1 AND f1=f2 AND f2>0;
TRACE “steps”: [ { "join_preparation": { "select#": 1,… } … } …]
MISSING_BYTES_BEYOND_MAX_MEM_SIZE 0
INSUFFICIENT_PRIVILEGES 0](https://image.slidesharecdn.com/explain-taipei-zt-140909020842-phpapp02/85/MySQL-EXPLAIN-Explained-Norvald-H-Ryeng-41-320.jpg)
![Copyright © 2014, Oracle and/or its affiliates. 42 All rights reserved.
優化器Trace:範例
join_optimization / row_estimation / table : t1, range_analysis
"table_scan": {
"rows": 5,
"cost": 5.1085
} /* table_scan */,
"potential_range_indices": [ {
"index": "f1", "usable": true,
"key_parts": [ "f1“ ] /* key_parts */ }
] /* potential_range_indices */,
"best_covering_index_scan": {
"index": "f1", "cost": 2.093, "chosen": true
} /* best_covering_index_scan */,
"group_index_range": {
"chosen": false, "cause": "not_single_table"
} /* group_index_range */,
"analyzing_range_alternatives": {
"range_scan_alternatives": [ {
"index": "f1",
"ranges": [ "1 <= f1 <= 1“ ] /* ranges */,
"index_dives_for_eq_ranges": true,
"rows": 2, "cost": 3.41,
"chosen": false,
"cause": "cost"
}
] /* range_scan_alternatives */,
"analyzing_roworder_intersect": {
"usable": false, "cause": "too_few_roworder_scans"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */](https://image.slidesharecdn.com/explain-taipei-zt-140909020842-phpapp02/85/MySQL-EXPLAIN-Explained-Norvald-H-Ryeng-42-320.jpg)
![Copyright © 2014, Oracle and/or its affiliates. 43 All rights reserved.
優化器Trace: 範例
join_optimization / considered_execution_plan
"plan_prefix": [ ] /* plan_prefix */,
"table": "`t2`",
"best_access_path": {
"considered_access_paths": [ {
"access_type": "scan", "rows": 3,
"cost": 2.6051, "chosen": true
} ] /* considered_access_paths */
} /* best_access_path */,
"cost_for_plan": 2.6051,
"rows_for_plan": 3,
"rest_of_plan": [ {
… next iteration … =>
} ] /* rest_of_plan */
"plan_prefix": [ "`t2`“ ] /* plan_prefix */,
"table": "`t1`",
"best_access_path": {
"considered_access_paths": [ {
"access_type": "ref", "index": "f1",
"rows": 2, "cost": 3.4698, "chosen": true
}, {
"access_type": "scan", "using_join_cache": true,
"rows": 2, "cost": 3.8087,
"chosen": true
} ] } /* best_access_path */,
"cost_for_plan": 6.4138,
"rows_for_plan": 6,
"chosen": true](https://image.slidesharecdn.com/explain-taipei-zt-140909020842-phpapp02/85/MySQL-EXPLAIN-Explained-Norvald-H-Ryeng-43-320.jpg)







This document discusses using EXPLAIN to optimize queries in MySQL. It covers traditional, structured, and visualized EXPLAIN outputs. Traditional EXPLAIN can be complex and difficult to understand for complex queries. Structured EXPLAIN (with FORMAT=JSON) and visualized EXPLAIN in tools like MySQL Workbench provide more detailed and easier to understand outputs. The document also provides examples of using EXPLAIN for single table queries, index usage, range optimizations, and index merges.



































































































