




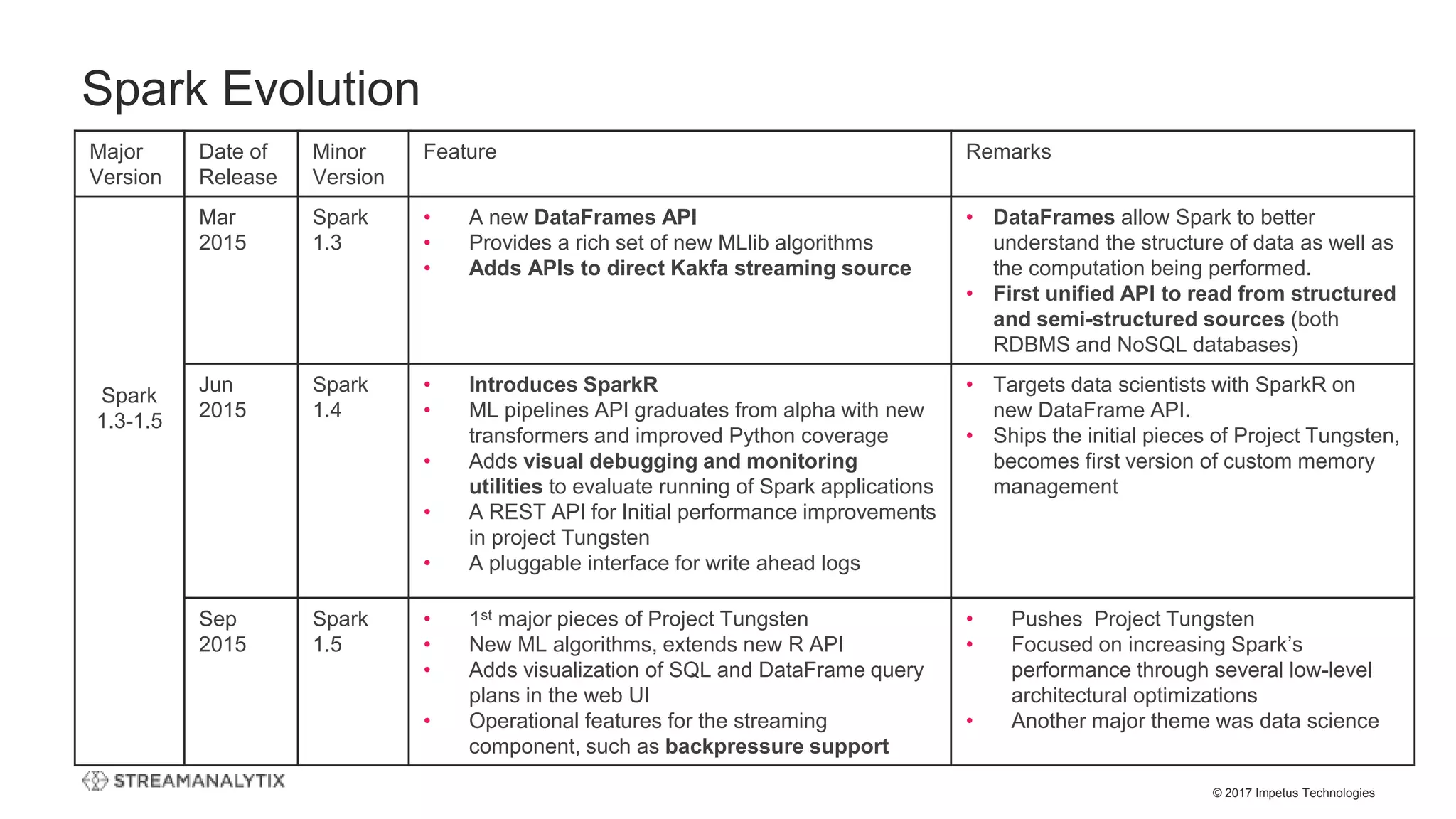


![© 2017 Impetus Technologies
Structured Streaming – Code Snippet
(Structured Streaming vs Batch)
// Structured Streaming
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
df.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.start()
//Batch
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
df.write
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.save()](https://image.slidesharecdn.com/thestructuredstreamingupgradetoapachespark-streamanalytixwebinar-171214065156/75/The-structured-streaming-upgrade-to-Apache-Spark-and-how-enterprises-can-benefit-StreamAnalytix-Webinar-17-2048.jpg)

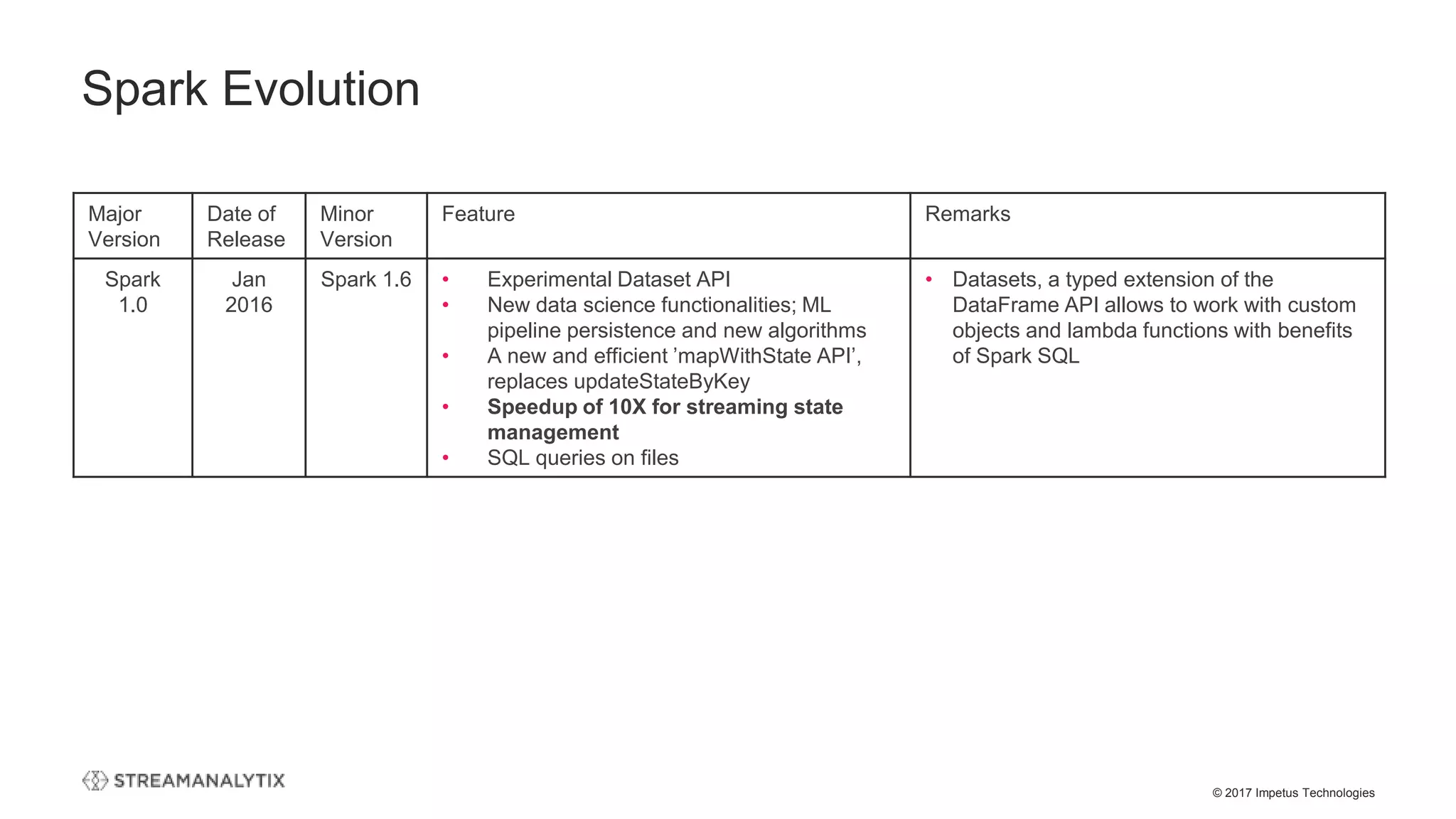
)
val stream:DStream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
stream.map(record => (record.key, record.value))
//NO Kafka Write Support
//Batch
val df = spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
df.write
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.save()](https://image.slidesharecdn.com/thestructuredstreamingupgradetoapachespark-streamanalytixwebinar-171214065156/75/The-structured-streaming-upgrade-to-Apache-Spark-and-how-enterprises-can-benefit-StreamAnalytix-Webinar-18-2048.jpg)
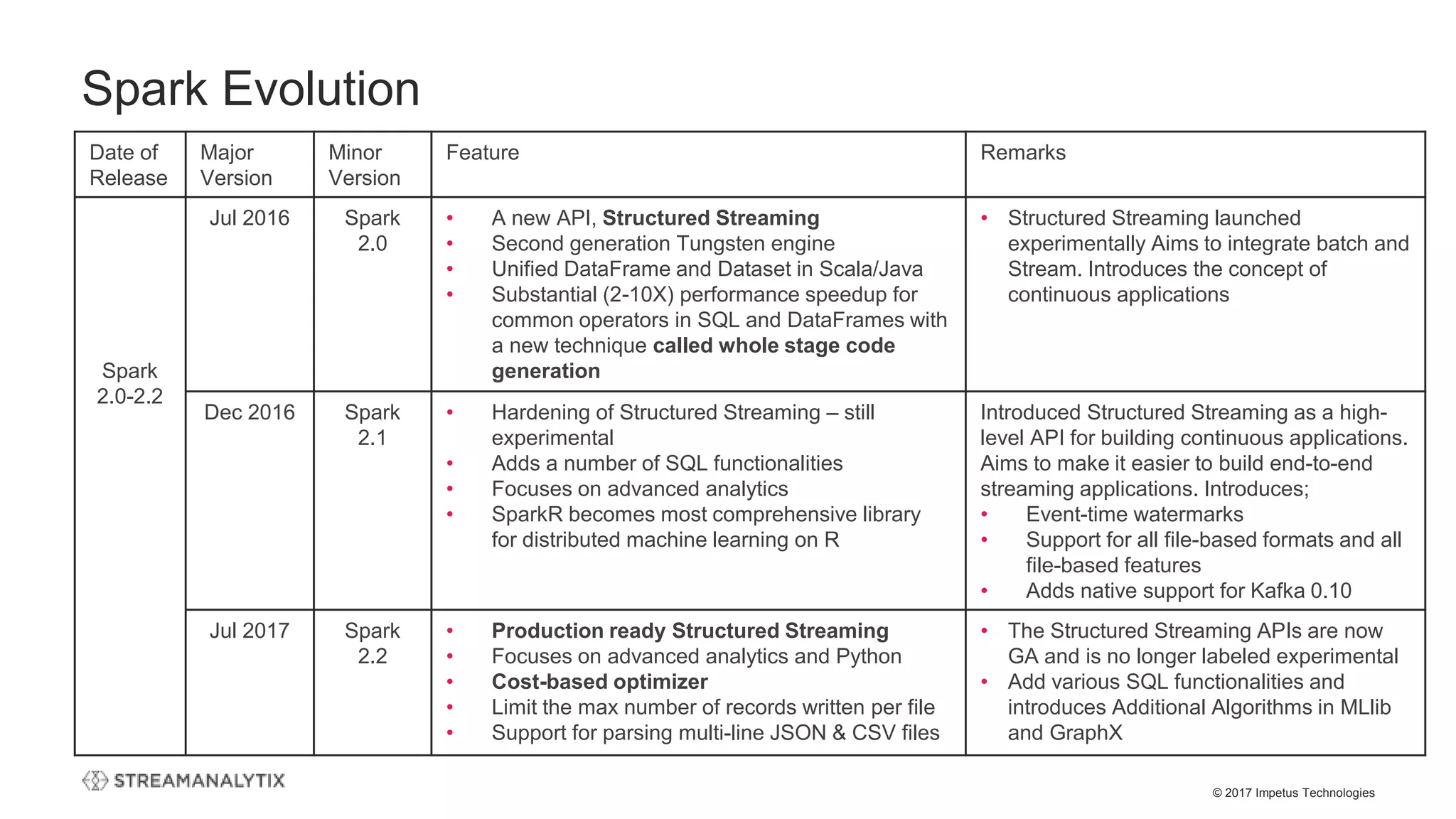
![© 2017 Impetus Technologies
Streaming Code – Executed on “Trigger”
(One Time Batch)
// Structured Streaming
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS
STRING)")
.as[(String, String)]
//One Time Trigger
df.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.trigger(Trigger.Once)
.start()
• No worry about figuring out “changed data” and output
consistency
• Much easier stateful processing like deduping
• Unified code: No different code base for Lambda
solutions
• Cost saving by not running the cluster 24/7](https://image.slidesharecdn.com/thestructuredstreamingupgradetoapachespark-streamanalytixwebinar-171214065156/75/The-structured-streaming-upgrade-to-Apache-Spark-and-how-enterprises-can-benefit-StreamAnalytix-Webinar-19-2048.jpg)




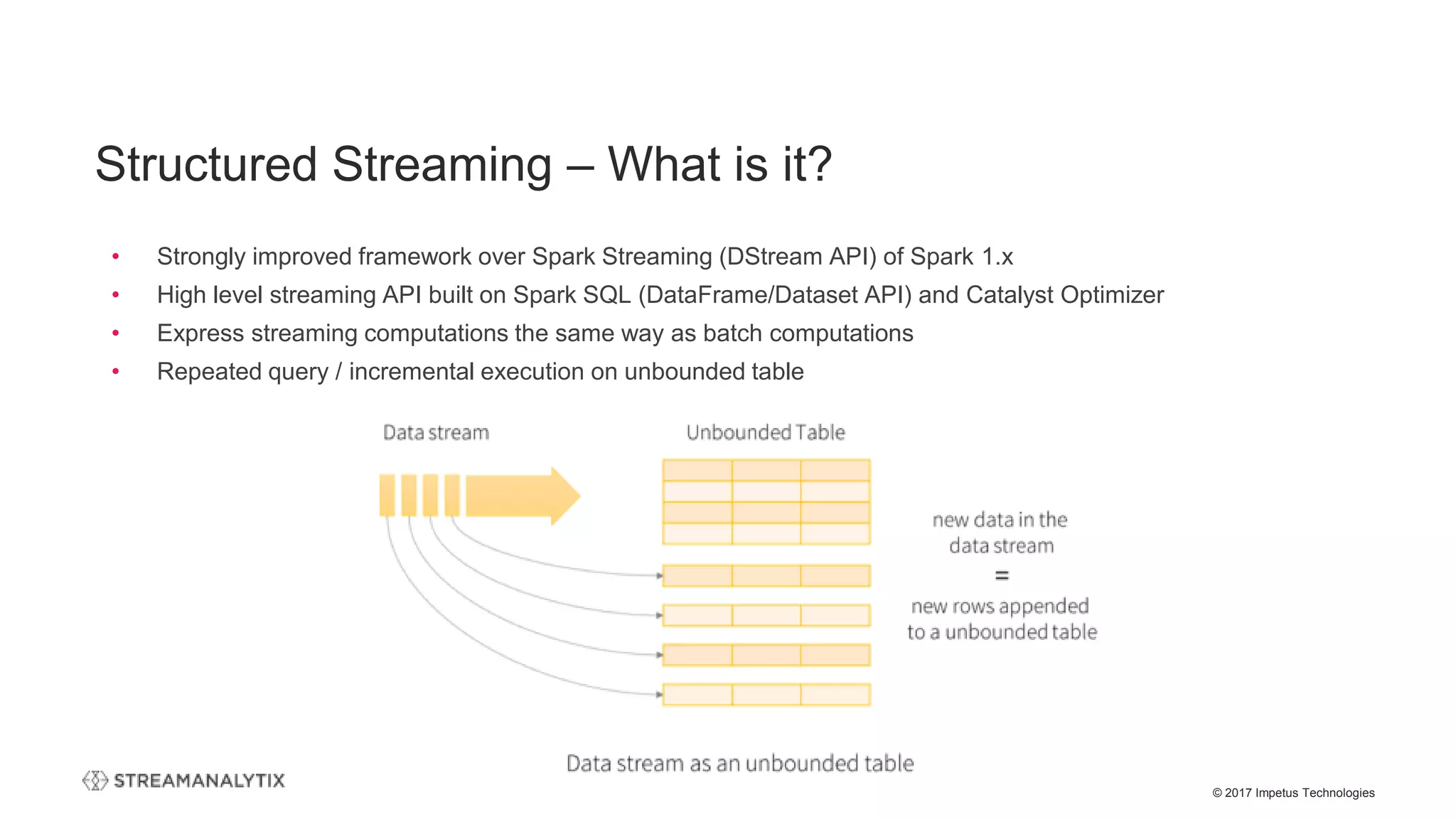
![© 2017 Impetus Technologies
• Co-existence of 1.6 and 2.x – on the same Hadoop cluster
• Forward compatibility changes
• SparkSession is now the new entry point of Spark
• Replaces the old (1.x) SQLContext and HiveContext
• Dataset API and DataFrame API are unified
• Scala: DataFrame becomes a type alias for Dataset[Row]
• Java API users must replace DataFrame with Dataset<Row>
Spark Version Management Considerations
(Migration, Co-existence)](https://image.slidesharecdn.com/thestructuredstreamingupgradetoapachespark-streamanalytixwebinar-171214065156/75/The-structured-streaming-upgrade-to-Apache-Spark-and-how-enterprises-can-benefit-StreamAnalytix-Webinar-27-2048.jpg)





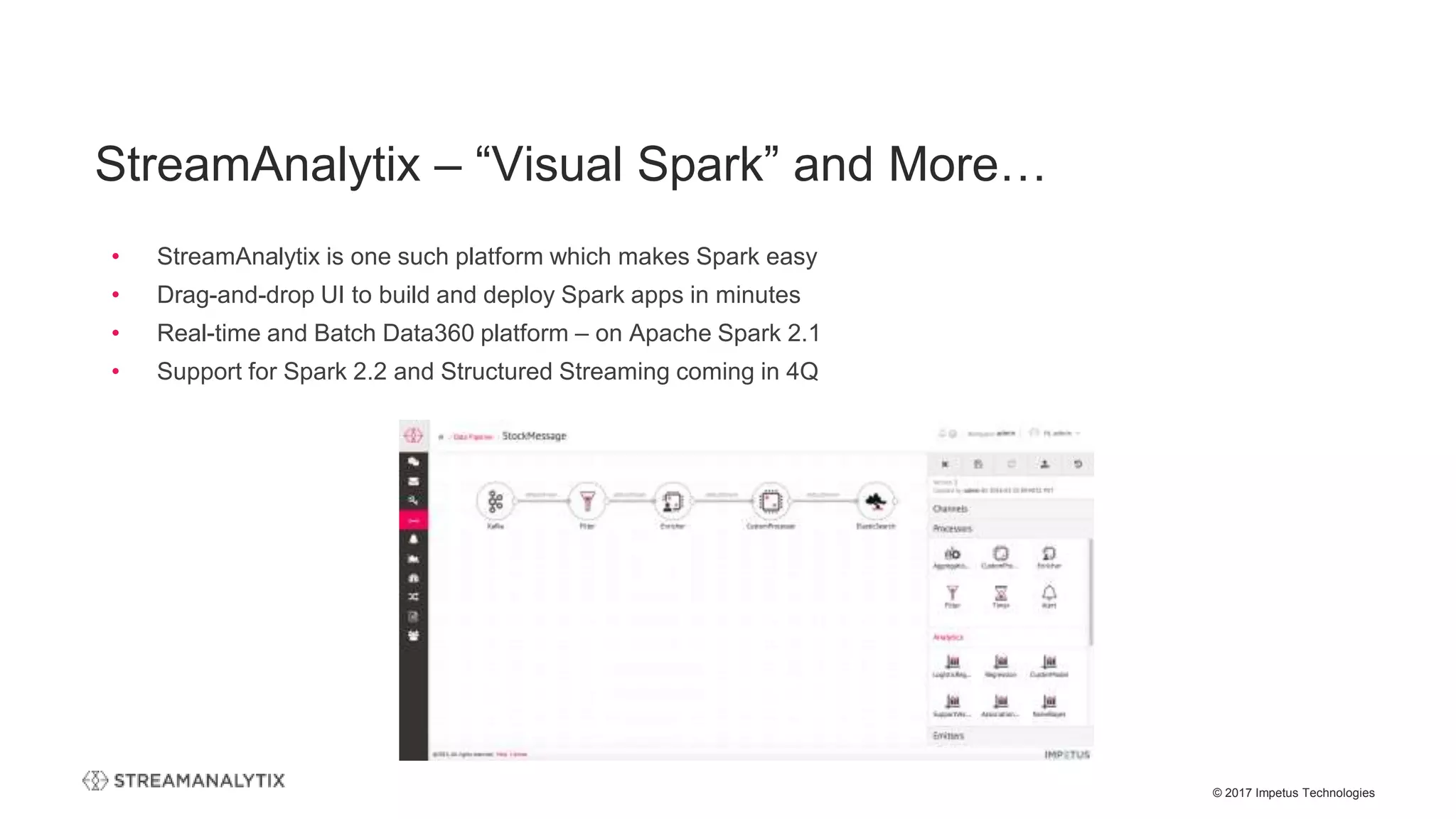



The webinar presented by Impetus Technologies focuses on the structured streaming upgrade to Apache Spark, detailing its evolution, features, and benefits for enterprises. It includes discussions on the technical highlights of structured streaming, its ability to simplify real-time analytics, and the importance of talent and tooling in Spark projects. The session emphasizes StreamAnalytix as a platform designed to enhance the user experience by making Spark easier to deploy.




















































































