Download to read offline

![iteration, requiring lots of disk accesses,
I/Os and unnecessary computations. On
the other hand, Spark offers better
execution time by caching intermediate
data in-memory for iterative operations.
Most ML algorithms run on the same data
set iteratively. In MapReduce, there was
no easy way to communicate shared
states and data from iterations to
iterations. Spark is designed to overcome
the shortages of MapReduce in iterative
operations. Through the use of the data
structure called Resilient distributed
datasets (RDDs), Spark can effectively
improve the performance of the iterative
jobs with low latency requirements.
In this project, we attempted to conduct
exhaustive experiments to evaluate the
system performance between Hadoop
MapReduce and Spark. We considered the
execution time as the performance matric.
We choose a typical iterative algorithm
"PageRank" to run for some real data sets
on both of the frameworks.
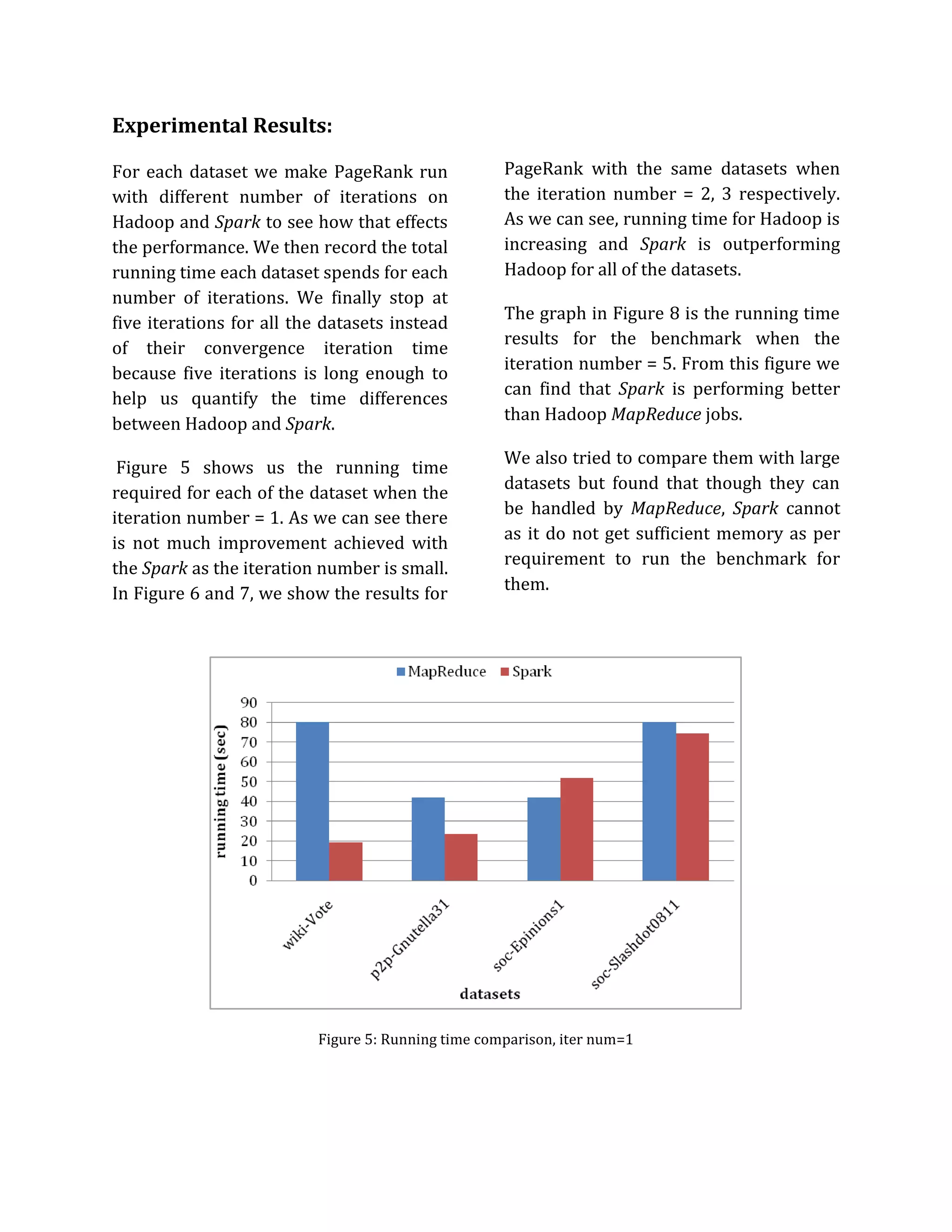
Experimental Environment:
I. Cluster Architecture
The experimental cluster is composed of
six computers. One of them is designated
as master, and the other five as slaves. We
use the operating system Ubuntu 12.04.2
(GNU/Linux 3.5.0-28-generic x86 64) for
all the computers.
Table 1 shows the hostname, machine
modal, IP address, CPU and memory
information of the computers. We use
Hadoop 1.2.1 and Spark 1.1.0 for all the
experiments. Figure 1 shows the overall
testbed architecture of our system.
II. Dataset Description
We choose four real graph datasets to do
comparative experiments. Table 2 lists
these graph datasets. They are all in the
format of edge list, each line in the file is a
[src ID] [target ID] pair separated by
whitespace. These real graph datasets
come from SNAP.
Figure 1: Testbed Architecture
Implementation:
I. Benchmark: PageRank
PageRank is an algorithm used by Google
Search to rank websites in their search
engine results. PageRank was named after
Larry Page, one of the founders of Google.
It is a way of measuring the importance of
website pages. It works by counting the
number and quality of links to a page to
determine a rough estimate of how
important the website is. The underlying
assumption is that more important
websites are likely to receive more links
from other websites.
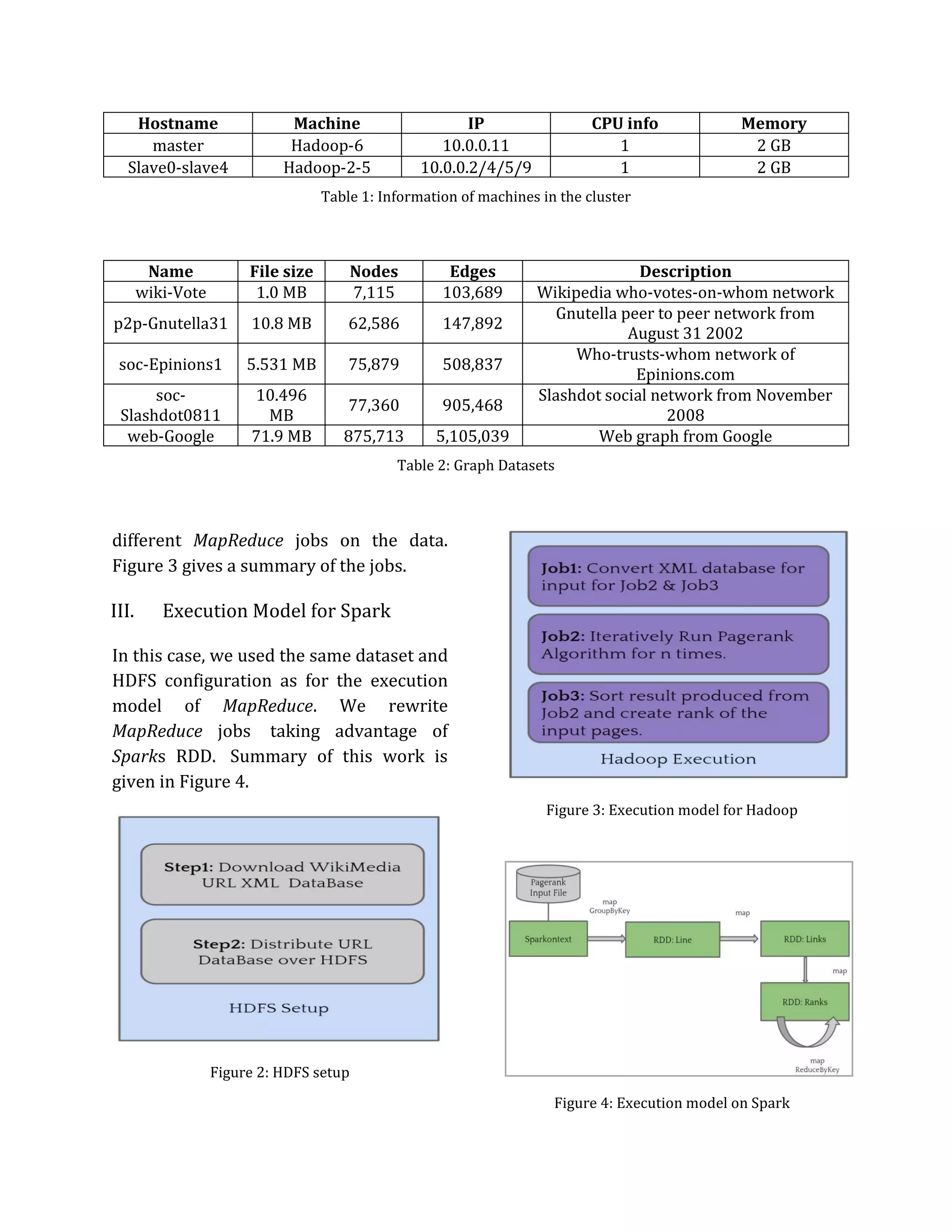
II. Execution Model for MapReduce
In Figure 2 we can see the steps for
setting up the HDFS for out input
datasets. In the execution model for
MapReduce, given input files for page
ranking algorithm, we distribute the data
over the hadoop cluster and run three](https://image.slidesharecdn.com/group4-project-report-161208183551/75/Big-Data-Processing-Performance-Gain-Through-In-Memory-Computation-2-2048.jpg)
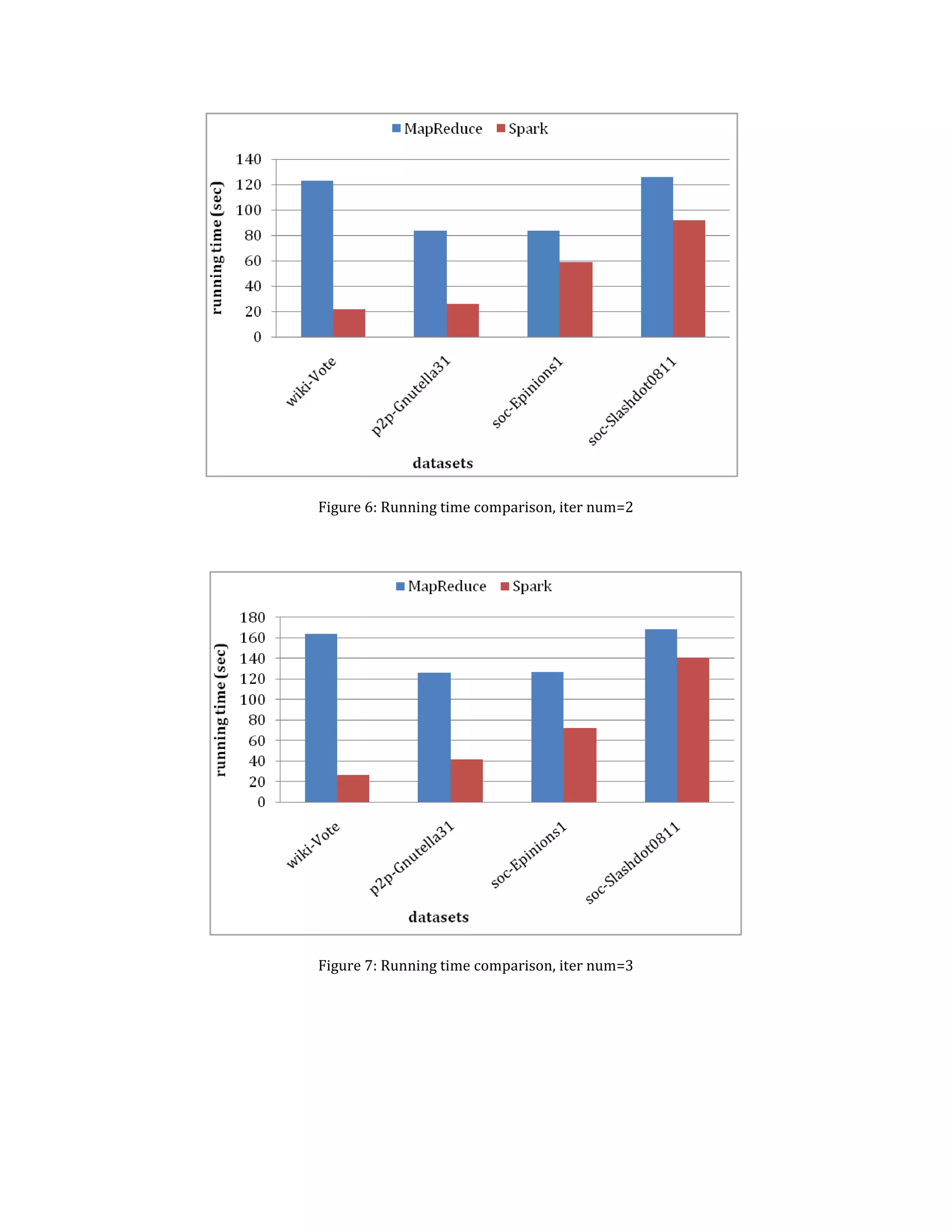
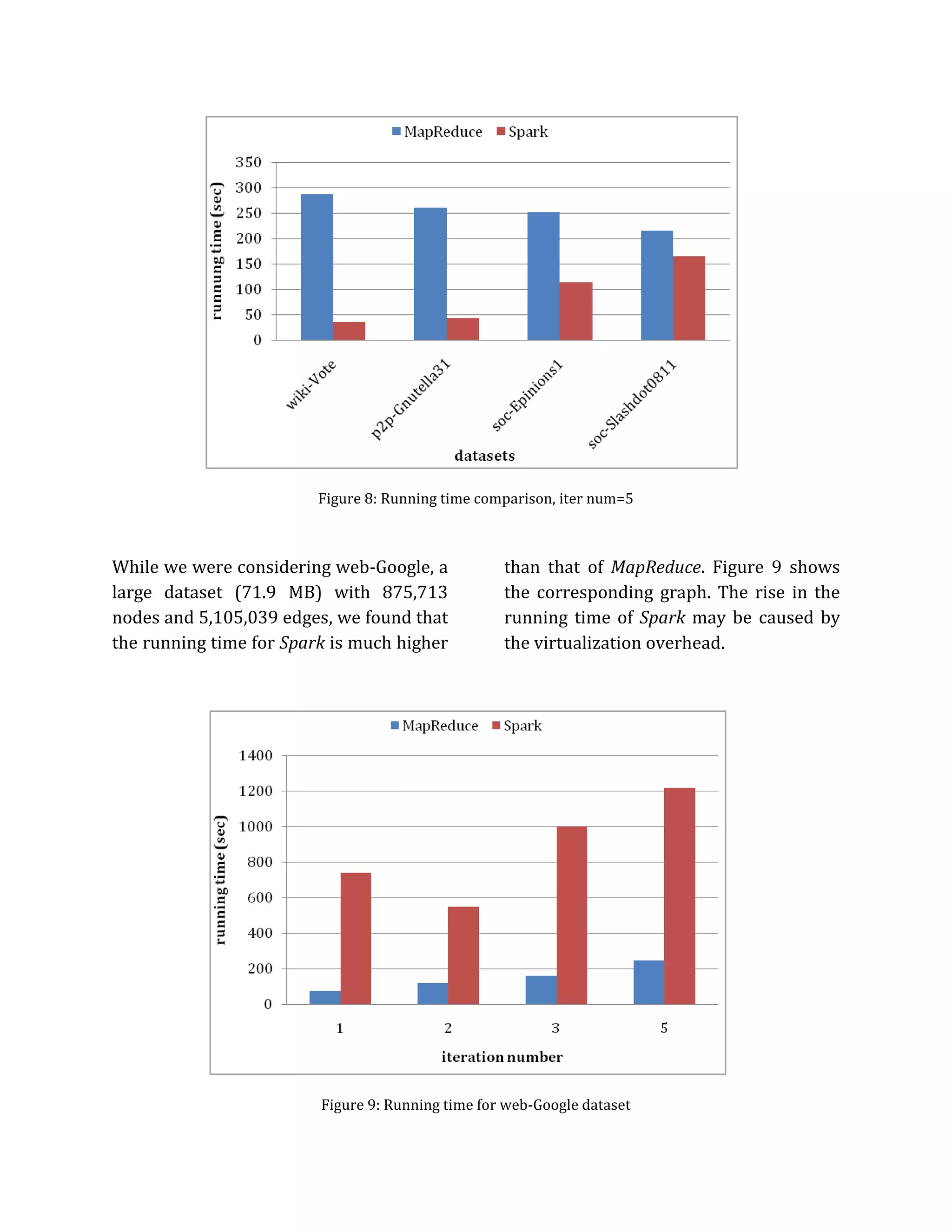

![The above two figures (Figure 10 and 11)
shows the typical output consoles for the
Spark runs. Figure 10 shows the output of
a successful run with the total running
time required.
In Figure 11, we can see the "not enough
space to cache partition rdd_x_y in
memory" error for cit-Patents, a larger
dataset (267.5 MB) with 3,774,768 nodes
and 16,518,948 edges. This means that
with our existing cluster configuration
and insufficient memory, Spark cannot
carry out PageRank benchmark with a
bigger dataset.
Conclusion:
In this project, we worked with Hadoop
MapReduce and Spark to compare the
performance gain in terms of running
time and memory consumption. We found
that, though for small datasets Spark
performs better, for large datasets
MapReduce is much efficient even with
insufficient memory. Spark needs enough
memory for the correct execution of the
benchmark. Without that it can take
longer time and even crash.
If speed is not a demanding requirement
and we do not have abundant memory,
we should not choose Spark. As long as
we have enough disk space to
accommodate the original dataset and
intermediate results, Hadoop MapReduce
is a good choice.
References:
[1] M. Zaharia, M. Chowdhury, S. S. Michael J.
Franklin, and I. Stoica, “Spark: Cluster computing
with working sets,” In HotCloud, June 2010.
[2] Lei Gu, Huan Li, “Memory or Time:
Performance Evaluation for Iterative Operation on
Hadoop and Spark” In 2013 IEEE International
Conference on High Performance Computing and
Communications & 2013 IEEE International
Conference on Embedded and Ubiquitous
Computing, 2013.
[3] SNAP url: http://snap.stanford.edu/data/
[4] hortonworks.com/hadoop-tutorial/using-
commandline-manage-files-hdfs/
[5]stackoverflow.com/questions/24167194/why-
is-the-spark-task-running-on-a-single-node](https://image.slidesharecdn.com/group4-project-report-161208183551/75/Big-Data-Processing-Performance-Gain-Through-In-Memory-Computation-8-2048.jpg)

The document reports on a project comparing the performance of Hadoop MapReduce and Spark in-memory frameworks for big data processing. The authors analyzed execution times for running a PageRank benchmark on various datasets using each framework. They found that Spark performed better for smaller datasets with multiple iterations due to its in-memory caching. However, for larger datasets MapReduce was more efficient due to Spark's memory requirements not being met by the cluster configuration.























































































