Download to read offline






![Programming fine-grained locks is hard
...
case ST7:
locksToAcquire.add(documentWriteLock);
break;
case Q6:
locksToAcquire.add(assemblyReadLocks[BASE_ASSEMBLY_LEVEL]);
locksToAcquire.add(compositePartReadLock);
for (int level = Parameters.NumAssmLevels; level > 1; level--)
locksToAcquire.add(assemblyReadLocks[level]);
break;
case ST4:
locksToAcquire.add(assemblyReadLocks[BASE_ASSEMBLY_LEVEL]);
locksToAcquire.add(documentReadLock);
break;
...
Medium-grained lock in STMBench7](https://image.slidesharecdn.com/phd-opt-mem-trx-v14-151105150353-lva1-app6891/75/opt-mem-trx-8-2048.jpg)

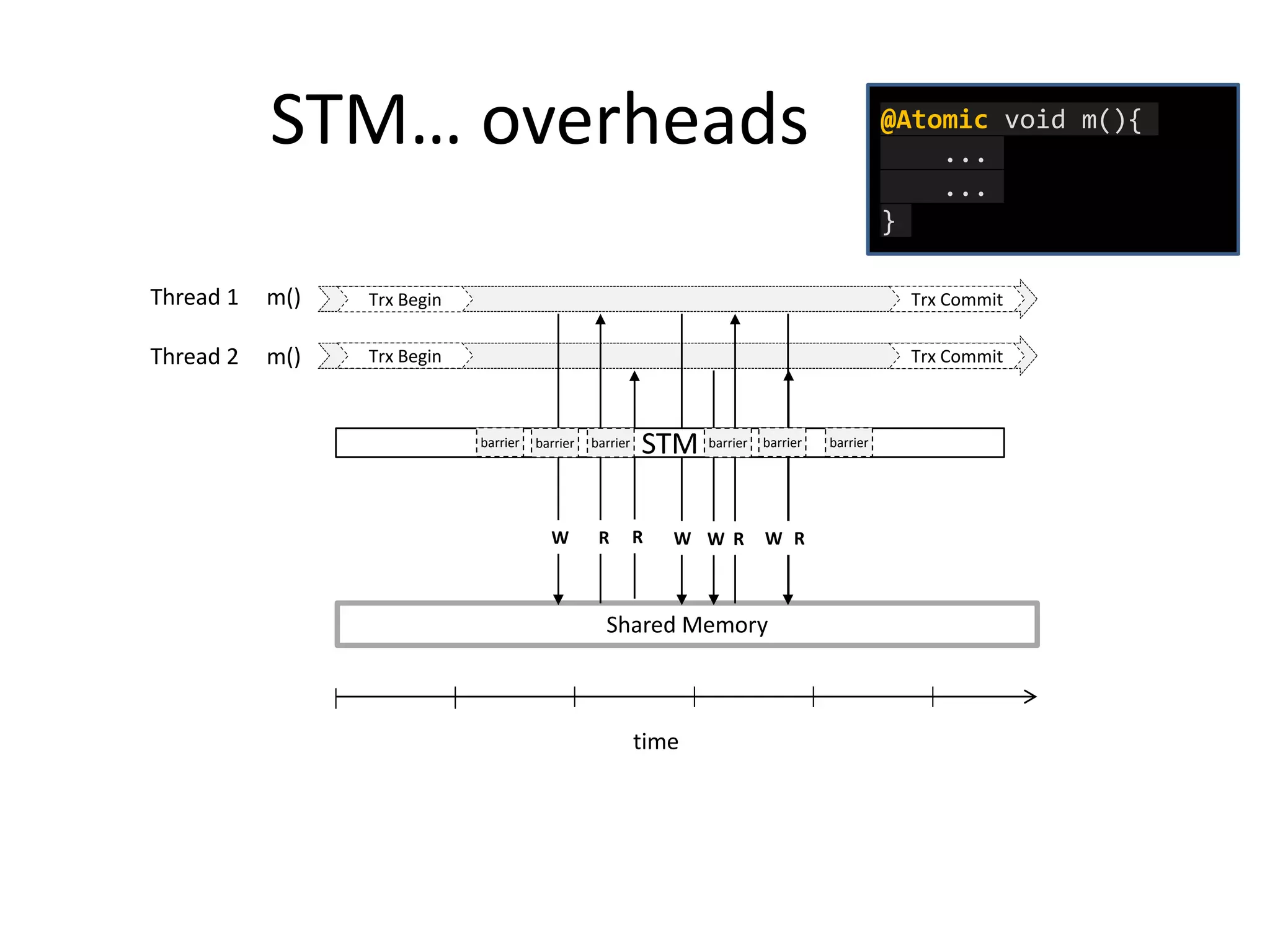
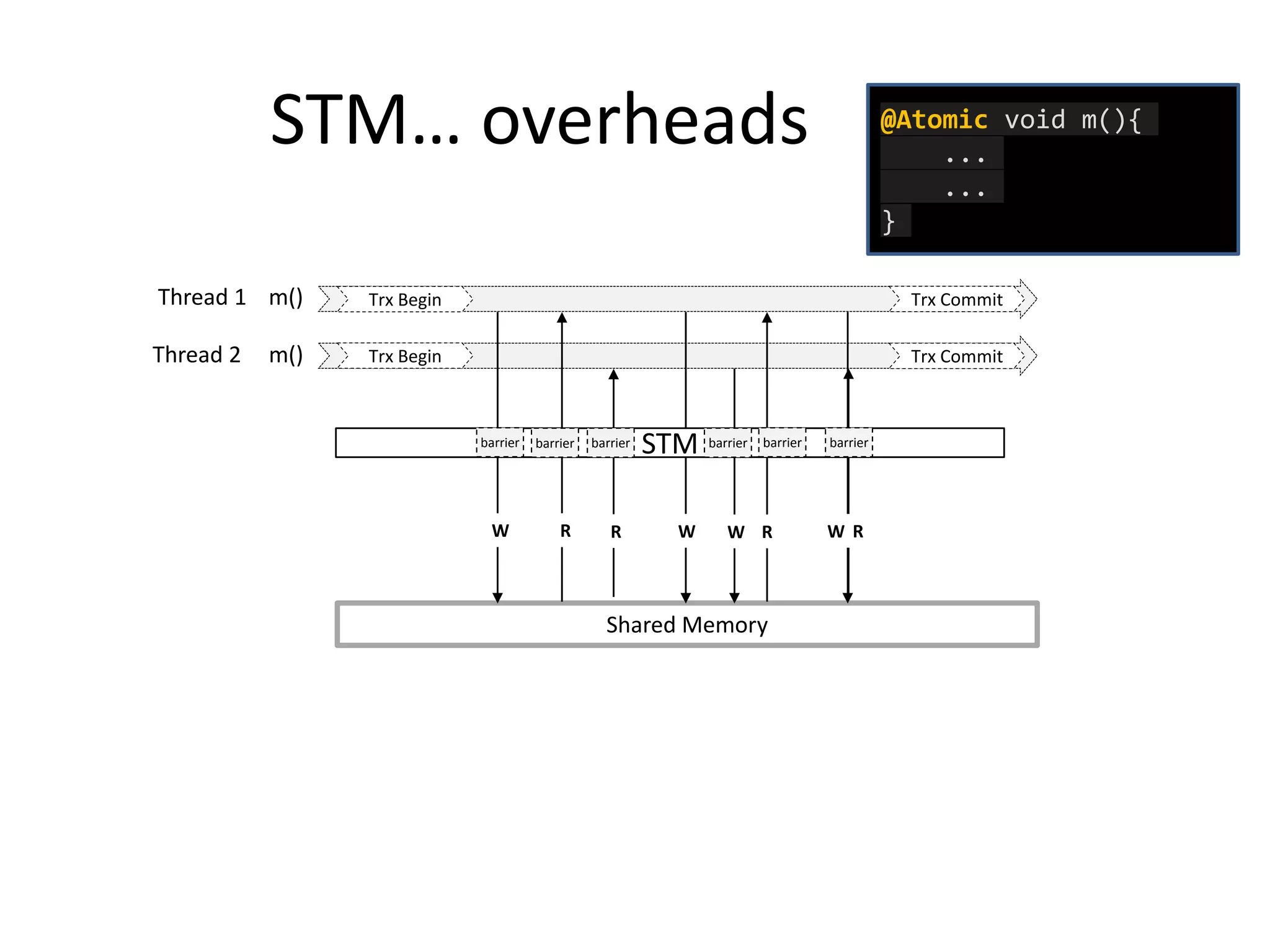
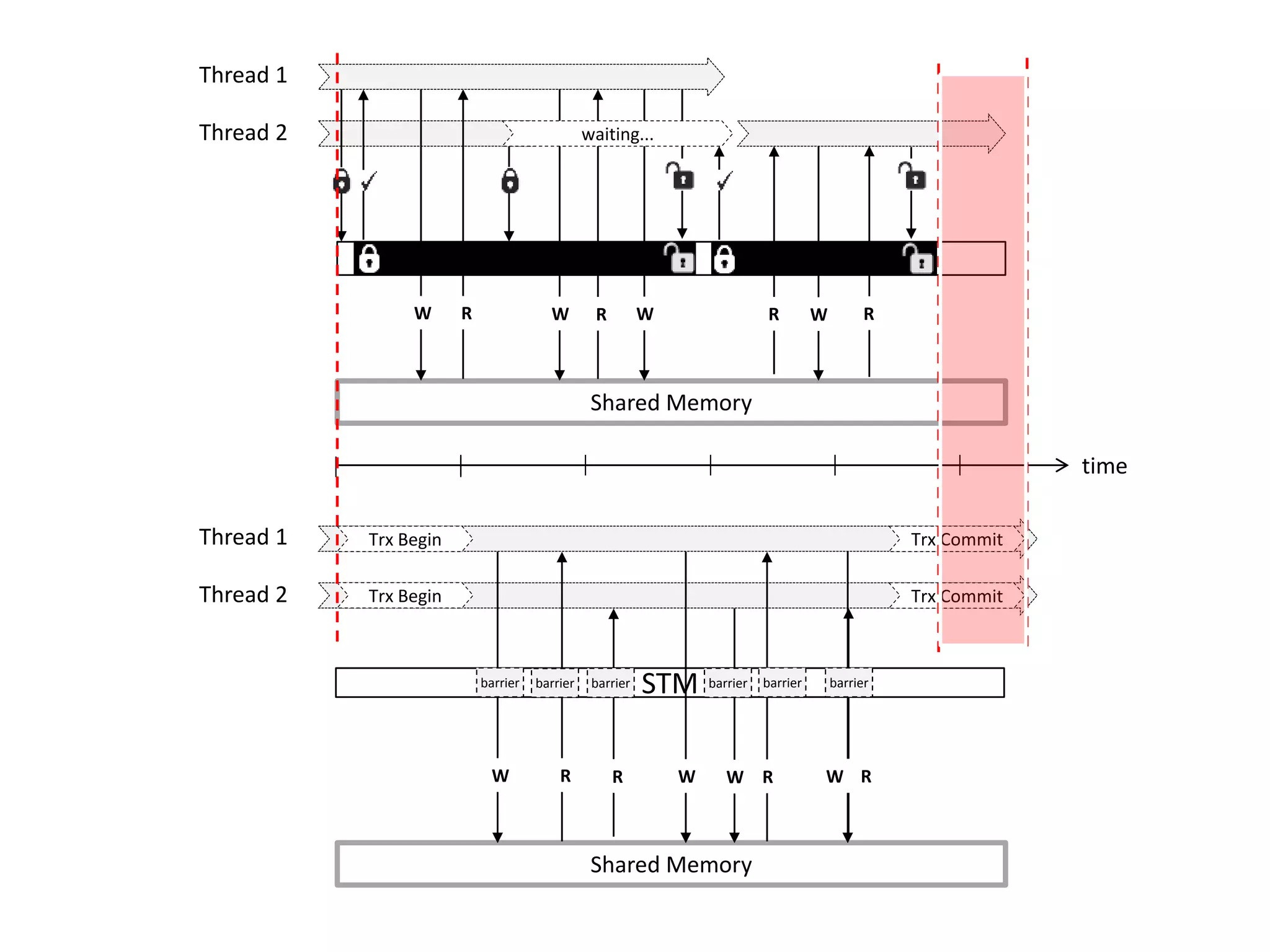
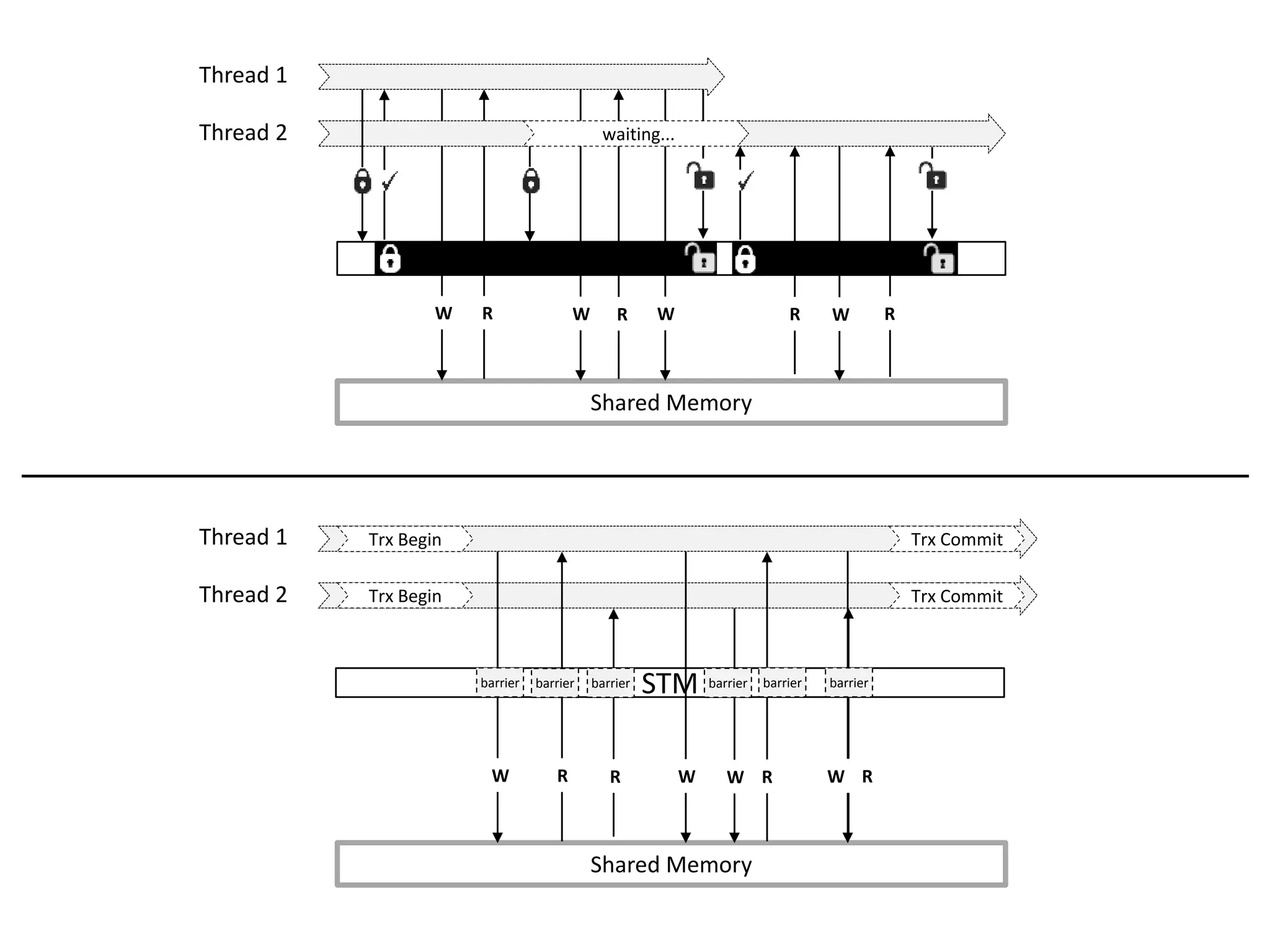
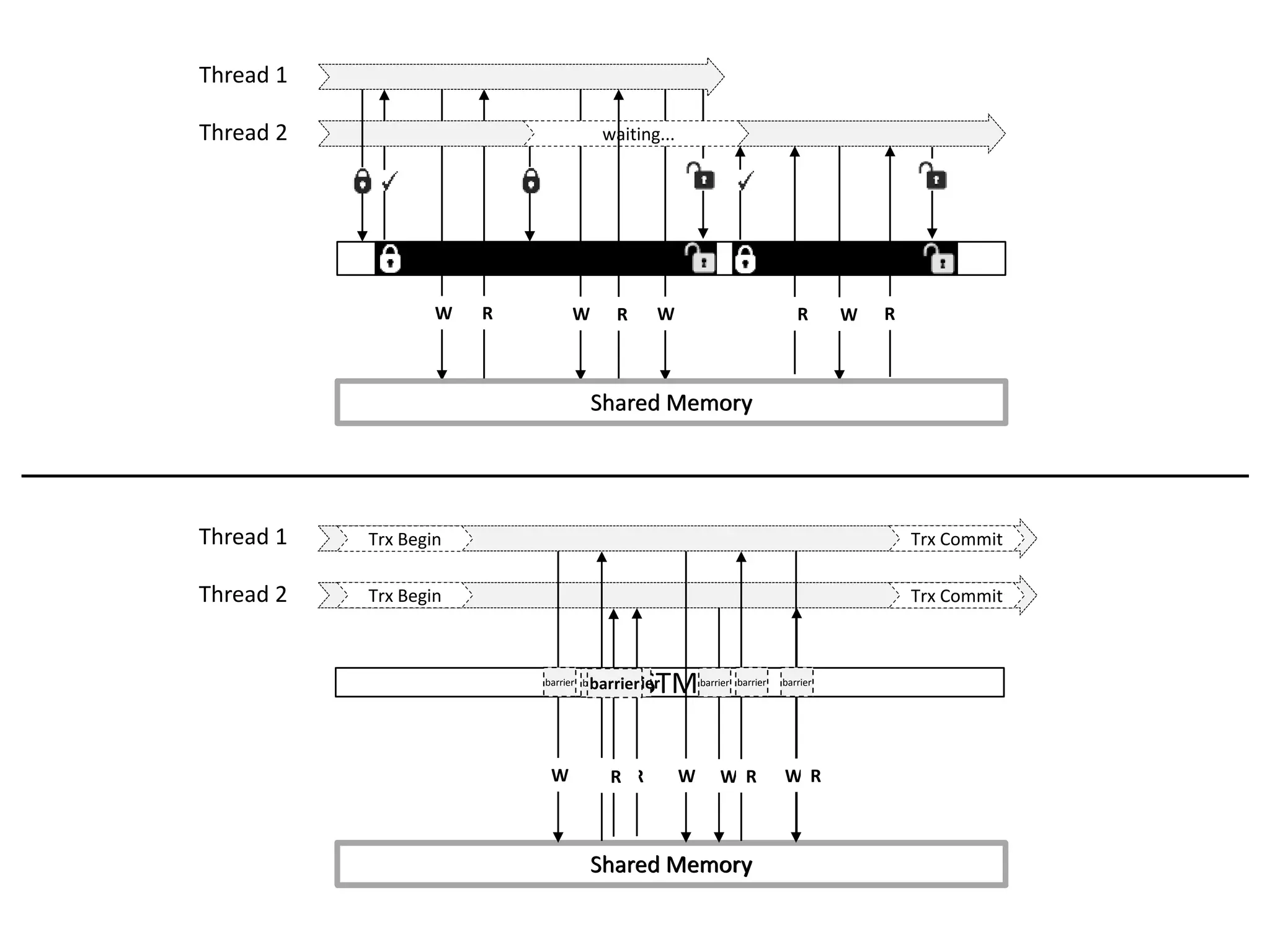
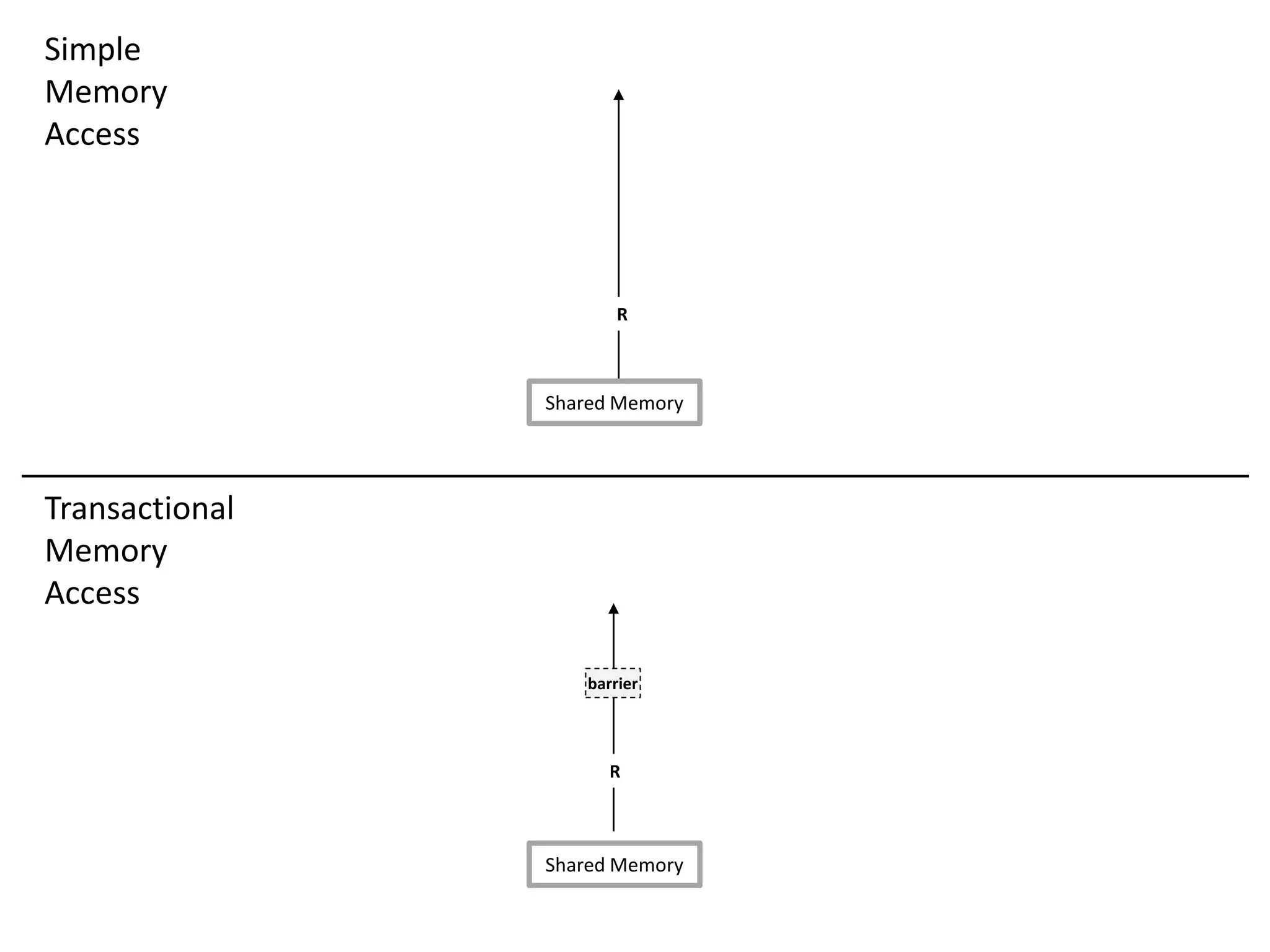
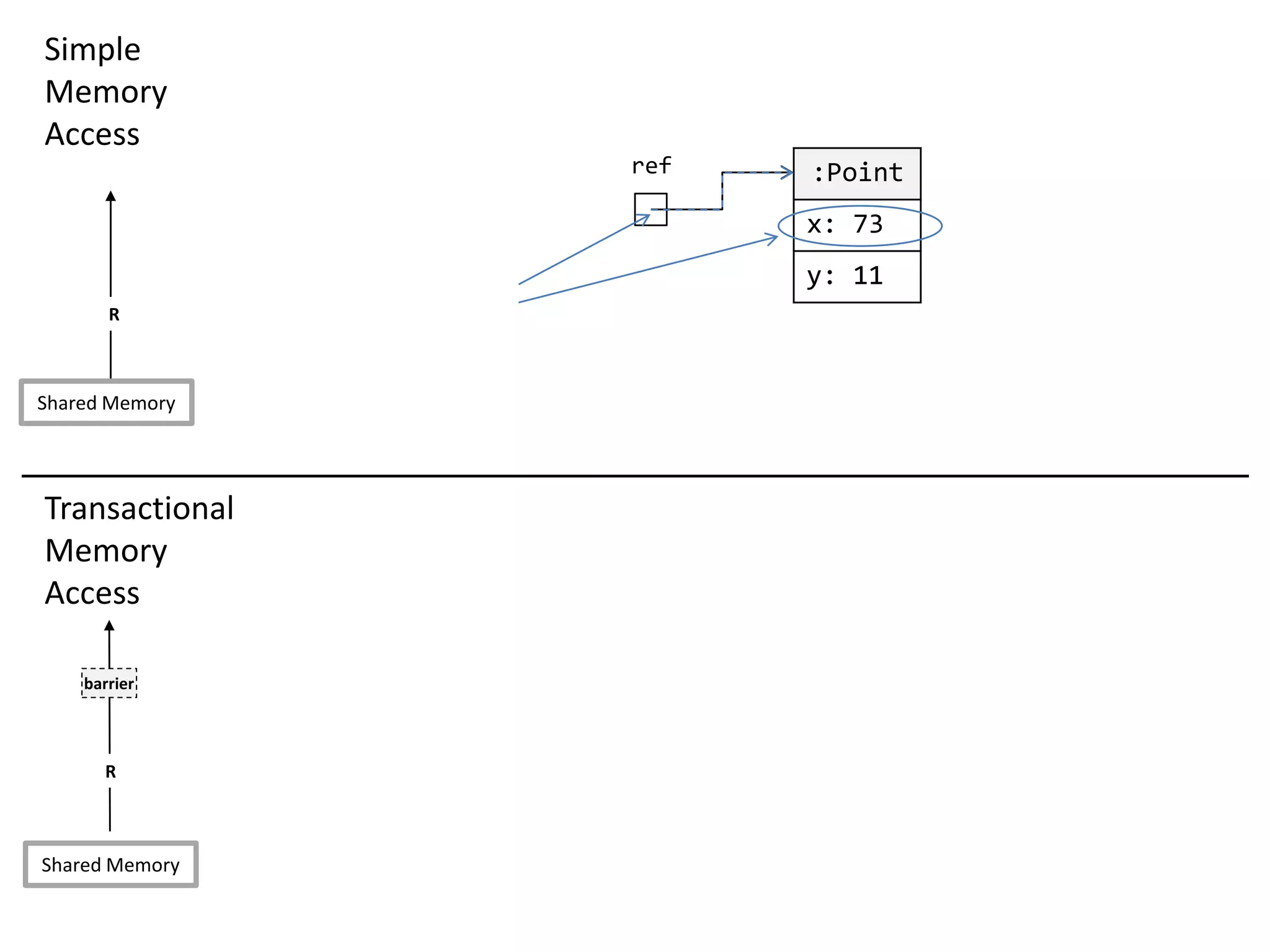
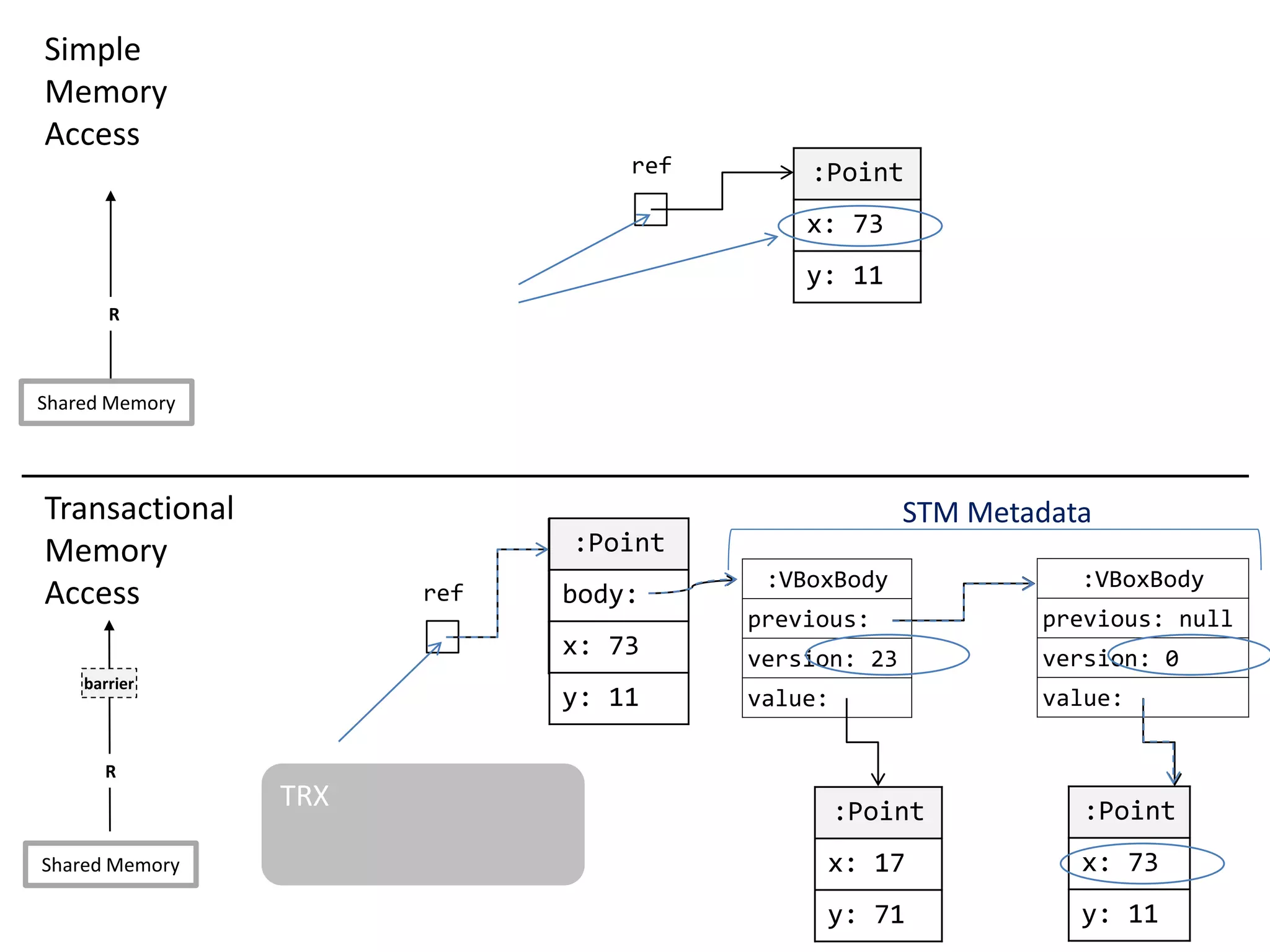









![Transparent STM API
public class Worm implements IWorm {
final int id;
final int headSize;
final int speed;
final BodyCoord[] body;
public void moveBody(ICoordinate newCoordinate) {
for(BodyCoord c: body) {
...
c.update(newCoordinate);
...
}
}
}
STM barrier
STM barrier
STM barrier
STM barrier](https://image.slidesharecdn.com/phd-opt-mem-trx-v14-151105150353-lva1-app6891/75/opt-mem-trx-40-2048.jpg)







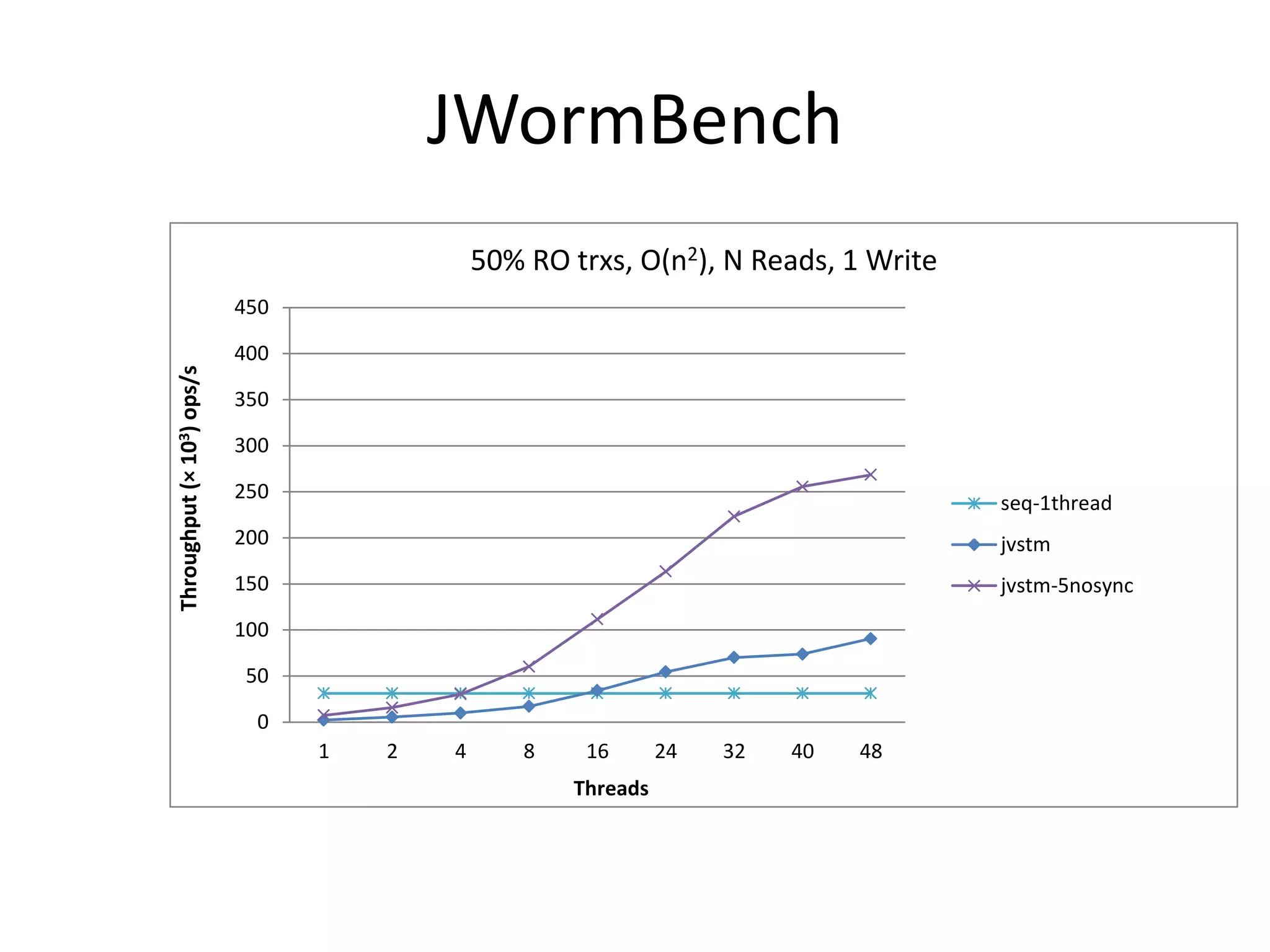
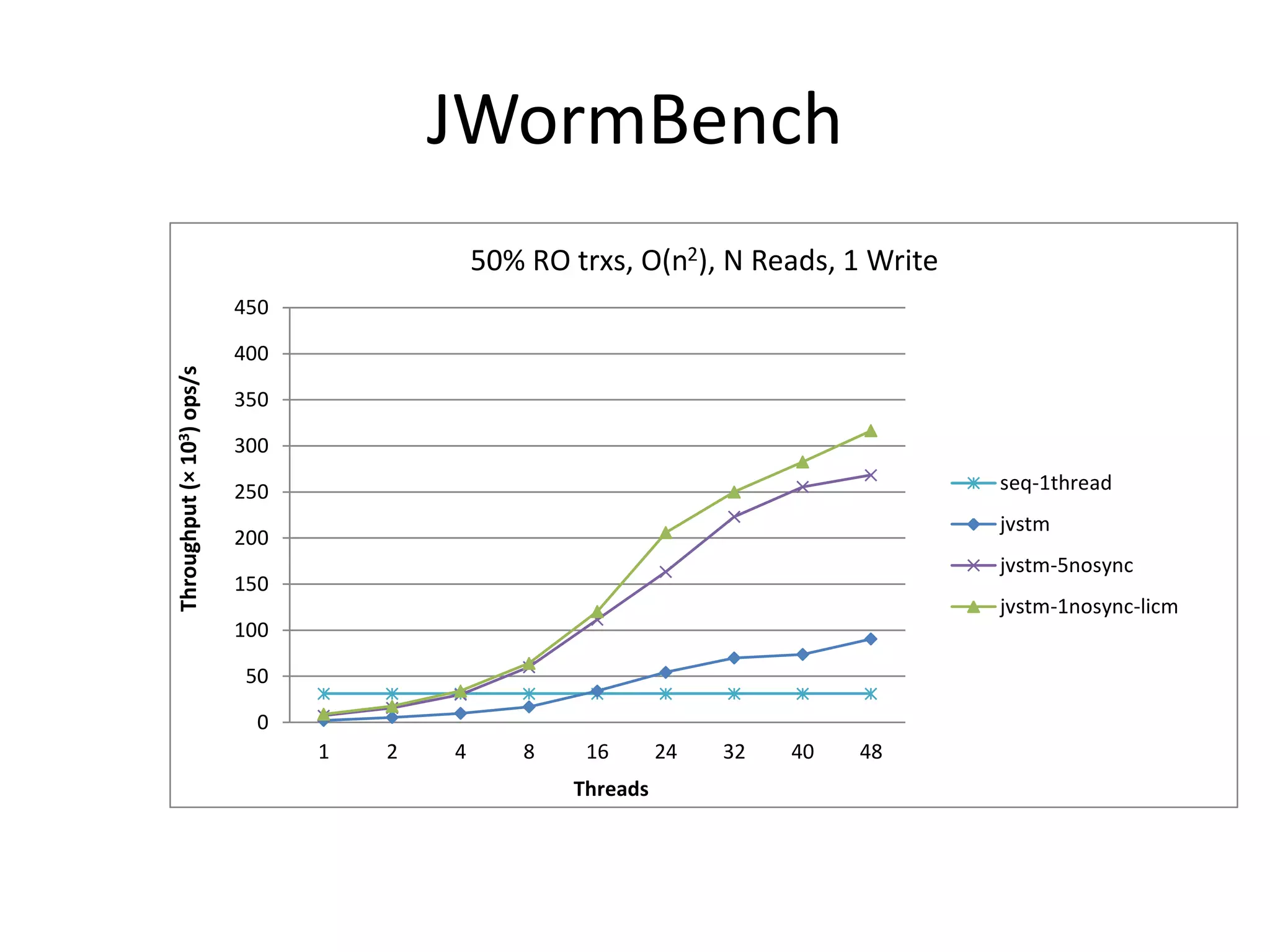



![Vacation
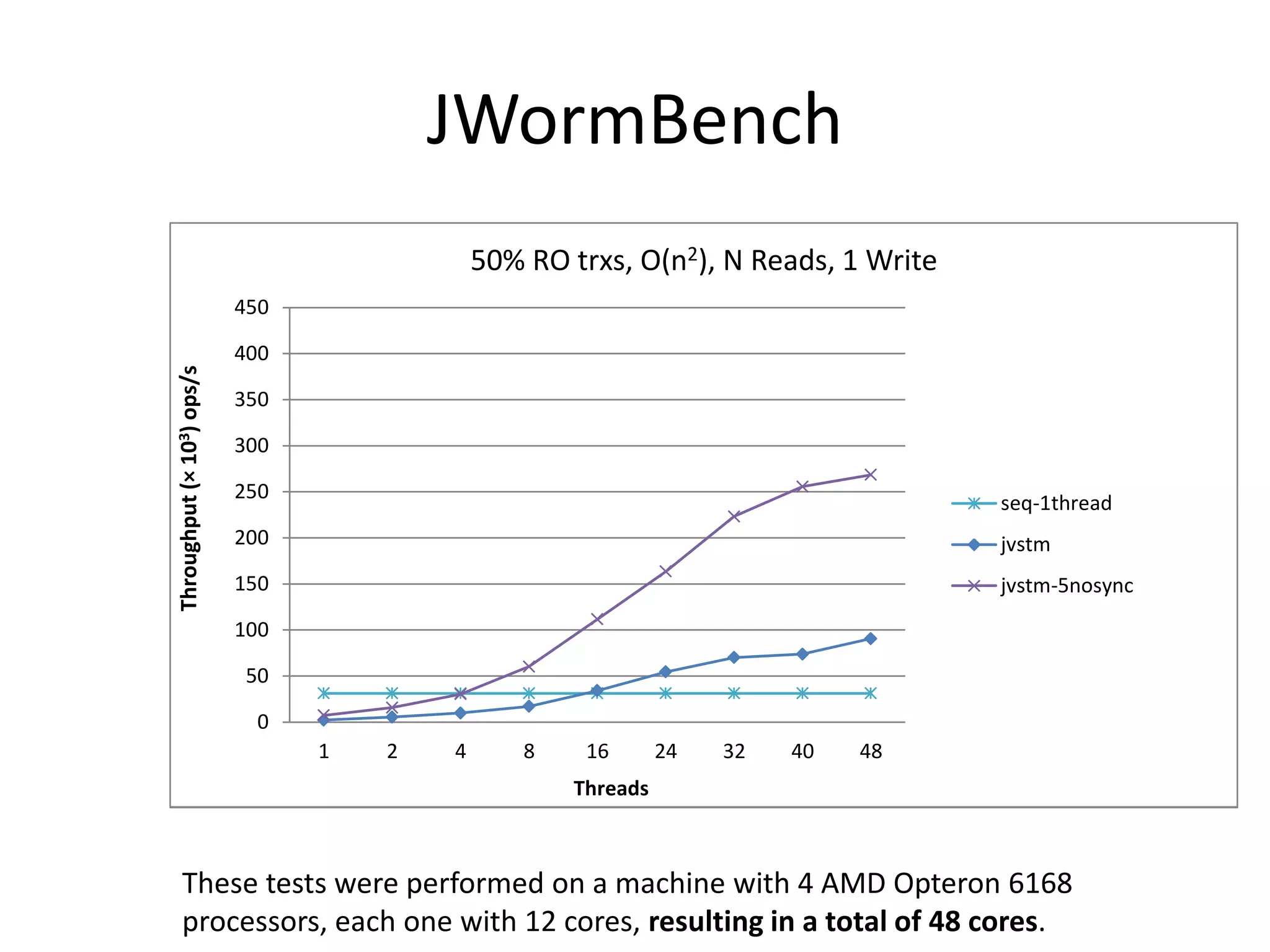
These tests were performed with the following configuration:
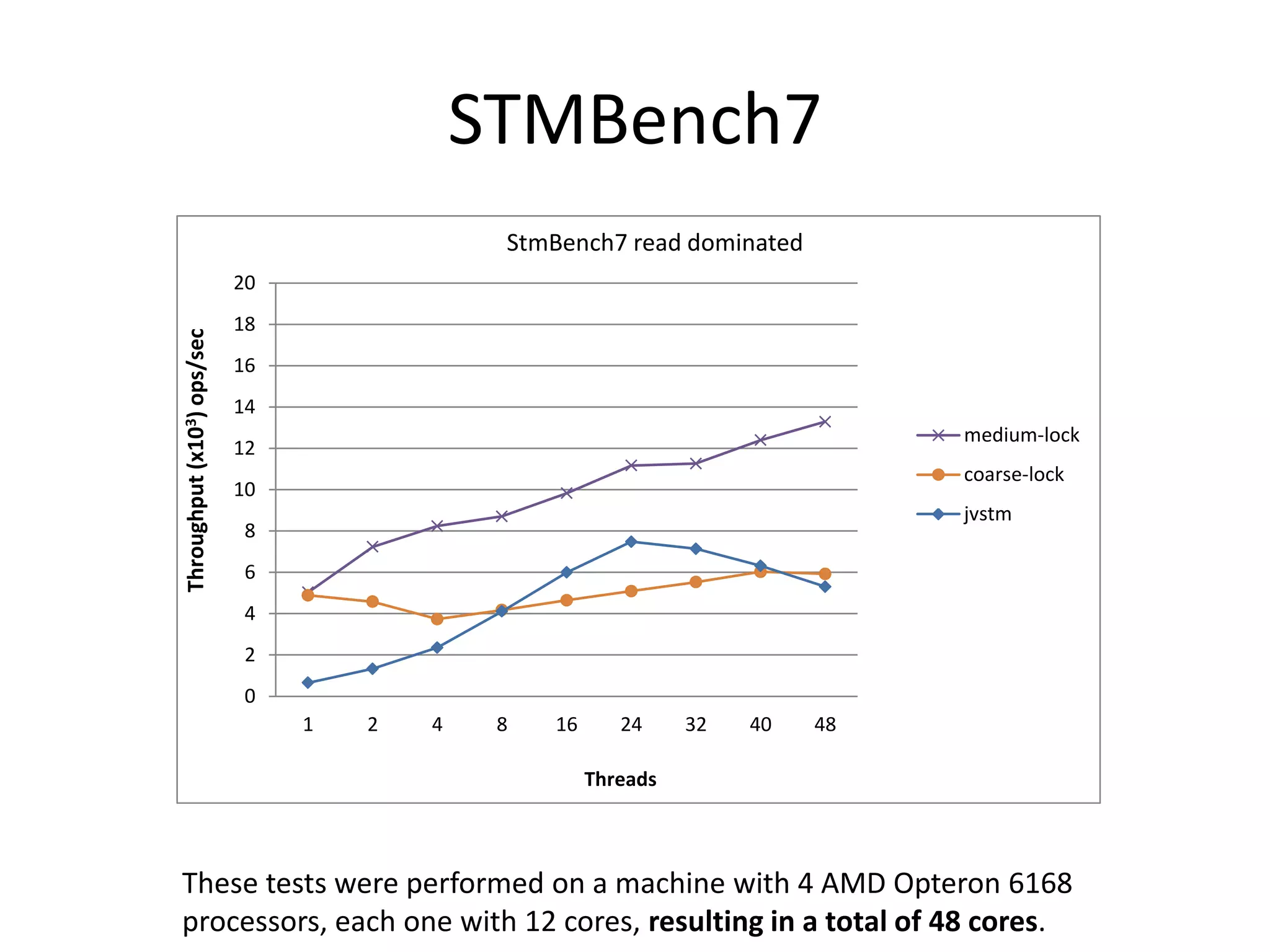
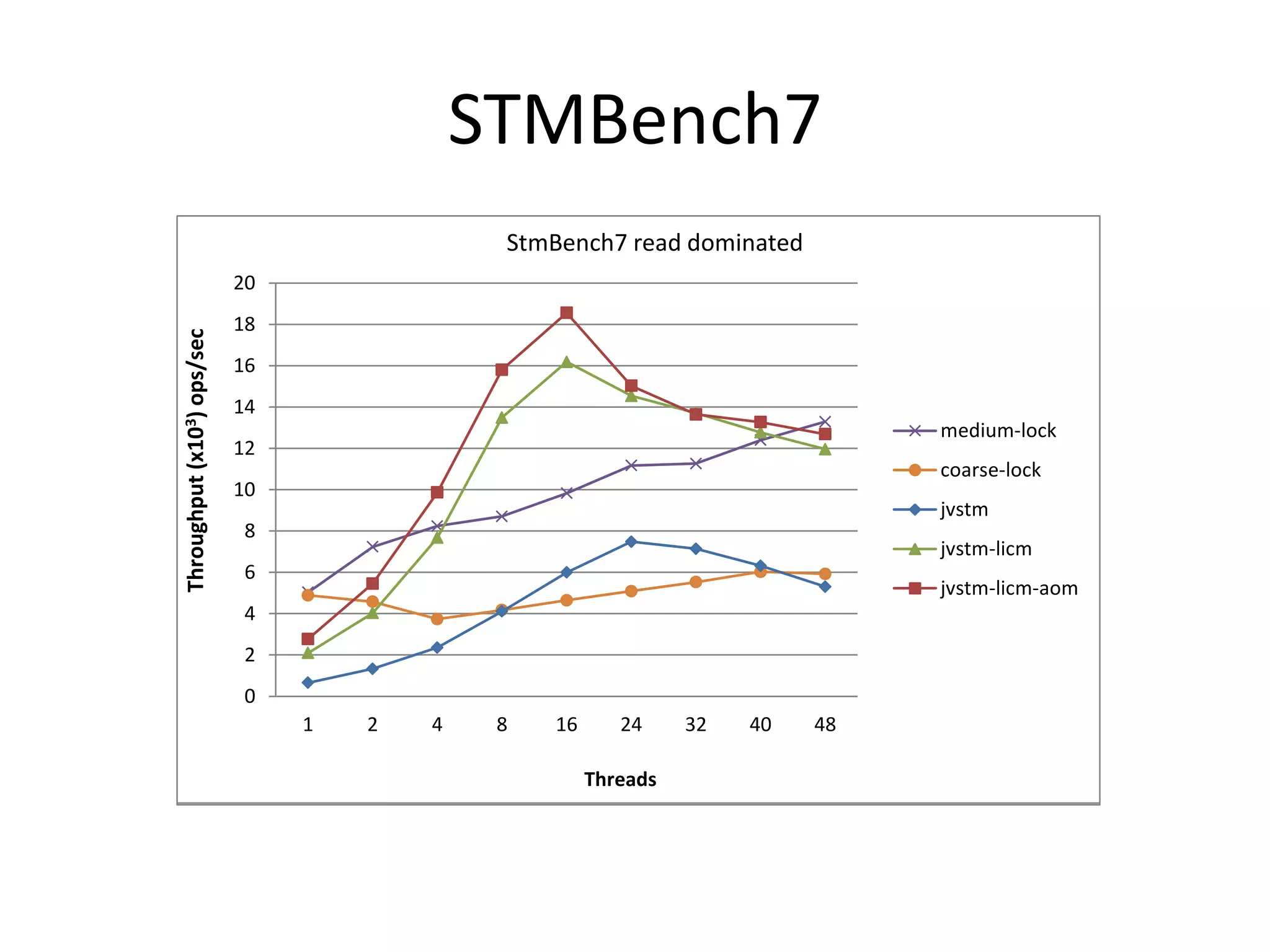
-n 256 -q 90 -u 98 -r 262144 -t 65536, proposed by [Cao Minh et al. , 2008]
0
5
10
15
20
25
1 2 4 8 16 24 32 40 48
Throughput(x103)ops/sec
Threads
Vacation low contention
tl2
tl2-licm
jvstm
jvstm-licm-aom](https://image.slidesharecdn.com/phd-opt-mem-trx-v14-151105150353-lva1-app6891/75/opt-mem-trx-77-2048.jpg)

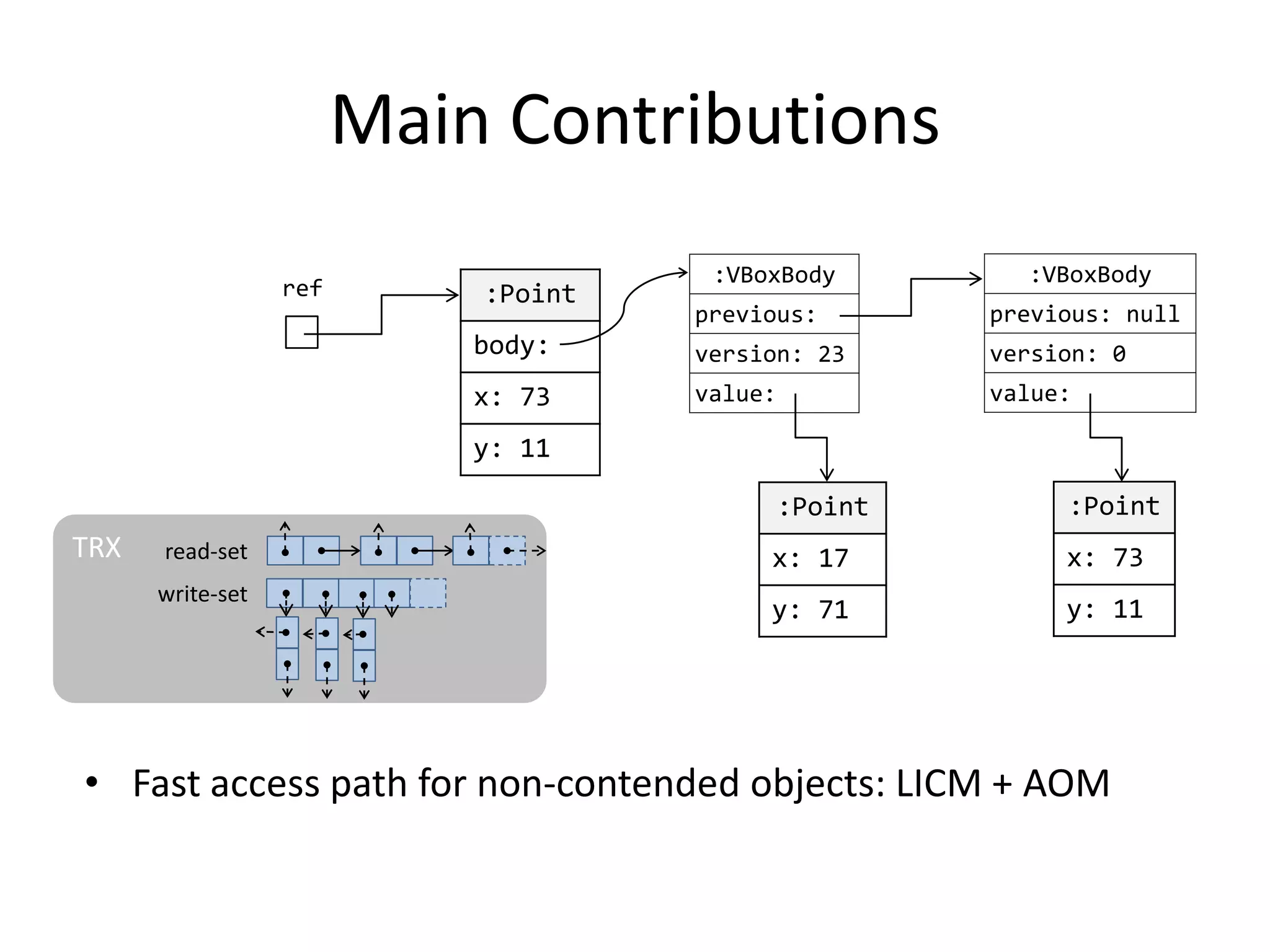
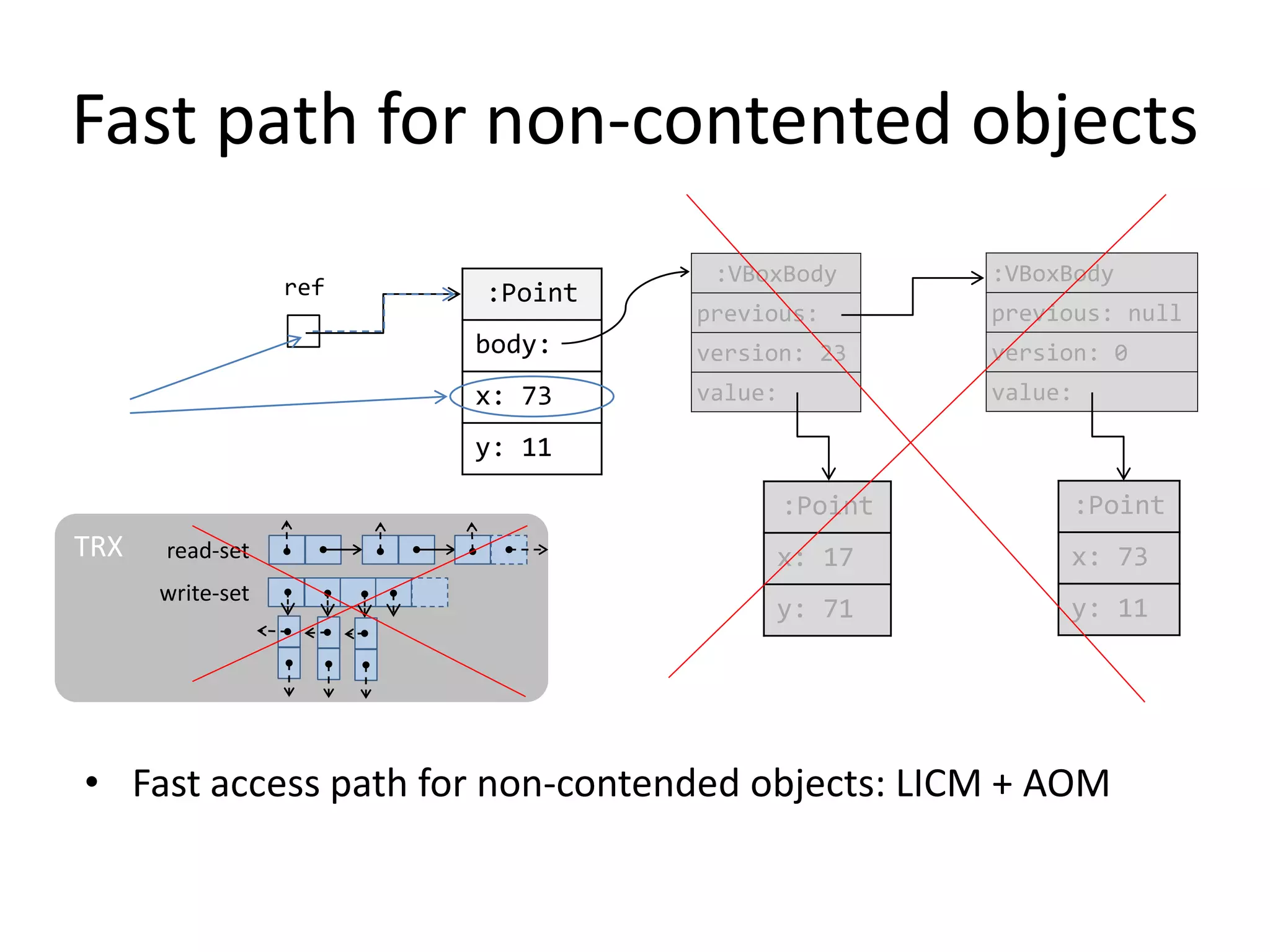


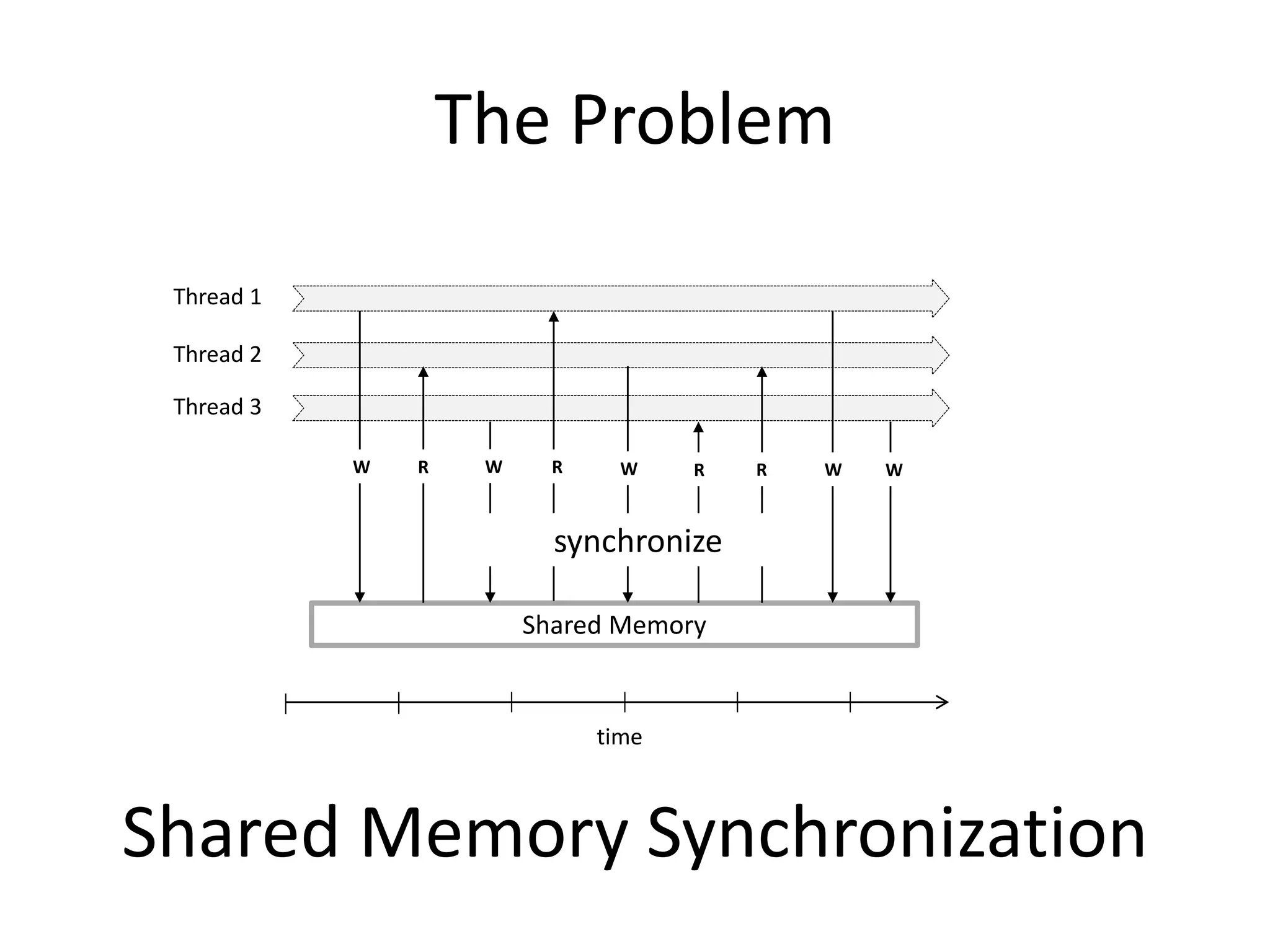
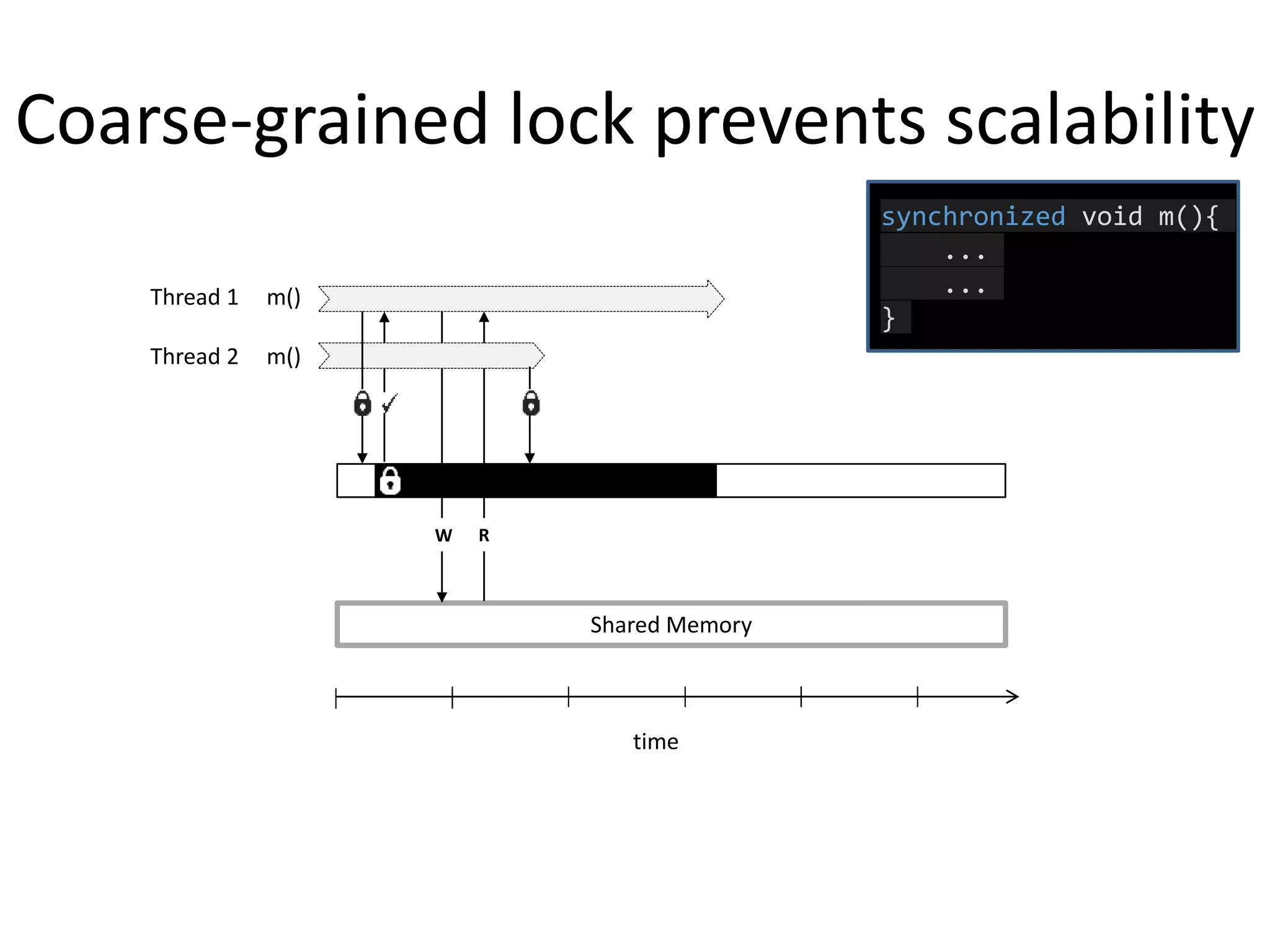
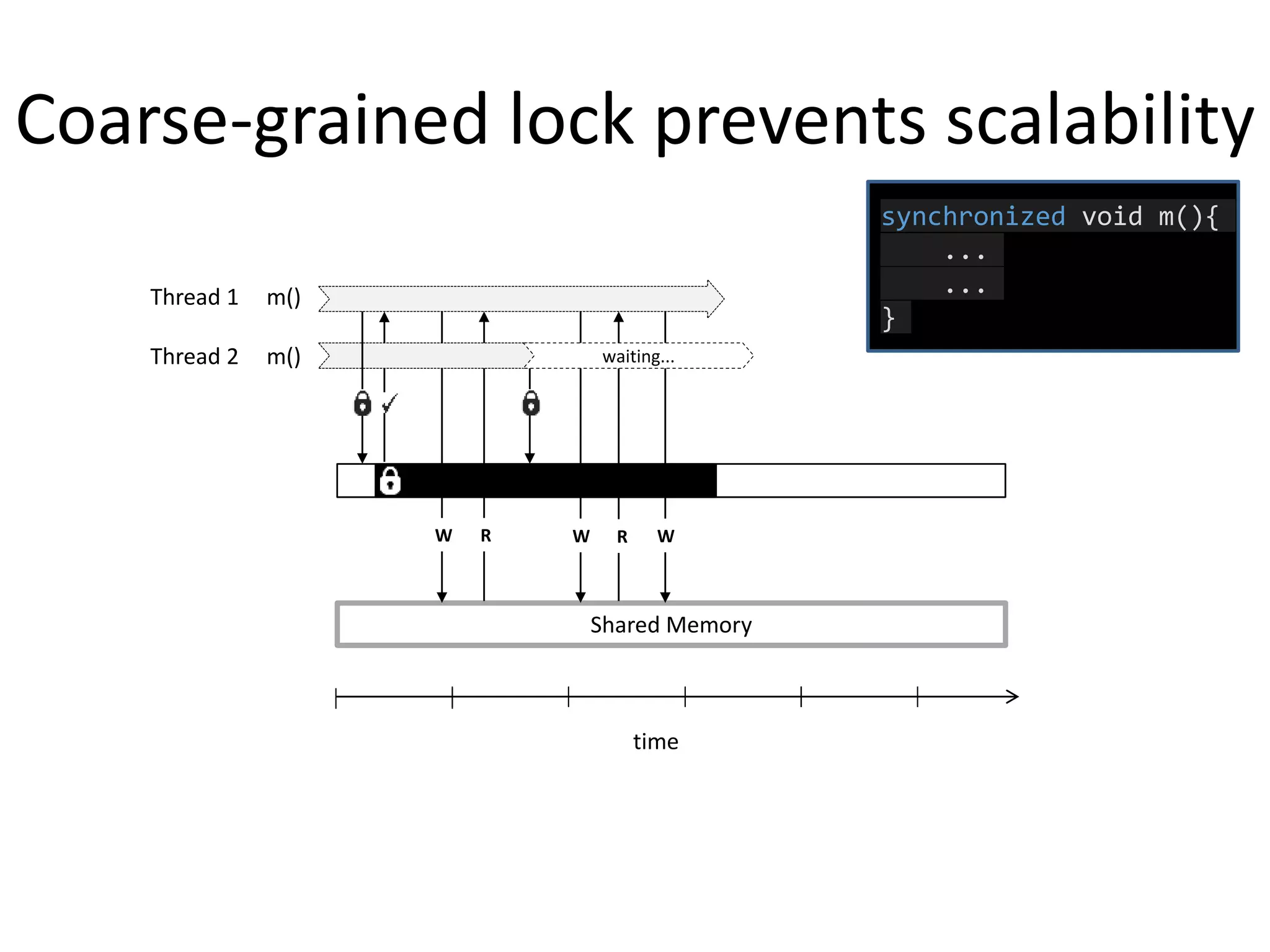
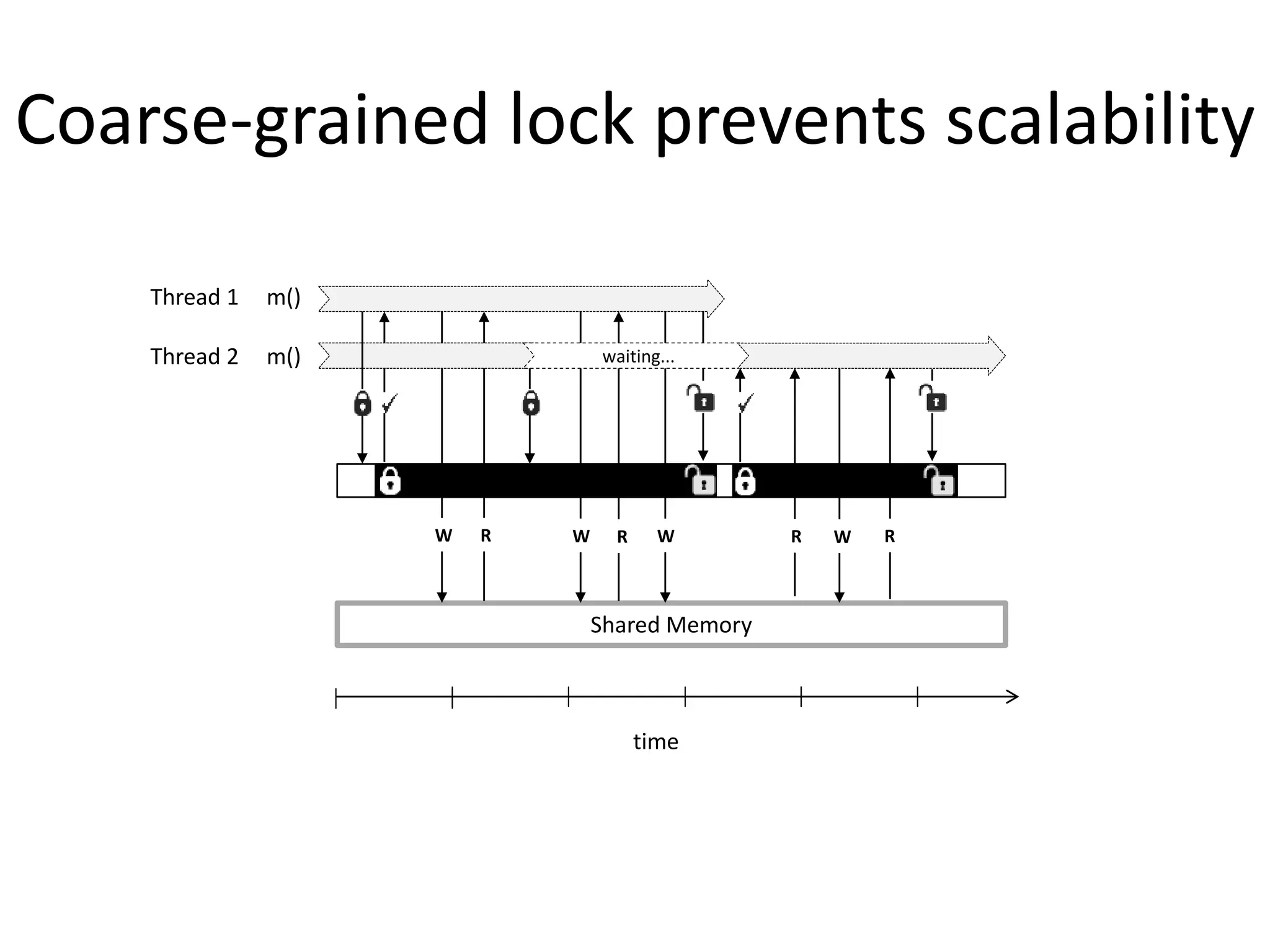
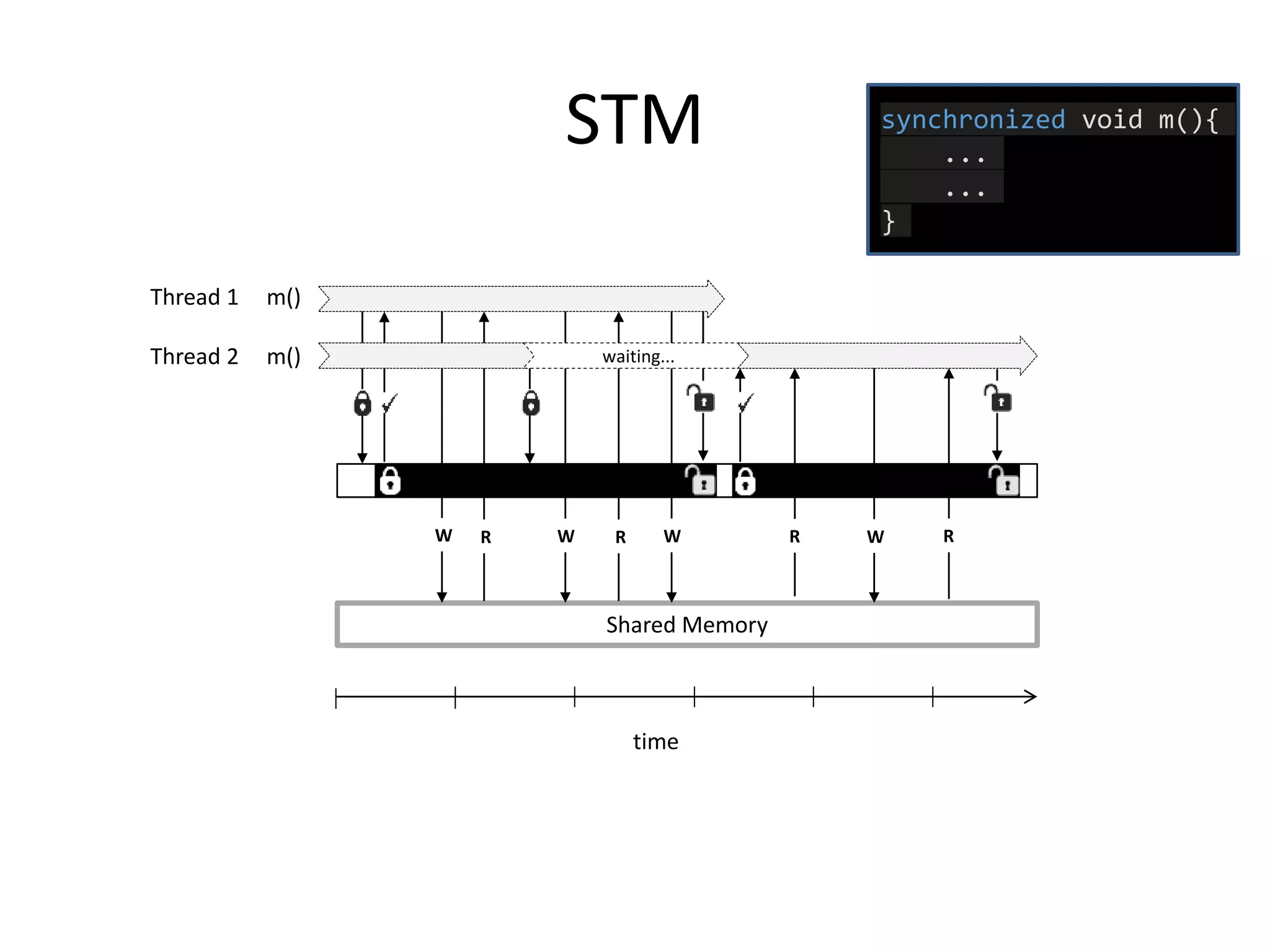
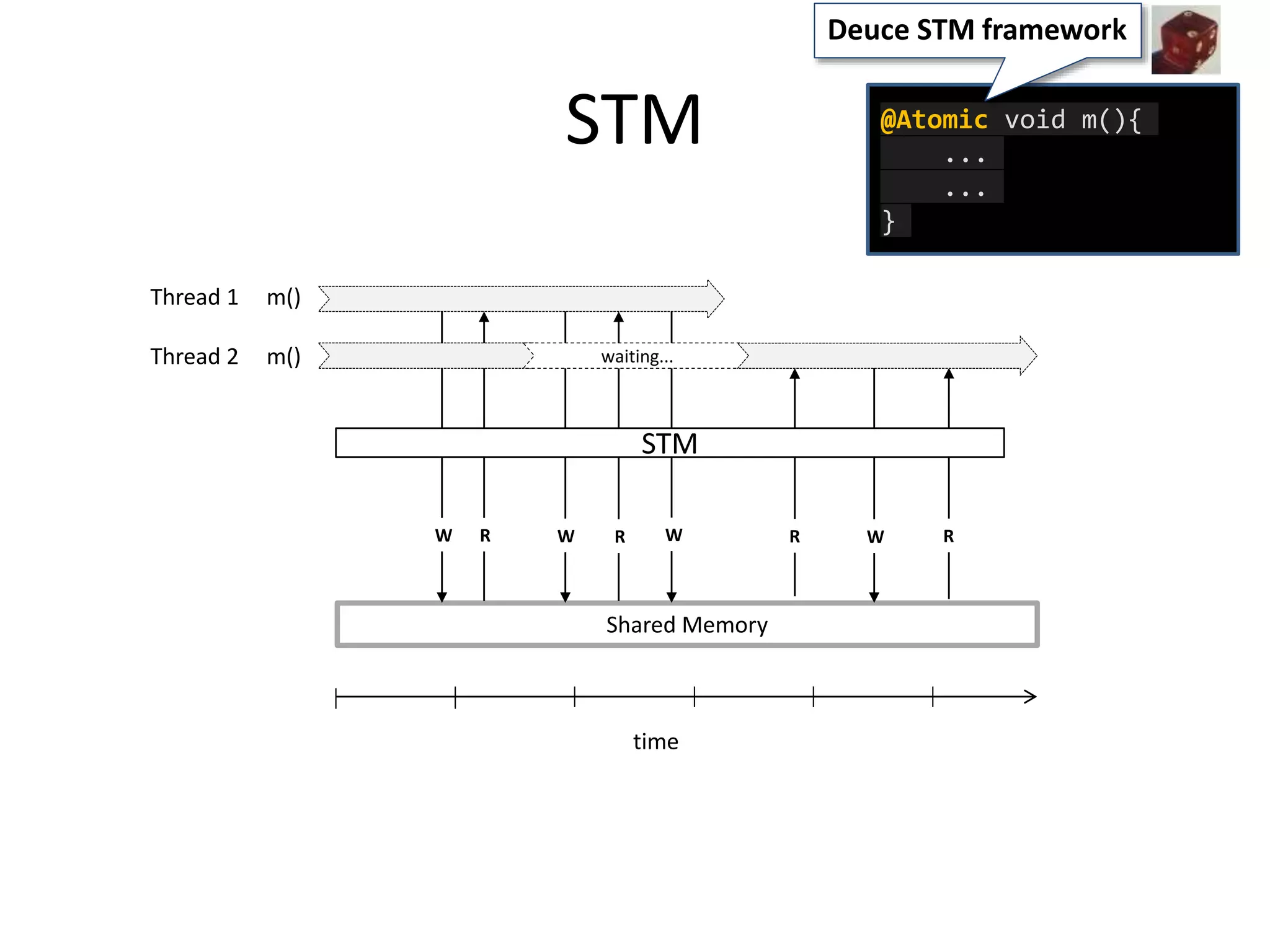
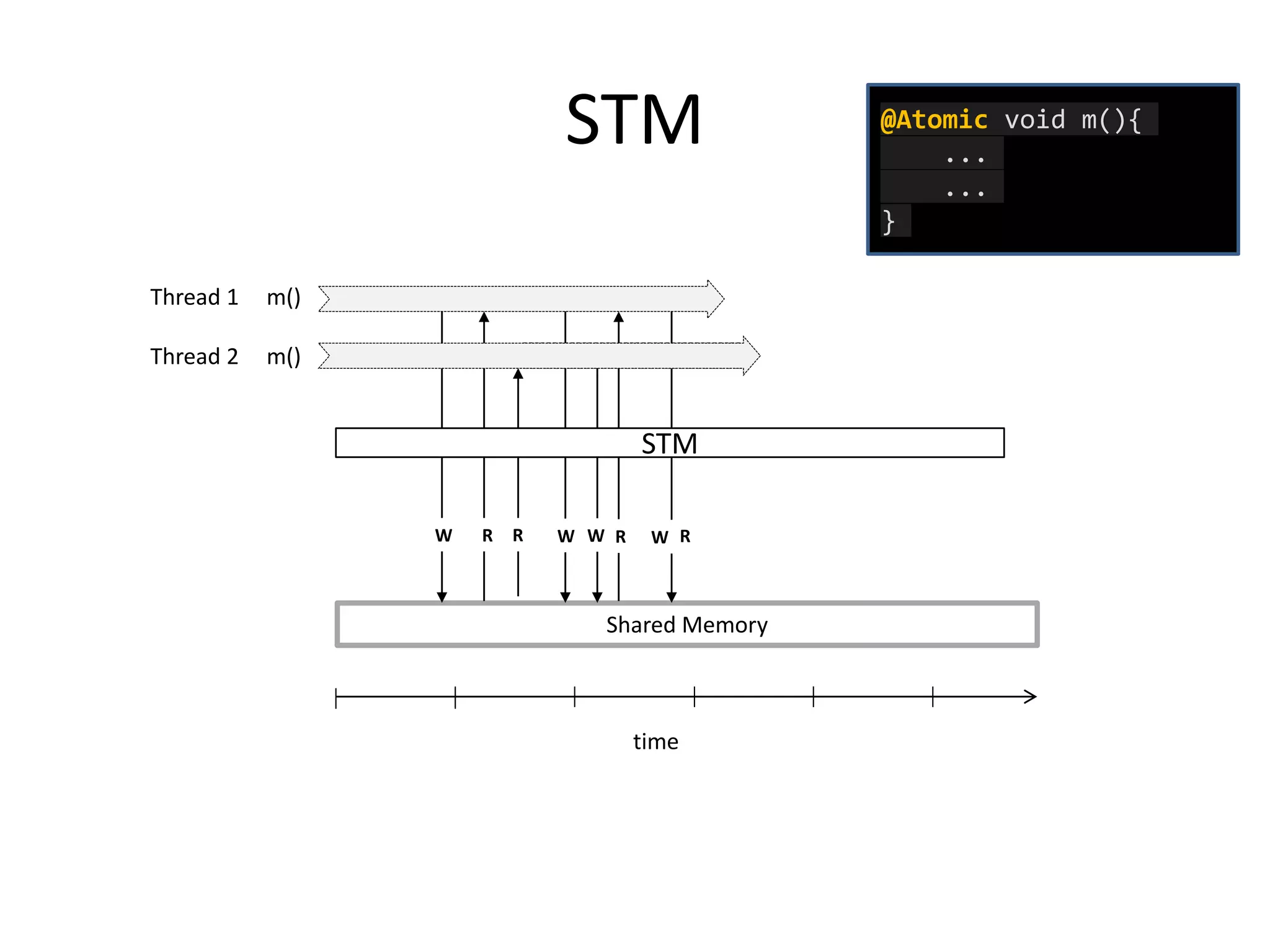
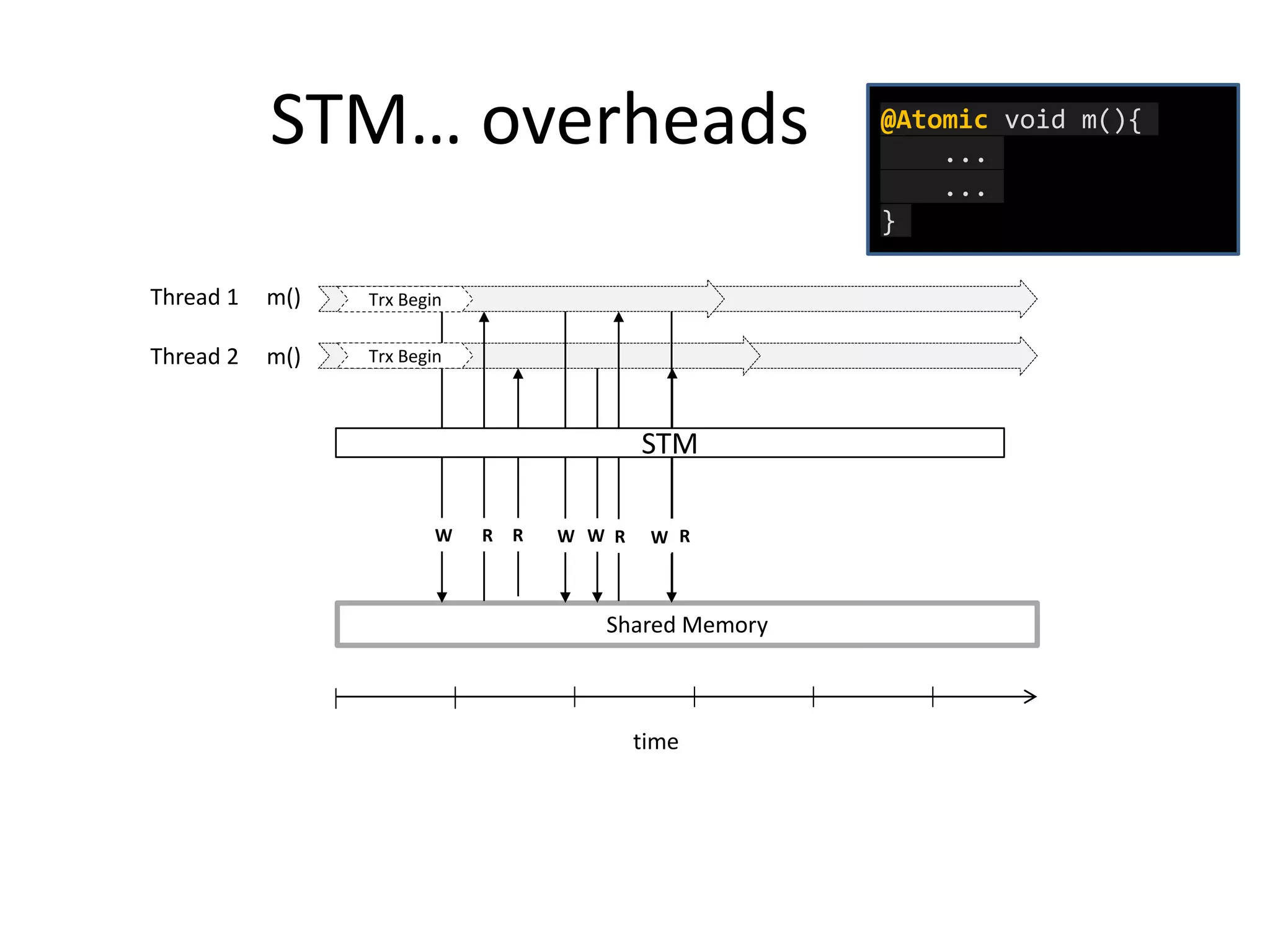
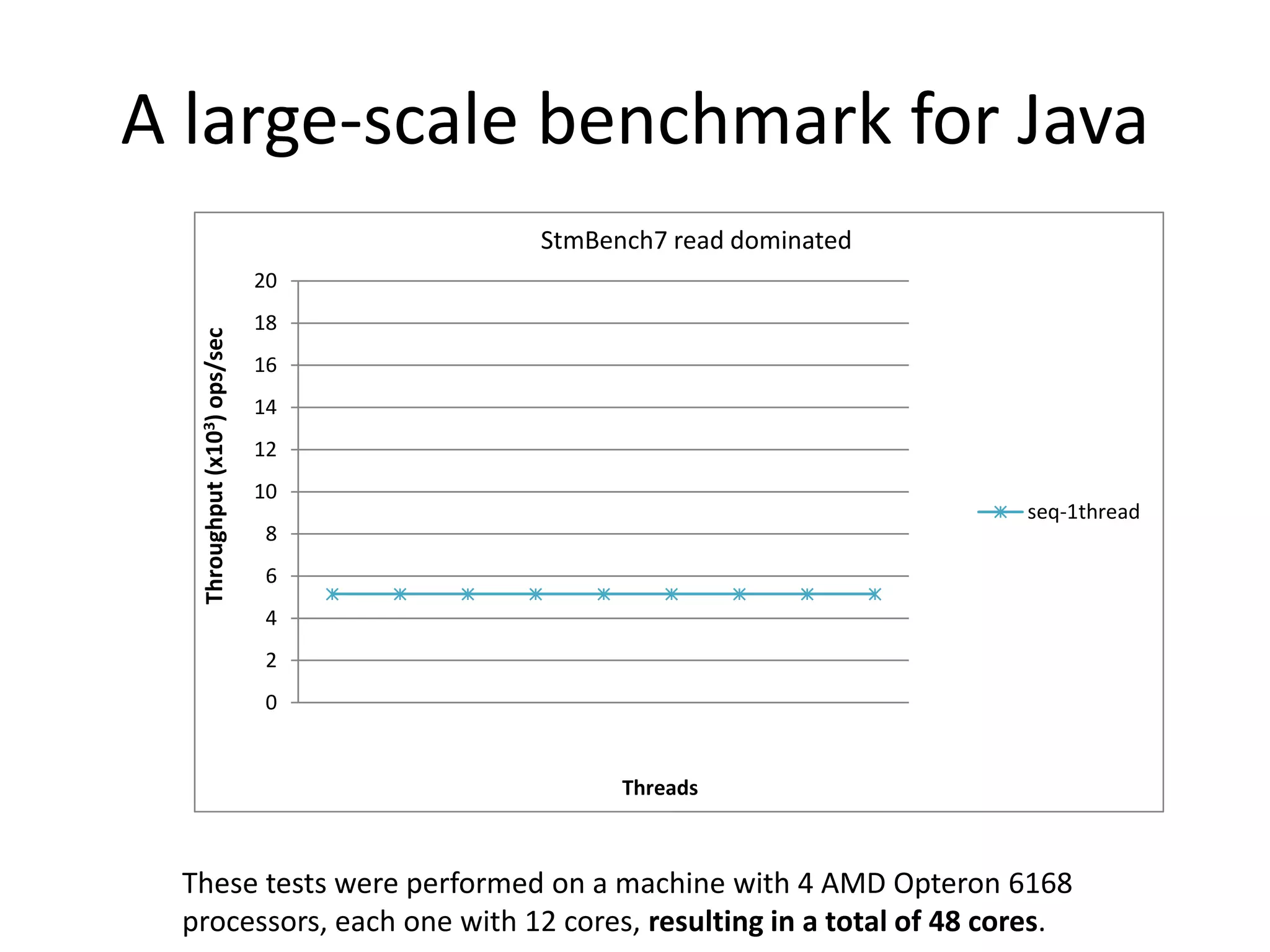
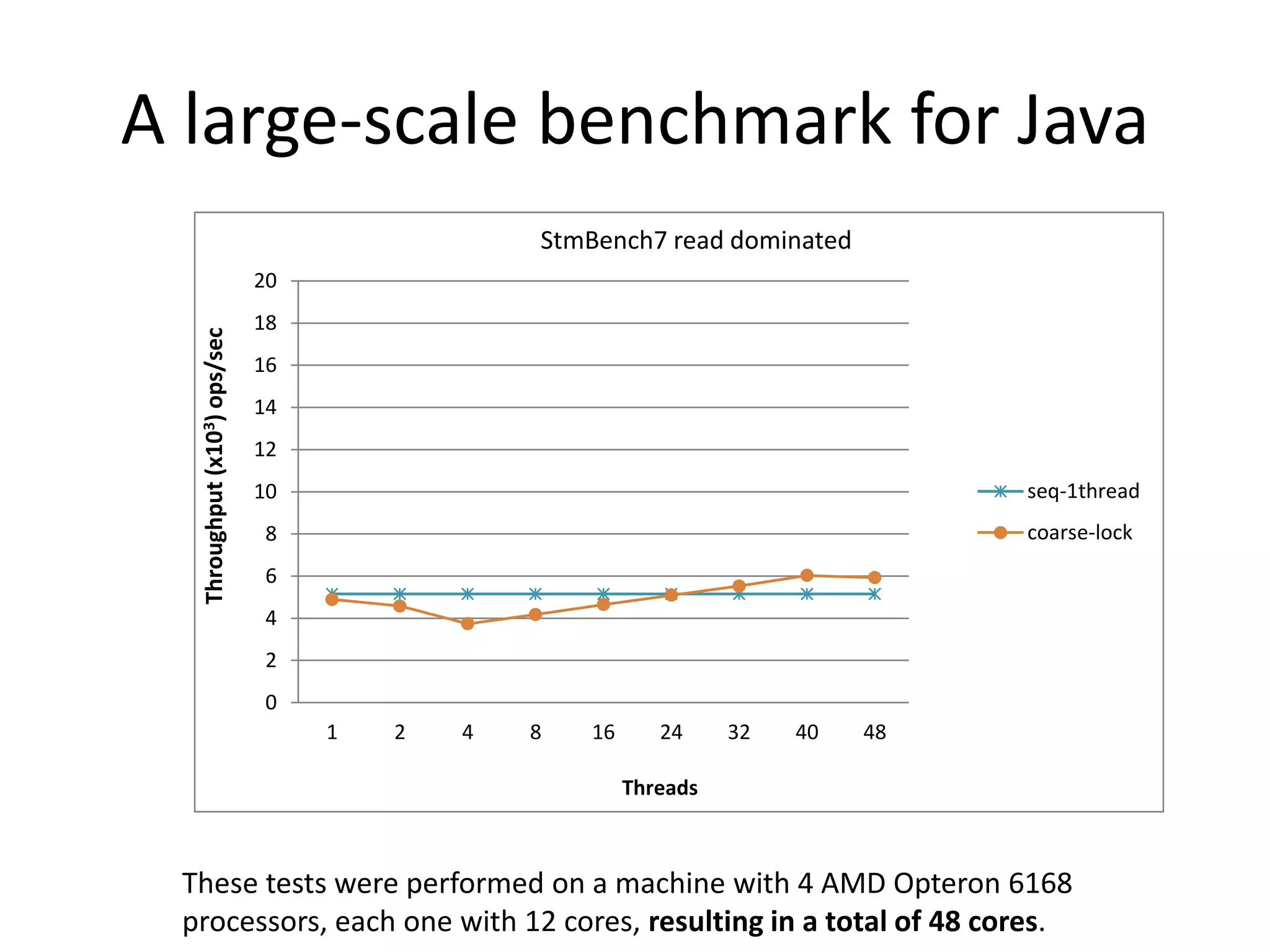
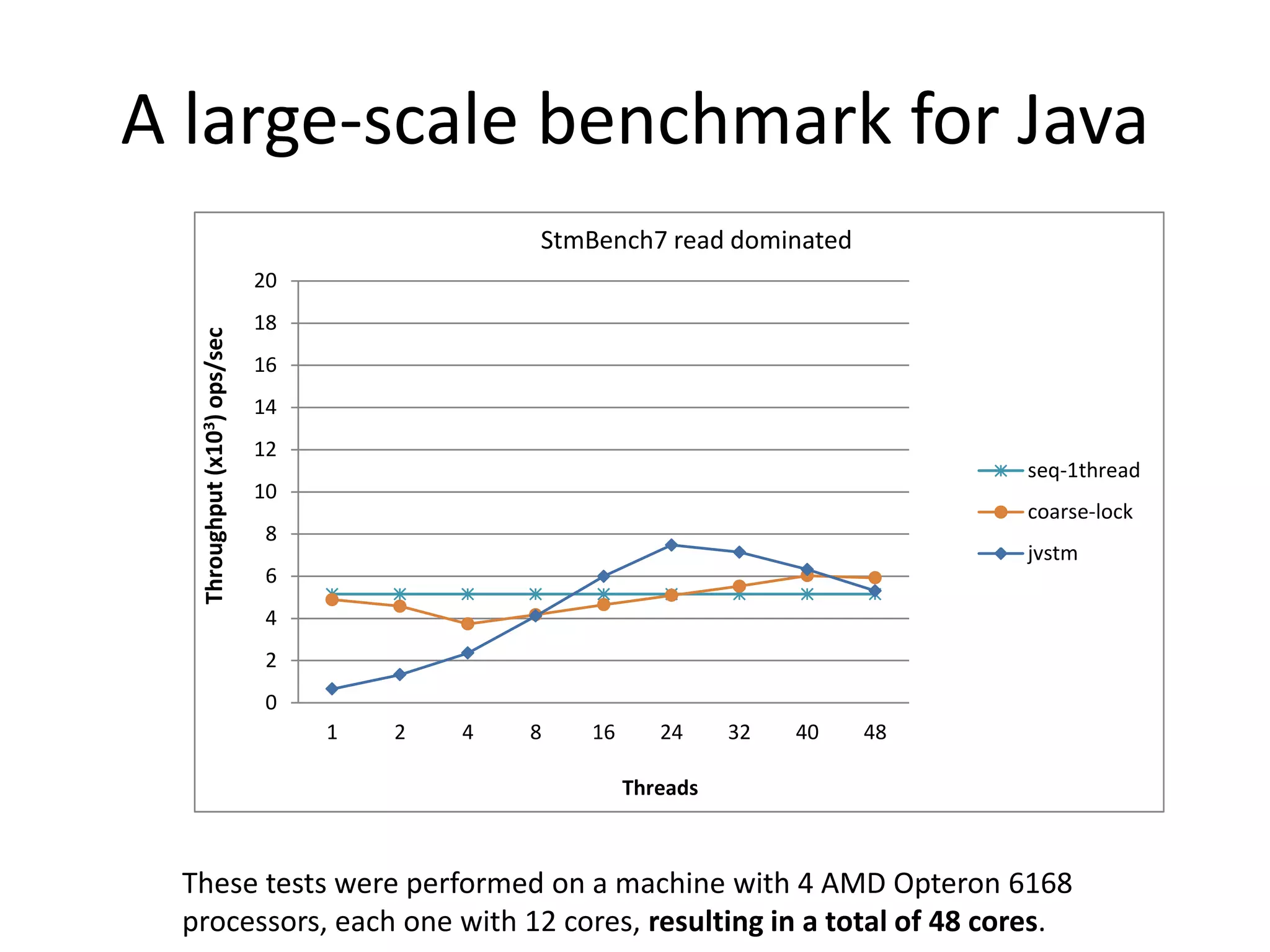
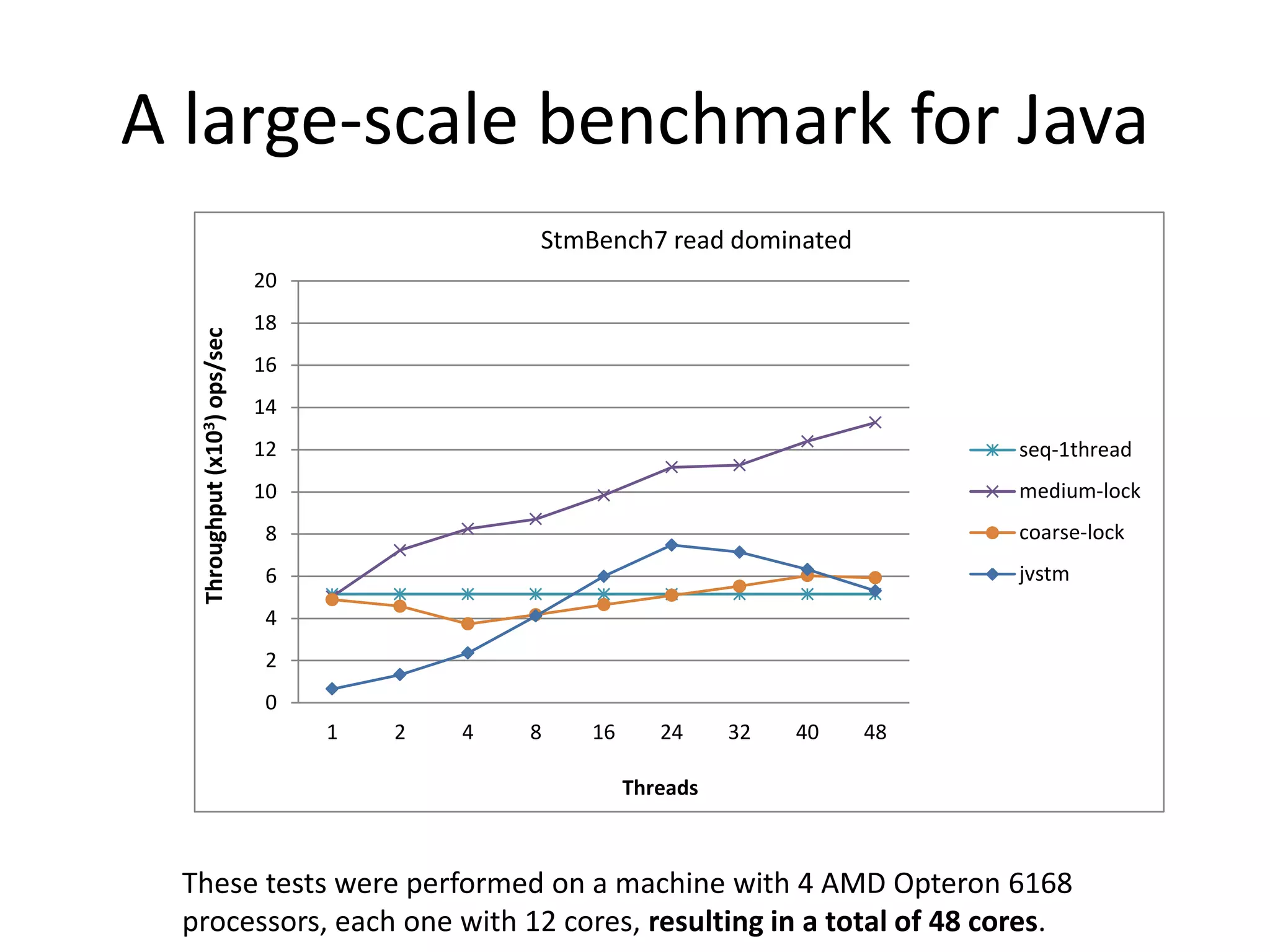
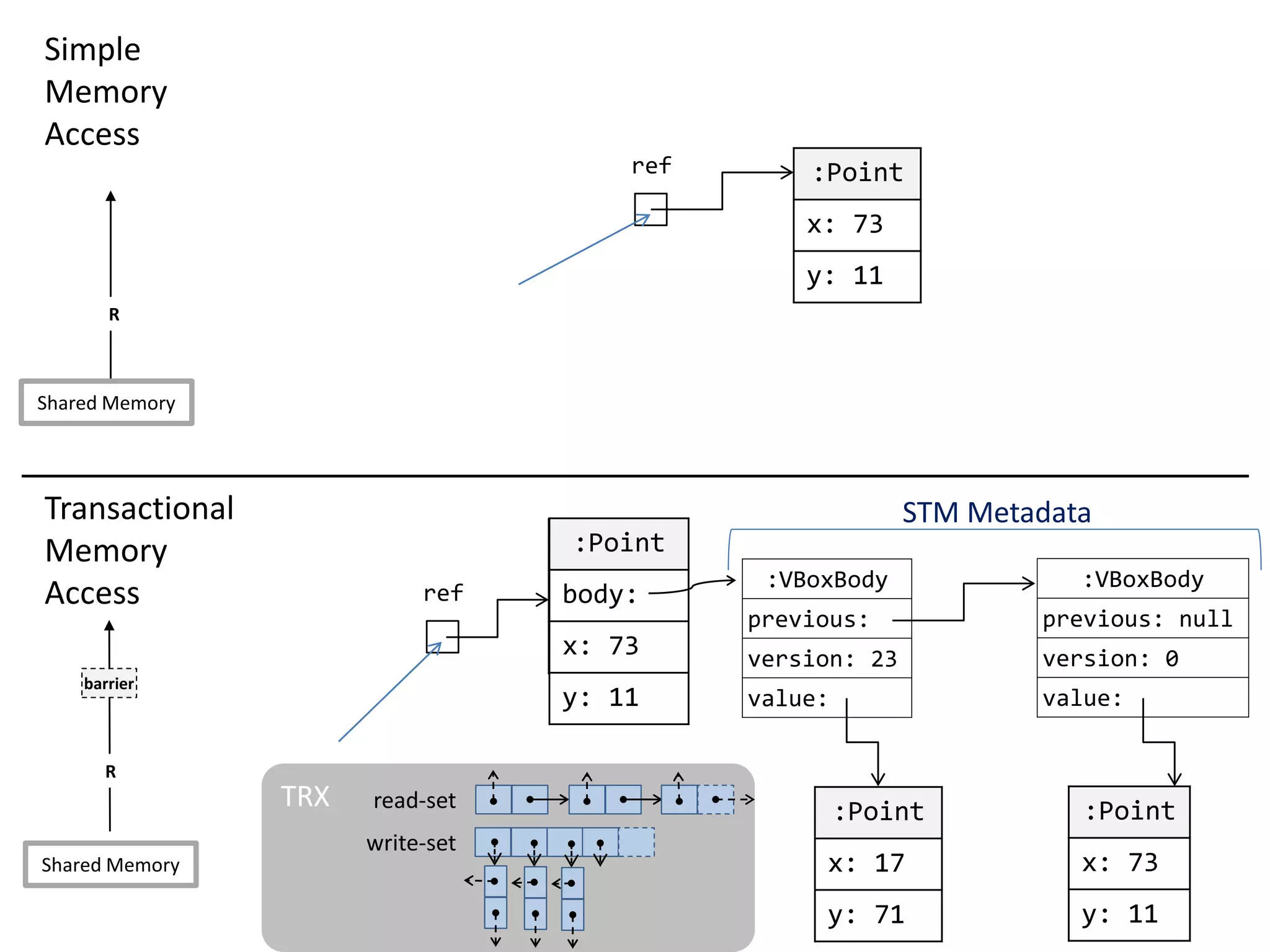
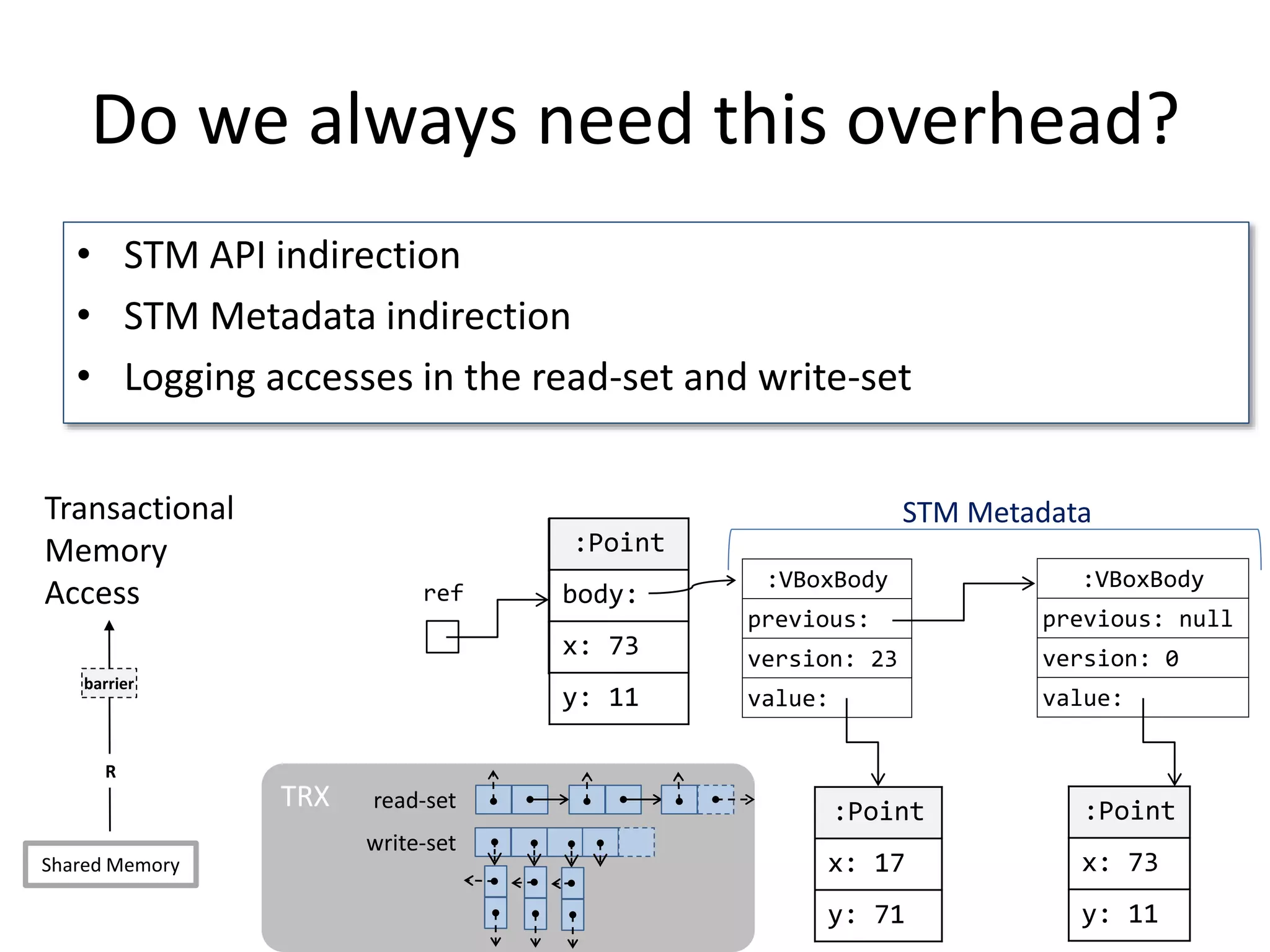
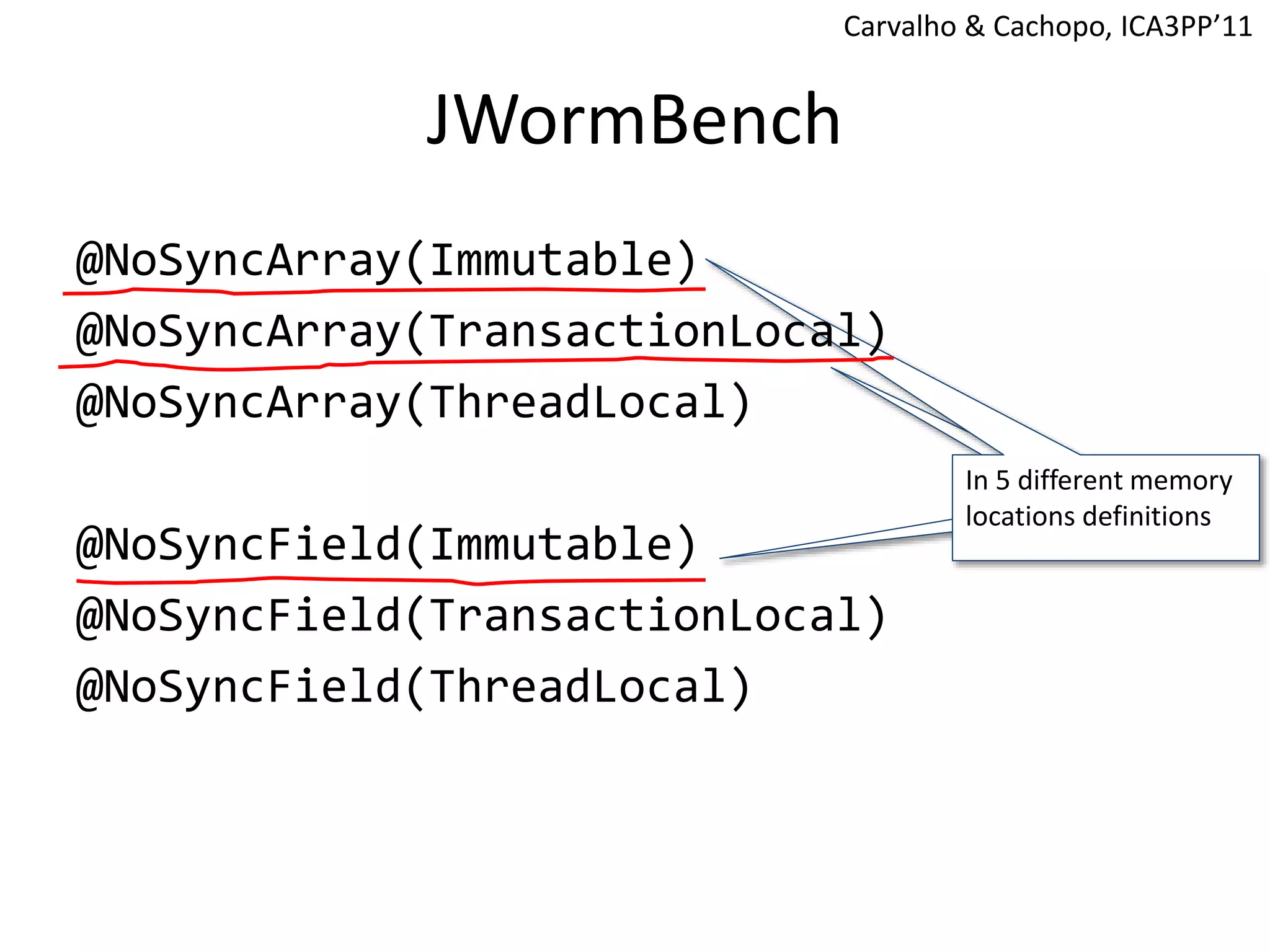
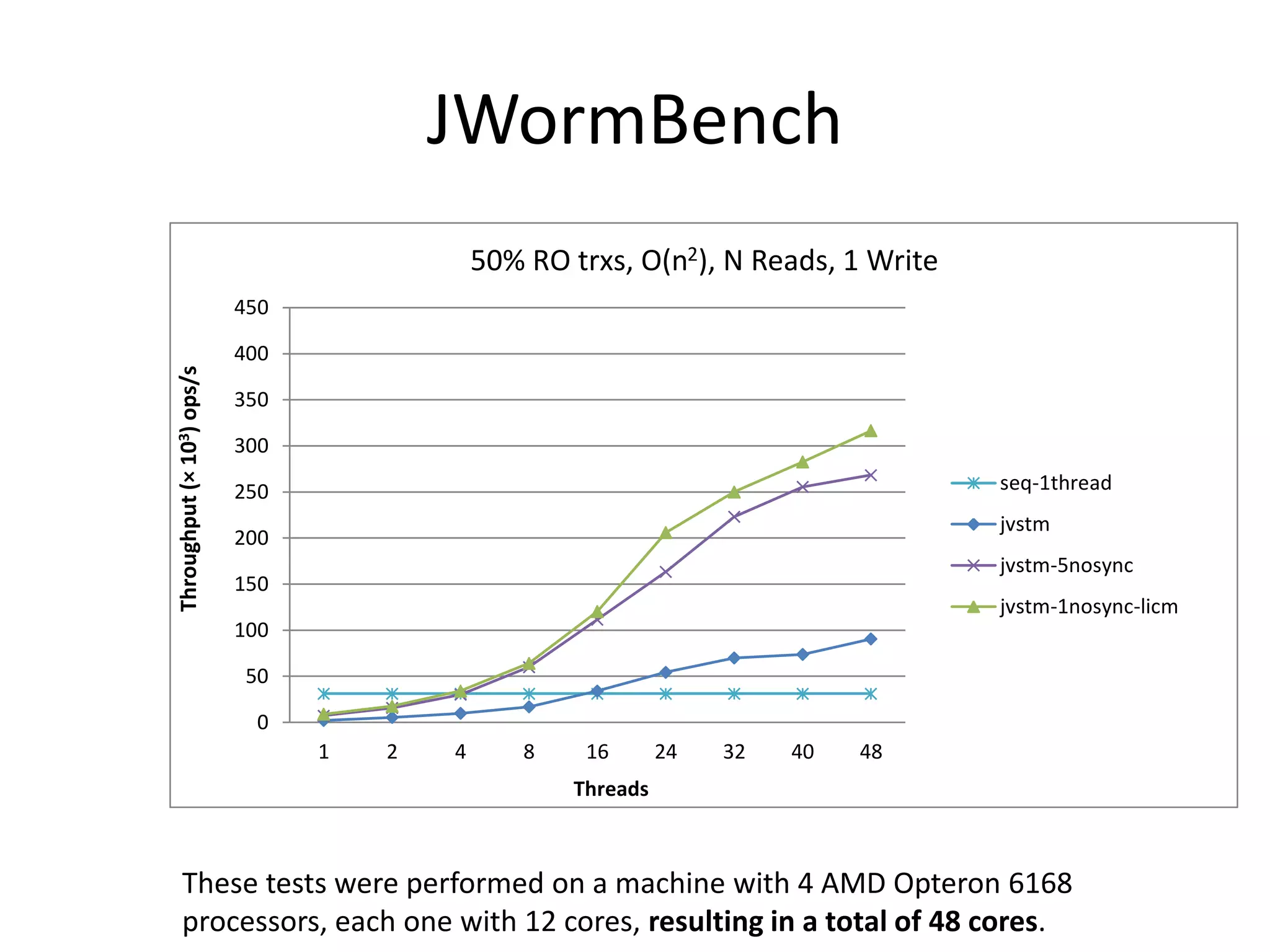
The document discusses optimizing memory transactions in large-scale software, specifically focusing on software transactional memory (STM) techniques to improve performance by reducing synchronization overhead in multi-threaded environments. It highlights various implementations, including a large-scale benchmark with a machine equipped with 48 cores, and explores the efficiency of different locking techniques and STM frameworks. Additionally, the document examines how certain optimizations can alleviate overheads introduced by transactional memory management.













![[Sitcon2018] Analysis and Improvement of IOTA PoW Implementation](https://cdn.slidesharecdn.com/ss_thumbnails/sitcon2018analysisandimprovementofiotapowimplementation-180306085230-thumbnail.jpg?width=640&height=640&fit=bounds)






























![[COSCUP 2022] 腳踏多條船-利用 Coroutine在 Software Transactional Memory上進行動態排程](https://cdn.slidesharecdn.com/ss_thumbnails/random-221018124615-fdcd2429-thumbnail.jpg?width=640&height=640&fit=bounds)






















