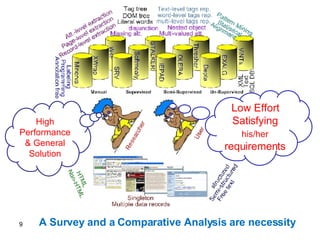
This document outlines a thesis submitted for a Doctor of Philosophy degree focused on information extraction from semi-structured web pages. The thesis contains two main parts: 1) A survey and comparative analysis of existing information extraction systems, analyzing them based on task domain, techniques used, and degree of automation. 2) A new approach called FiVaTech for page-level extraction of web data from template pages without supervision by automatically detecting schemas and templates.













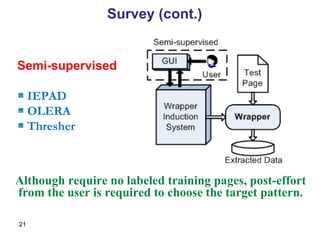






![Tree Template: Encoding 1 We define the encoding for a type and its instance x as: If is of a basic type β, then (T, x) is a node containing x. If is a n-tuple, then T( )=[(S 1 , …,S n+1 ), (i 1 ,…, i n ), (j 1 , …, j n )]. If x = (x 1 , …, x n ), then (T, x) is produced by S 1 i1 (T, x 1 ) j1 S 2 i2 (T, x 2 ) j2 S 3 ... in (T, x n ) jn S n+1 If is a set constructor, then T( )=P. If x = {e 1 , e 2 , ..., e m }, then (T, x) will be the tree by inserting the m subtrees (T, e 1 ), (T, e 2 ), ..., (T, e m ) as siblings at the leaf node on the right most path of P.](https://image.slidesharecdn.com/phd-presentation-2110/85/PhD-Presentation-34-320.jpg)
![T( 1 )= [A], T( 2 )=[ (B 0 C, D 0 E ,F,H, , ,K) (0,0,0,0,0,0), (2,1,0,0,1,6) ], T( 3 )=[ (G, ),0,0 ], T( 4 )=[ (I, ),1,0 ], T( 5 )=[ (J, ),2,0 ], Example for Encoding 1](https://image.slidesharecdn.com/phd-presentation-2110/85/PhD-Presentation-35-320.jpg)
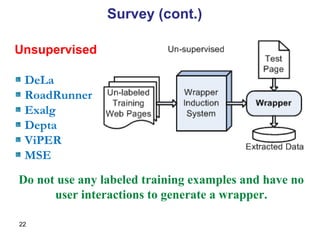
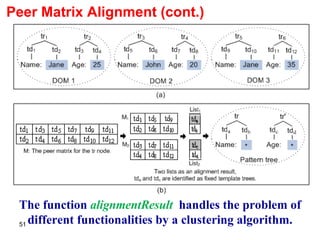
![Tree Template: Encoding 2 If is a n-tuple constructor, then T( )=[(C 1 , …,C n+1 ), (i 1 ,…, i n )]. If x = (x 1 , …, x n ), then (T, x) is the tree produced by inserting the n+1 ordered subtrees C 1 i1 (T, x 1 ), C 2 i2 (T, x 2 ), …, C n in (T, x n ), and C n+1 as siblings at the leaf node on the right most path of a template P. We merge set type with the tuple type and use the tuple template for set as well. Thus, all type constructors have the same template format. We use the name n-order set for this merged template. We define the encoding for a type and its instance x as:](https://image.slidesharecdn.com/phd-presentation-2110/85/PhD-Presentation-36-320.jpg)
![T(w 1 )= [A,(B, ),0], T(w 2 )= [ ,(C,D,K),(0,0)], T(w 3 )= [ ,(E,F, ),(0,0)], T(w 4 )= [ ,( ,H, , ),(0,0,0)], T(w 5 )= [ ,( , , ),(0,0)], T( 3 )= [ ,(G, ),0] T( 4 )= [ ,(I, ),1], T( 5 )= [ ,(J, ),2]. Example for Encoding 2](https://image.slidesharecdn.com/phd-presentation-2110/85/PhD-Presentation-37-320.jpg)


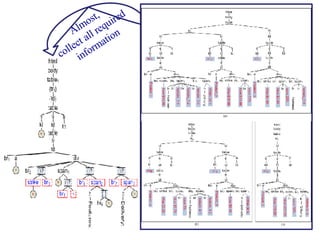


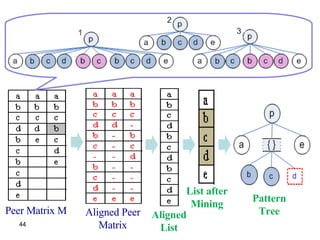


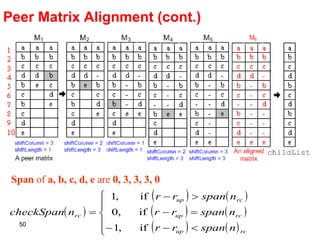
![Peer Matrix Alignment (cont.) R1: Select a node with checkSpan r (n rc ) = -1 ; R2: checkSpan r (n rc ) = 1 and M[r][c]=M[r down ][c′]) . If R 1 and R 2 fail, divide the row into 2 parts: P 1 and P 2 . Span(n rc ) is the maximum number of different nodes (without repetition) between any two consecutive occurrences of n rc in each column c plus one. Shifting a node n rc from M is based on the following rules:](https://image.slidesharecdn.com/phd-presentation-2110/85/PhD-Presentation-49-320.jpg)

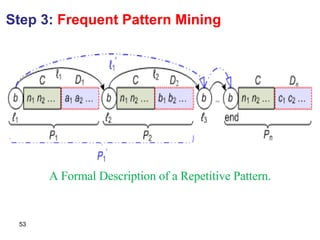

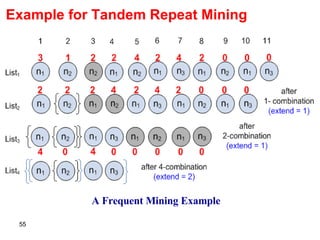


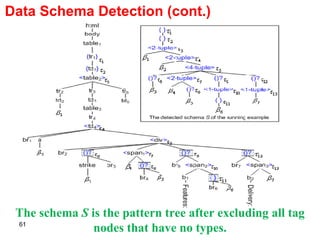
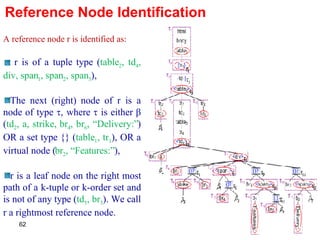
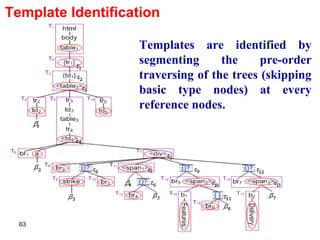
![Data Schema Detection Given a k -tuple or k -order set < 1 , 2 , …, k > at node n, where every type i (1 i k ) is located at a node n i ; [P, (C 1 , C 2 , …, C k+1 )] For template P If is the first data type in the schema tree, then P will be the one containing its reference node, or otherwise. For template C i If i is a tuple type, then the template that includes node n i and the respective insertion position will be 0. If i is of set type or basic type, then C i will be the template that is under n and includes the reference node of n i or if no such templates exist. If C i is not null, the respective insertion position will be the distance of n i to the rightmost path of C i . Template C k+1 will be the one that has the rightmost reference node inside n or otherwise.](https://image.slidesharecdn.com/phd-presentation-2110/85/PhD-Presentation-64-320.jpg)
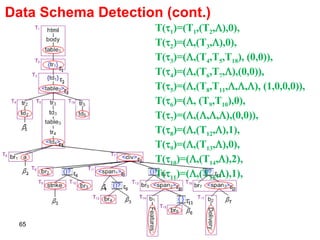

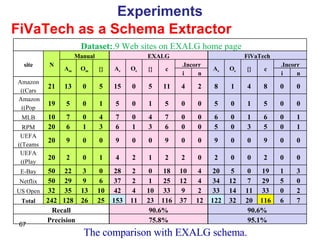

![FiVaTech As a SRR Extractor Experiments (cont.) Data set: 11 Web site from Testbed Ver. 1.02. Step 1: SRRs Extraction Step 1: Alignment #Actual SRRs: 419 #Actual attributes: 92 Depta FiVaTech Depta FiVaTech #Extracted 248 409 93 91 #Correct 226 401 45 82 Recall 53.9% 95.7% 48.9% 89.1% Precision 91.1% 98.0% 48.4% 90.1% Dataset TBDW MSE [55] #Actual SRRs 693 1242 System ViPER FiVaTech MSE FiVaTech #Extracted 686 690 1281 1260 #Correct 676 672 1193 1186 Recall 97.6% 97.0% 96.1% 95.5% Precision 98.5% 97.4% 93.1% 94.1%](https://image.slidesharecdn.com/phd-presentation-2110/85/PhD-Presentation-69-320.jpg)



















































































